

Solving Queuing Quarrels: Slurm-Rescale Connector Makes Hybrid-Cloud Seamless for On-prem HPC Users
Rescale just announced support of Slurm workload manager via a seamless cloud connector, opening up a new path to hybrid-cloud for organizations who use Slurm to manage their on-premises high performance computing (HPC) clusters. Slurm is a popular, open-source workload scheduler that is widely used in two-thirds of the most powerful supercomputers in the world, especially for government, national lab, and higher education systems.
HPC Schedulers, Queuing, and the Limits of On-Prem Hardware
In traditional, on-premises computing, schedulers are a critical part of the technology stack, allowing many users to interact with their organizations’ servers for computational tasks. Schedulers allow users and administrators to use commands to monitor and manipulate when jobs should be executed and how much available resources they should utilize. Using a scheduler ensures HPC jobs are completed in a sequential and efficient manner, maximizing the hardware utilization of a given set of hardware or ‘cluster’. This “scheduling” becomes “queuing” when multiple jobs stack up causing delays, an inconvenient side effect of on-premises (fixed) computing causing scientists and engineers to wait until resource capacity frees up for their job. Frequent delays caused by insufficient resources are detrimental to R&D and commercialization timelines which is why there is such a strong emphasis on expanding access to additional hardware e.g. bursting to cloud. It’s all too common for IT/HPC managers and end-users to disagree on how best to balance the trade-off between capacity availability and utilization for on-prem deployments.
Bridging Traditional and Cloud-based Operations
Cloud computing largely solves the problem of queuing with the availability of virtually unlimited capacity. While market data shows that cloud HPC growth outpaces on-prem by 2-3x, many aging on-prem systems are still in operation and managed by schedulers today. Most organizations (78%) say they have already begun using cloud for HPC but many of them will run these infrastructures separately. For many organizations in the middle of their digital transformation, being full-cloud is still a destination further down the pike and they need solutions that allow them to fully utilize all available resources. One thing is for sure, computing requirements rarely decrease so bursting to the cloud is often a first step on the way to a cloud-first HPC operating model. With Slurm expanding support for cloud and specialized CPU and GPU architectures, it’s an ideal scheduler to partner with to bring Rescale’s advanced cloud HPC automation to bigger audience.
True Hybrid, Multi-Cloud HPC with Rescale and Slurm
Building an HPC practice in the cloud from scratch is nuanced, especially one that takes full advantage of cloud’s benefits for HPC. Having control and flexibility to scale up or down across multiple clouds and multiple architectures has a big impact on workload performance and cost-efficiency. IT administrators are accustomed to having full control and understanding of their HPC operations on-premises, and incorporating cloud can introduce new complexity. Where many point solutions or homegrown tools struggle, Rescale seamlessly connects many common digital tools across the computing stack. Rescale’s Slurm-connector co-developed with RedLine Performance Solutions allows HPC users and admins to submit jobs using familiar Slurm commands to any cloud of their choice including AWS, Azure, Google, and other hyperscale and specialty cloud service providers – all without any prior experience with Rescale required!
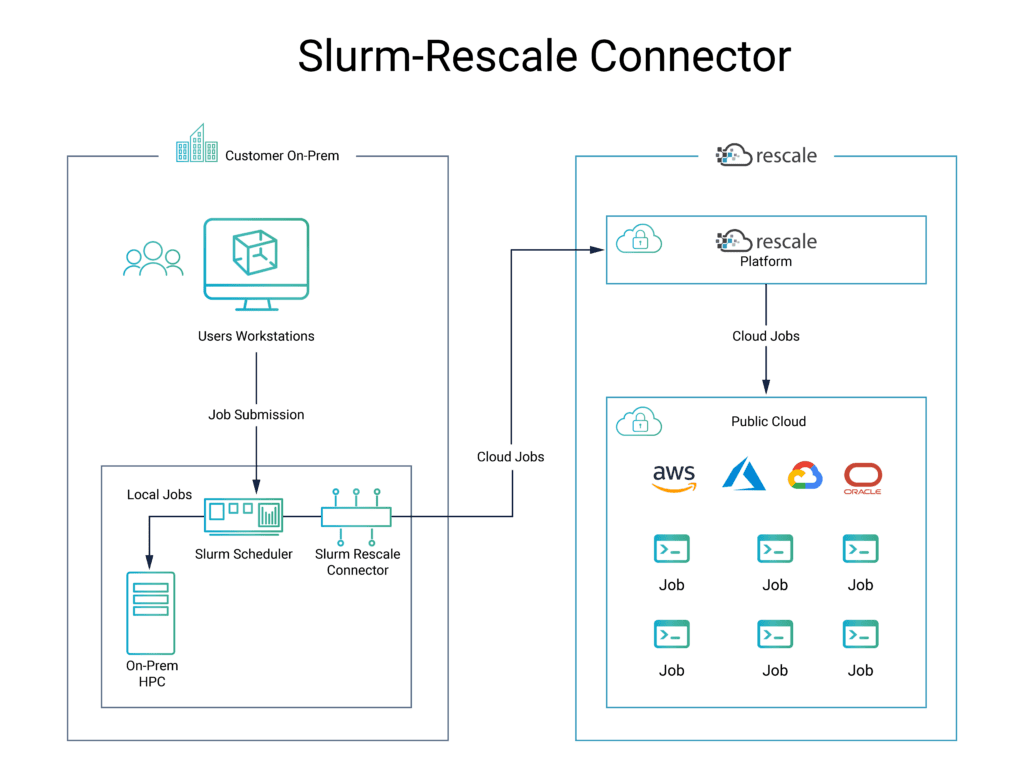
The Slurm-Rescale Connector demonstrates a capability to submit jobs from Slurm to the Rescale platform using the Rescale API. The connector code is a modified version of the Slurm source code that allows users to access the Rescale platform using familiar Slurm commands. To accomplish this, the source code of the Slurm repository was forked into a separate branch and customized with Rescale specific updates. It will be maintained by Rescale and updated after every new Slurm release. To accomplish hybrid orchestration of workloads, typical Slurm scripts are modified and extended to fork the workflow to either on-prem or Rescale resources based on policies set by the user’s organization.
Empower Unconstrained and Accelerated Digital R&D
This additional functionality for Rescale users opens up new possibilities to many organizations who were operating disparate systems or were cloud hold-outs due to concerns about changing their user experience. Using Slurm’s familiar commands for job submission and monitoring, engineers and scientists can leverage their existing resources like normal, while administrators can solve computing resource constraints by automatically shifting to the cloud as-needed. Any IT or HPC manager who deploys a successful Hybrid cloud solution is an instant hero, scoring big points for 1) reducing user wait times to zero and 2) maximizing the useful life of existing computing investments. Having a consistent workload management experience can ensure continuous operations across multiple compute environments, while the added performance optimization of Rescale will ensure organizations select the latest and best architecture for each workload.
For organizations that require high levels of security and compliance, they can now enjoy the benefits of cloud with the assurances of Rescale’s leading standards like ITAR, FedRAMP, and ISO-27001. Rescale is the first and only platform for full-stack HPC with FedRAMP Moderate Authorization and continues to invest in additional measures to ensure that that the public cloud is accessible to both public and private sector organizations.
Getting Started with Slurm on Rescale
We are excited to showcase this new capability at Supercomputing 22 and invite anyone interested to stop by our booth (#2741) for a demonstration. You can read the official announcement of the news here.





