

How to Increase HPC Performance While Reducing Costs and Lowering Energy Consumption
High performance computing is now a cornerstone to modern research and engineering. Organizations throughout industries are turning to digital modeling and simulations to shorten product development cycles. Particularly in engineering, electronic design automation (EDA) and the rapid expansion of the Industrial Internet of Things (IIoT) are driving HPC demand.
As companies turn to HPC for increasingly complex simulations and other tasks, they must also continue to control costs and reduce energy consumption.
What Is High Performance Computing (HPC)?
Compared to general-purpose computing, HPC offers greater throughput to process complex computational problems at extremely high speeds. HPC systems include three primary components: compute, network, and storage. They aggregate computing power through massively parallel processing.
HPC clusters consist of a large number of servers connected in a network. Each component computer is considered a “node.” HPC systems often contain 16 to 64 nodes with two CPUs per node.
The need for high performance computing is driven by today’s increasingly sophisticated software and the massive data sets used in simulations and analysis. This software is used to improve product performance in diverse disciplines, including aircraft aerodynamics, autonomous driving, drug discovery, and weather modeling. For example, simulation software applications from Ansys, Siemens, Dassault, and Convergent Science rely on specialized HPC architectures to perform computational fluid dynamics for commercial planes, military aircraft, and spacecraft development.R&D organizations also typically maintain broad portfolios of applications, including commercial, open source, and those with home-grown codes. Ensuring they run efficiently on HPC infrastructure is a challenge, because they all have different needs. At the same time, the independent software vendor (ISV) landscape continues to expand, further complicating how organizations need to support the use of advanced R&D software.
Specialized HPC Clusters
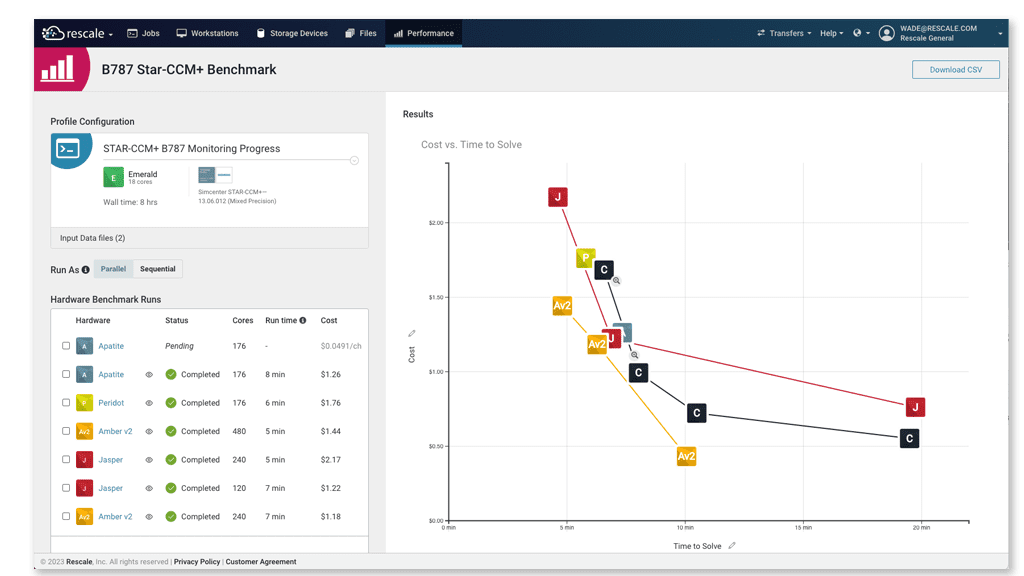
HPC takes advantage of specialized HPC clusters to optimize workflows for specific kinds of applications and workloads.
Some tasks require more communication between nodes, as well as specialized hardware and software. A given workload’s computational requirements determine the number of nodes needed in the cluster. Some software and computational tasks also perform better with certain kinds of semiconductor chips. An automated benchmarking assessment tool like Rescale Performance Profiles can be incredibly helpful in matching the best chip architecture to a given computing task.
A high-performance interconnect for clusters addresses the need for low latency and bandwidth. It tracks the workload and re-routes it as necessary. One way to deal with large data sets is to package HPC applications and run them across multiple clusters. A cluster manager runs capacity and health checks to find and use available resources.
Containerization
Some organizations are also addressing HPC workload management with GPU-optimized containers, which have become increasingly prevalent with AI deployments. Open-source Apptainer (Singularity) is the most widely used container system for HPC. Shifter and Docker are other options. They allow for the seamless integration of leading AI applications. Containerized applications increase portability, making possible the use of in-house and commercial applications from anywhere.
Virtualization is an alternative to containerization. It generates a virtual environment on top of the host operating system. Virtual machines (VMs) are programmed with their own operating systems, allowing for complete isolation from one to another. Hyper-V, vSphere, and OpenStack are some examples.
