複雑さがイノベーターのコンピューティングへの無限の欲求の理由です
今年、私たちは共同設立し、 ビッグコンピューティング コミュニティを設立し、XNUMX 月に SFJAZZ で開催されるソート リーダーシップ カンファレンスで始まります。

「ビッグコンピューティングとは正確には何ですか? ビッグデータに似ていますか?」
ビッグ コンピューティング コミュニティは、ほぼ無限のコンピューティング能力を必要とする、またはその恩恵を受ける可能性がある問題を解決するためのテクニックについて議論するエンジニアと科学者のグループです。
私たちは、次のような単純ですぐに使える質問からこのコンセプトを確立しました。 もしコンピューティングが完全に無料で容量が無限だったら、私たちの世界はどう変わるでしょうか?
ちょっと突飛なアイデアですね。
それはそれほど突飛なことではありません。 インスタント メッセージング、電子メール、ソーシャル メディアにより、私たちはほぼ無限の接続を実現しました。 しかし、ほとんどの人が苦労していると思います 無限の概念、そしてそれは一般的にほとんどの企業や機関の見通しに欠けていること。 非常に革新的な企業でさえ、コスト削減、リソース管理、予算を高く評価しています。
これが製品開発にどのように影響するかは次のとおりです。組織はエンジニアのためにコンピュータまたは小規模なデータセンターを購入しますが、その固定容量とアーキテクチャの特性に制約を受けます。 これにより、ユーザーは探索的なシナリオに追い込まれることになります。基本的にエンジニアの課題は、「利用可能なもの (少ないもの) を使ってどれだけのことができるか?」という問題を解決することです。 マクガイバーモード:有効、イノベーターモード:無効。
ほぼ瞬時に、あなたを「支援」する寄生リソース管理ツールの市場が形成されます。 これらは、中間管理層、魂を吸い取るアプリケーション、優先順位付け機能、TCO 計算機能、そして最悪のスケジューラの層の形をとります。 本質的に、これらは、計算に飢えたイノベーターに「いいえ」、「今はだめ」、「高すぎる」、または「優先事項ではない」のいずれかを伝えるための体系的な方法にすぎません。
そのエンジニアは今、官僚的な行列に並んで惨めに待っている。
そしてそれは単にクールではありません。 イノベーションに対するこの締め付けよりも悪いことはただ一つ 広告を数えるソフトウェアを書くのは貴重なエンジニアリングの年月を無駄にしている。 マクガイバーはクリップを使って鍵を開けるという賢い人でしたが、正直に言ってみましょう…彼は空飛ぶタクシーや超音速旅客機を作ったわけでも、火星コロニーを建設したわけでもありません。
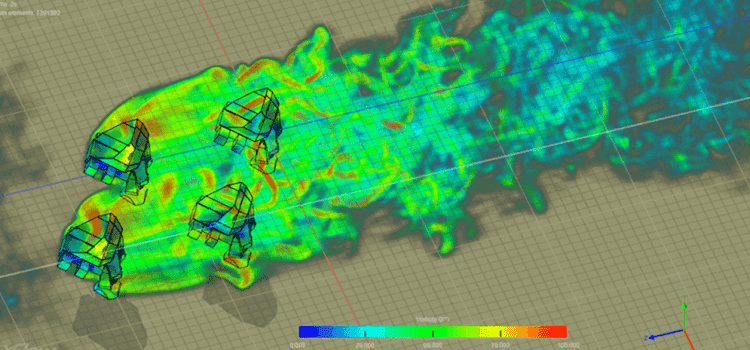
過去数十年にわたり、コンピューティングの需要は急激に増加しました。その理由を説明するのは難しくありません。革新的な航空機会社に勤務し、単一部品の設計を担当している航空宇宙エンジニアを例に挙げてみましょう。 仕事上、彼は 6 ~ 8 個のシミュレーション ソフトウェア アプリケーションを使用して、設計が仕様を満たすのに十分な強度と、ジェット燃料のコストに影響を及ぼさないほどの軽さ、および大量生産できるほど単純であることを検証します。
これらのアプリケーションを実行するには、10,000 ドルのワークステーションを机の下に置き、すべて自分で実行できます。 基本設計が検証されると、仕事は終わったと思いがちですが、まだ始まったばかりです。 実際のところ、彼は開発に関する最初の重要な質問にのみ対処できています。それは、この XNUMX つの設計が基本仕様を満たしているかということです。 現在チェックできる相互依存関係の広大な構造があり、分析の連続レベルごとにさらに何倍もの計算量が発生します (コア時間で以下に見積もられます)。
| 誰 | イノベーションの質問 | サイクルあたりのコア時間 |
| 個々の | この XNUMX つの設計は基本スペックを満たしていますか? | 1の時間 |
