Lightweight Azure InfiniBand Cluster Setup

One of the key criticisms leveled against HPC in the cloud is the relatively slow interconnect speed between nodes when compared to on-premise clusters. While a number of niche providers offer InfiniBand connectivity to address this gap, Microsoft is the first major provider to offer this type of high-bandwidth, low-latency interconnect with its new Big Compute solution. This is exciting news because there are relatively few companies that have the resources necessary to manage data centers on a large scale while also dealing with the security compliance issues and certifications needed for enterprises to move their workloads over to the cloud. Fair or not, having the backing of a Microsoft, Amazon, or Google can make a big difference in obtaining corporate IT buy-in.
According to specs, the new A8 and A9 instance sizes provide InfiniBand connectivity with RDMA. This last bit is especially important because, as this blog post correctly points out, having InfiniBand alone is not enough. The transport being used makes a critical difference and TCP performs very poorly. The Big Compute instances support virtualized RDMA that provide near bare metal performance according to Microsoft. This announcement should be a boon for users looking to run tightly coupled simulations in the cloud. This type of “chatty” MPI application is highly sensitive to the latency of the underlying network. However, after taking the platform out for a spin, I think there are a few barriers to entry in its current incarnation.
First, the RDMA capabilities are exposed through an interface called Network Direct which is currently only supported by MS-MPI–Microsoft’s MPI implementation. Applications will need to be recompiled against these libraries. This is not too big of a hurdle since MPI is a well-defined standard and MS-MPI is based on MPICH, which is widely supported. A bigger issue, however, is that applications will need to be written to run on Windows. Thankfully, many of the popular engineering applications being used today already have Windows versions that support MS-MPI. Anecdotally at least, it seems like applications can be recompiled with little effort.
Second, configuring an MPI cluster is very different in the Windows world compared to Linux. While Windows is certainly capable of putting up impressive MPI benchmark numbers, the vast majority of HPC practitioners are currently running on Linux. Configuring an MPI cluster in the cloud for Linux generally boils down to: “Launch your instances, use the package manager to install the MPI flavor of your choosing, set up passwordless SSH amongst all the nodes in your cluster, and create a machinefile”. On Windows, the recommended approach is to install and configure HPC Pack on a Windows Server box (either on premise or in the cloud). This can be difficult for someone familiar with Linux and not versed in the nuances of Windows server administration. While the HPC Pack solution is robust and full-featured, it does feel a bit heavyweight if you just want to run a few benchmarks or a simple one-off simulation. What would be nice is a tool like Starcluster to get people up and running as quickly as possible without having to configure Active Directory, install SQL Server, or figure out Powershell and REST APIs.
It turns out that you can install MS-MPI on Azure without HPC Pack but there doesn’t seem to be a lot of guidance out there on how to do this. Further, there are a number of SSH servers and UNIX utilities that have been ported to Windows. We wanted an easier way to launch an MPI cluster in Windows without having to install, configure, and manage a separate HPC Pack instance. What we ended up experimenting with was using the PaaS offering to deploy a Cloud Service containing a set of startup tasks to perform the following operations on each node:
- Install MS-MPI (a standalone installer is available here)
- Launch SMPD
- Install and configure an OpenSSH server and a standard set of UNIX command line utilities
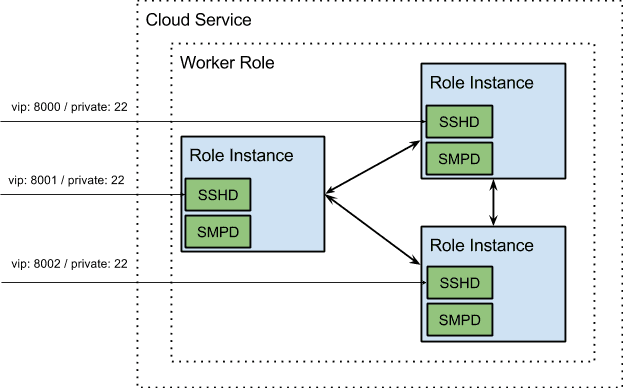
Each Cloud Service has a single virtual IP (VIP) assigned to it. To work around this, we used Instance Internal Endpoints to allow users to SSH into individual nodes using different ports. Internal Endpoints are opened up so that each Role Instance can connect to the SMPD daemon running on the others. The end result of all this is an easy to deploy .cspkg file and accompanying configuration xml. Users can SSH into Role Instances and use the UNIX commands that they know and are familiar with.