Why is HPC Important?
HPC delivers critical information and analysis in far less time than traditional computing. The speed of HPC provides benefits to many roles, from engineers and data scientists to product designers and researchers.
It also takes modeling and simulation (M&S) to an entirely new level. For example, higher-resolution models deliver more granular information about a new product, which then reduces or eliminates the need for prototypes and real-world testing. Think automotive crash simulations rather than actual crash tests, or training pilots on flight simulators rather than in real aircraft.
With cloud HPC, a wide array of enterprises can rapidly scale their computing needs on demand.
Some examples are:
- Engineering firms
- Research labs
- Financial technology (fintech)
- Product development
- Government and defense
Even startups and small businesses can take advantage of highly scalable cloud HPC.
Understanding HPC Performance
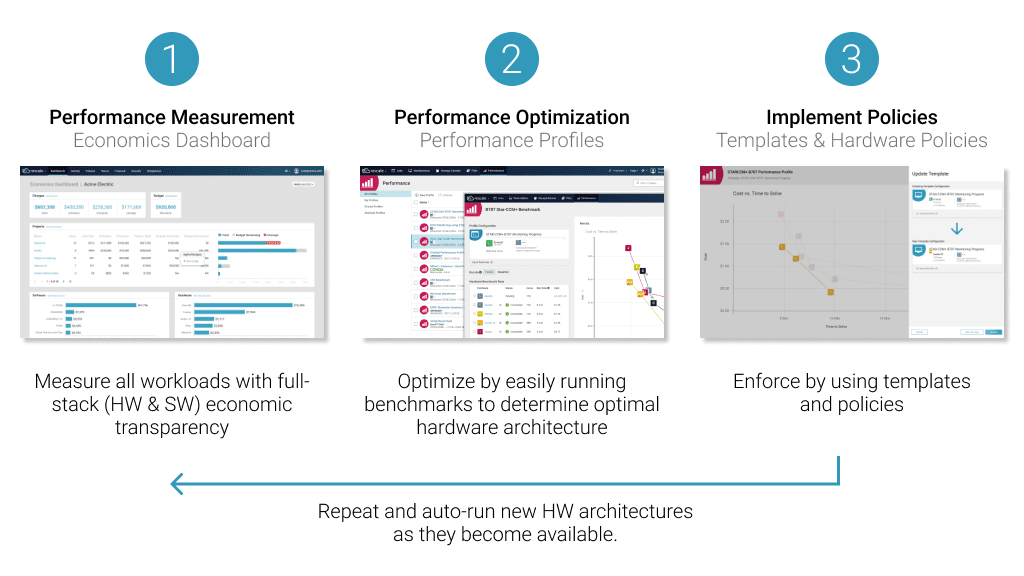
HPC optimization addresses the complexities of providing the right computing architecture for a given workload. It is also essential in making systems more energy efficient. An HPC workload is a data-intensive task spread across system resources located on-premises or in the cloud.
Today’s HPC systems can handle incredible workloads, including AI, machine learning, and deep learning. They run millions of scenarios simultaneously while processing massive amounts of data.
Key Performance Metrics
Analysts measure the power of HPC systems in flops per second. Right now, the Frontier machine at Oak Ridge National Laboratory sits atop the TOP500 list of the most powerful supercomputers, delivering 1.102 Eflop/s (one exaflop is one quintillion calculations).
Another key metric is power usage effectiveness (PUE), which determines the energy efficiency of the entire data center. You can calculate the PUE by dividing the total power entering a data center by the power used to operate all the IT equipment. The closer the number is to 1.0, the better the overall efficiency. Another benchmarking standard is data center infrastructure efficiency (DCiE). This energy efficiency metric is calculated by dividing IT equipment power by total facility power.
Finally, metrics are important, but only up to a point. Ultimately, users care most about the real-world performance that helps their computational jobs run faster. It can be difficult to fully assess HPC performance for all types of software and workloads. Some types of semiconductor chips work better on certain types of software than on others.
Computational Bottlenecks
For some companies, on-premises infrastructure is itself a bottleneck. This type of infrastructure investment is typically calculated for 100% utilization, so the instant demand exceeds supply, there’s a bottleneck because there is no more capacity. By comparison, cloud HPC is elastic, scaling up and down as needs change. Organizations can simply subscribe for more compute power. As a result, HPC in the cloud delivers full utilization without running into the constraints of capped capacity.
Many other potential bottlenecks exist within HPC systems, including memory capacity, I/O throughput, and storage speed/capacity. CPU cores, clock speed, or caching may also limit performance, while other inhibitors might include network switch bandwidth.
Memory capacity is another issue, as higher data transfer rates mean more memory required for buffering and storage. Traditional DDR3, DDR4, and even DDR5 memory may become a bottleneck. However, high-bandwidth memory (HBM) is a possible solution, as it delivers eight times the bandwidth of DDR5 memory.