| 個々の | サブアセンブリでは期待どおりに動作しますか? | 3時間 |
| 個々の | 利用可能な材料のうちどれで作るべきですか? | 5時間 |
| 個々の | 安価に製造できるのでしょうか? | |
| パッケージ種類 | サブアセンブリはメイン アセンブリ内で動作しますか? | 1日 |
| パッケージ種類 | サブアッセンブリーは安く設置できますか? | 2日 |
| パッケージ種類 | すべての材質に互換性がありますか? | 2日 |
| パッケージ種類 | サブアセンブリのメンテナンスは可能ですか? | 3日 |
| オルガン | 本体アセンブリは全体の中で安全認証に合格していますか? | 5日 |
| オルガン | アセンブリ全体に振動、騒音、雰囲気/品質の問題はありますか? | 6日 |
| オルガン | 安全性と品質のトップ 10 の構成を調査できますか? | 12日 |
| オルガン | 全体的なデザイン構成の上位 1000 件を調査できますか? | 22日 |
質問が続くたびに、ますます設計の複雑さが分析とシミュレーションに組み込まれます。 これはエンジニアにとっては安心ですが、設計の信頼性を維持するために必要なコンピューティング能力が飛躍的に向上し、重要なものを見落とすリスクが軽減されます。
残念ながら、 こういうミスは頻繁にある 製品のコスト、品質、安全性、納期に大きな影響を与える可能性があります。 これらのミスのほとんどに対するリーダーの反応は、リスク管理の手段としてより多くのテスト、シミュレーション、検証を行うという組織の誓約です → それは複雑さの基準を増加させ、ひいては正味のコンピューティング需要を増加させることを意味します。
探索的シナリオとは対照的に、規範的シナリオでは次のことが求められます。 欲しいものを正確に入手するには何を使用すればよいですか? これにより、リソースに制限がなくなり、本当に欲しいものを引き出すことが強制され、ニューロンの衝突が「イノベーション モード」に戻ります。 このモードでは、「方法」は目的を達成するための単なる手段であり、重要なのは目的だけです。
ハードウェアは重要ではありませんし、重要ではありません。 これを読んでいるクラスターハガー、サーバーマニア、スケジューラーの人には申し訳ありませんが、速度とフィードの時代は間もなく終わります。
では、なぜビッグ コンピューティング コミュニティが必要なのか、そしてなぜ今なのか?
簡単な答え: コンピューティングはついに広く普及し、需要は (依然として) 増加しています
私たちは、ユーザーが解決すべき問題に必要なすべてのコンピューティング能力に即座にアクセスできる時代に入りつつあります。 インスタントアクセス? 全部コンピューティング? 何の問題? これは狂気で不安なことであり、それについて話し合う必要があると思います。 したがって、ビッグ コンピューティング コミュニティは、ものの作り方の再評価を促進し、製品開発の問題に対するリソースが限られた考え方から解放されるように構築されています。
無制限で無料のコンピューティング (またはほぼそれに近い) があるため、ビッグ コンピューティングでは XNUMX つの主要な議論カテゴリーがあると思います。
- あなたがやりたいことは何ですか、またその理由は何ですか?
- 引き出しのパズルを解き、「なぜこの目標を選んだのか?」に答えます。
- この選択の背後にあるイノベーションの原動力は何ですか?
- どの程度の複雑さに対処する必要がありますか?
- この考え方の変化は現実世界に、特にコンピューティングに対する需要にどのような影響を与えましたか?
- コンピューティングの使用法は実際にどのように変化するのでしょうか?
- BigCompute ユーザーはどのようなコンピューティング アーキテクチャを好みますか?
でお会いできることを楽しみにしています Big Compute 20 今度は11月XNUMX日です。 規範的な考え方と、重要な複雑な問題を解決するための猛烈な欲求をもたらしてください。