We wanted to run a couple of latency and bandwidth benchmarks against 2 A9 instances. First, we recompiled the osu_latency and osu_bibw benchmarks from the OSU Microbenchmark library against MS-MPI. Then, we deployed the Cloud Service above, copied the benchmark executable to each machine with SCP (note that SCP is not a viable solution if you have large files that need to be moved around but it works fine for smaller files like these benchmark executables). Finally, we SSHed into one of the nodes and launched the executables:
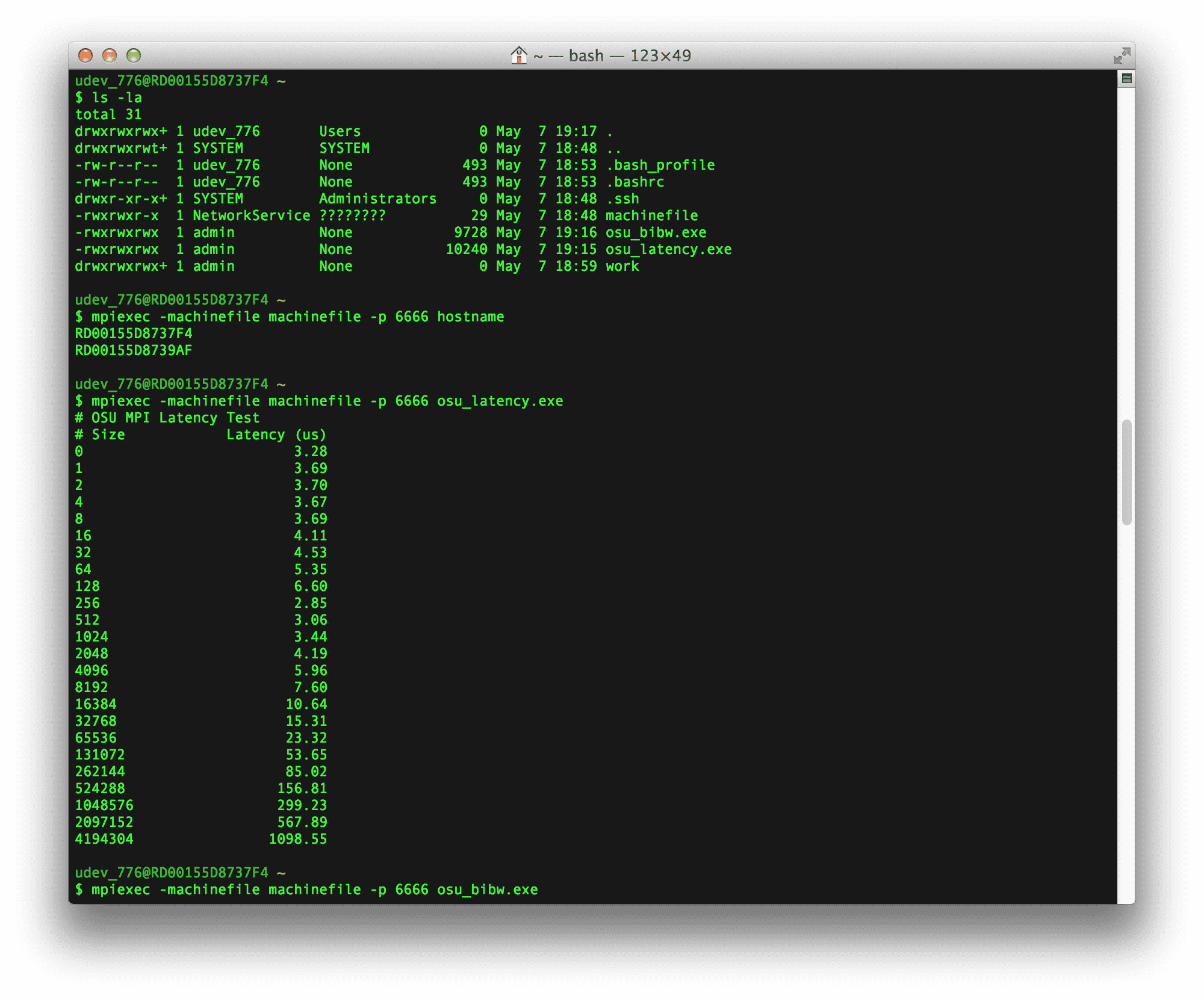
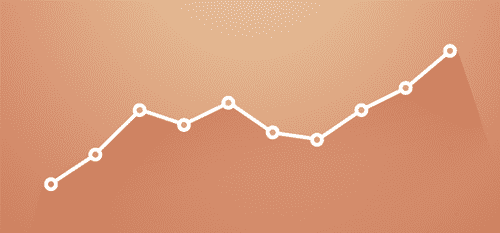
The results of the benchmarks are below. As you can see, the 0-byte latency numbers are ~3us and we are seeing ~7.5GB/s being transferred in the bidirectional bandwidth test for larger message sizes, which is pretty close to full saturation.
# OSU MPI Latency Test
# Size Latency (us)
0 3.28
1 3.69
2 3.70
4 3.67
8 3.69
16 4.11
32 4.53
64 5.35
128 6.60
256 2.85
512 3.06
1024 3.44
2048 4.19
4096 5.96
8192 7.60
16384 10.64
32768 15.31
65536 23.32
131072 53.65
262144 85.02
524288 156.81
1048576 299.23
2097152 567.89
4194304 1098.55
# OSU MPI Bi-Directional Bandwidth Test
# Size Bi-Bandwidth (MB/s)
1 0.43
2 0.87
4 1.69
8 3.35
16 6.82
32 13.69
64 18.64
128 29.12
256 486.75
512 1174.69
1024 2170.21
2048 3844.66
4096 5982.22
8192 2873.87
16384 7078.87
32768 6669.85
65536 4926.26
131072 4878.30
262144 5853.30
524288 6674.26
1048576 7066.08
2097152 7344.74
4194304 7479.30
These are very impressive performance numbers. I suspect that the real tipping point for Big Compute usage however, will be once Microsoft adds support for Linux VMs with their IaaS solution. It is not clear from the documentation available online what the timeline for this is right now (IaaS support for Windows Server was just recently added). It will be interesting to see how the new low-latency interconnect wars play out in 2014. As always, Rescale intends to remain agnostic on providers and offer our customers the best available hardware.