To avoid bottlenecks, it is also important to align software specifications with HPC configurations that optimize performance.
HPC Energy Efficiency
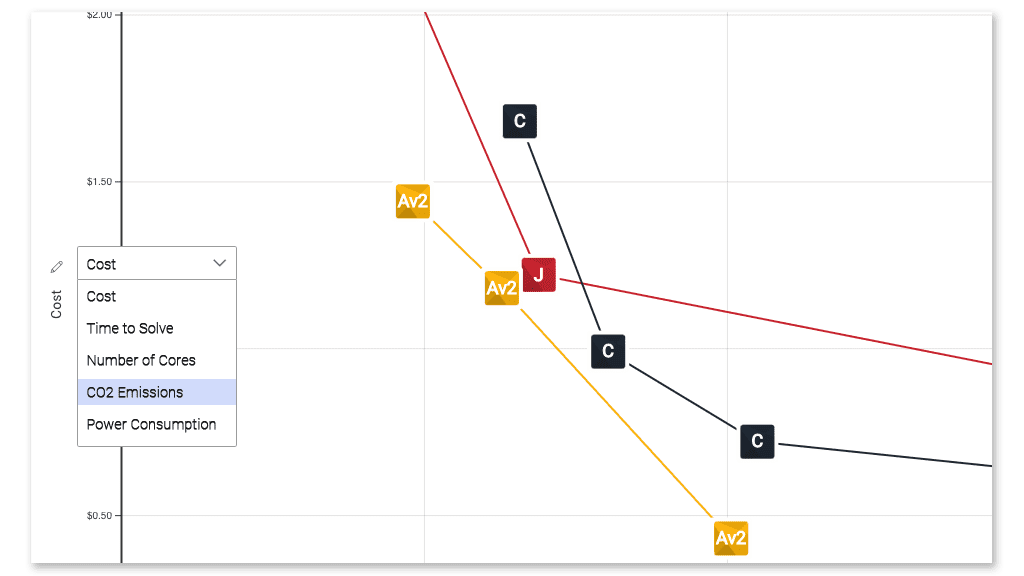
The energy efficiency of HPC systems, measured in flops per watt, continues to improve. One example of this is the Henri system at the Flatiron Institute in New York City, with an efficiency score of 65.09 GFlops/Watts.
Data center operators continue to improve energy efficiency in diverse ways. For example, next-gen, low-power chipsets reduce energy consumption and are better at dissipating heat. Power-optimized IP cores also reduce energy use and data transport via high-bandwidth memory. Some operators have turned to alternative sustainability methods, like liquid cooling and heat recycling.
Data centers increasingly look to renewable energy sources like hydro, wind, solar, biomass, and green hydrogen. Significant progress is being made, as evidenced by the fact that data center power consumption leveled off at 191 terawatt hours between 2015 to 2021. However, one-time migrations from on-premises data centers somewhat masked overall growth in HPC demand.
Responding to HPC Computing Demand
To meet demand, the industry is responding with more powerful machines than ever. Systems are moving from petaflop to exaflop capacity and beyond. A supercomputer with exaflop capability requires one second to perform one quintillion calculations. It would take more than 31 billion years to complete that number of calculations at just one calculation per second.
Innovations to expand HPC efficiency include new architectures and hardware. For example, 3DIC and die-to-die connectivity address the latest performance requirements. And more flexible switching is possible when FPGA, GPU, CPU, and other processing architectures are integrated into a single node.
New hardware often favors cloud-based HPC. Accordingly, legacy on-premises data centers cannot always take advantage of more energy-efficient chipsets. Migration to the cloud is one way to effectively address the increasing demand for speed, scalability, and sustainability.
However, a simple “lift and shift” migration from on-premises to the cloud does not always address a company’s emerging HPC needs. Sometimes legacy infrastructure can’t cope with the changing business needs, as it is typically a four to five-year refresh cycle. Such a lengthy cycle cannot keep up with rapid changes in the HPC ecosystem. Cloud adoption also offers a relatively high degree of financial flexibility. Corporate HPC cost models transition from longer-term CapEx to shorter-term OpEx. They don’t tie up as much capital, and they can better match different cloud HPC cost models to current needs.
Key Takeaways
For those with on-premises data centers, migration to the cloud is an important way to increase energy efficiency while reducing costs. Cloud HPC offers businesses of all sizes a way to benefit from the latest technological advances.
Optimizing HPC performance requires alignment between software specs and available hardware. Plus, specialized HPC clusters and containerization can also increase HPC performance and energy efficiency.
As the use of AI proliferates, HPC systems will become even more energy efficient.
Learn More From Rescale
Discover how Rescale can help your organization control costs while powering greater innovation. With Performance Profiles, it is easy to identify the best cloud HPC architecture for your needs.
Learn more in our on-demand webinar “Optimize Workload Cost and Performance in the Cloud.”






