Rescale での複数の GPU を使用したディープ ラーニング: TensorFlow チュートリアル

で 以前の投稿では、複数の GPU を使用してディープ ニューラル ネットワーク (DNN) をトレーニングする例を示しました。 トーチ 機械学習ライブラリ。 この投稿では、を使用してマルチ GPU トレーニングを実行することに焦点を当てます。 TensorFlow.
特に、Rescale でマルチ GPU およびマルチノード構成を使用したデータ並列 GPU トレーニングについて調査します。 Rescale の既存の MPI 構成クラスターを活用して、TensorFlow 分散トレーニング ワーカーを簡単に起動します。 単一 GPU で TensorFlow を使用したトレーニングの基本的な例については、を参照してください。 この前の投稿.
データの準備
マルチ GPU トレーニング セッションをより興味深いものにするために、より大きなデータセットを使用します。 後ほど、人気のトレーニング ジョブを紹介します。 ImageNet 画像分類データセット。 この 150 GB データセットを開始する前に、TensorFlow トレーナーが適切に動作していることを確認するために、ImageNet と同じ形式になるように小さいデータセットを準備し、それを使用してジョブをテストします。 トレーニング中にデータをローカルに保つために、Rescale はトレーニングの開始前にデータセットを GPU ノード上のローカル ストレージに同期します。 ほんの数例を使用してモデルを繰り返し開発するときに、ImageNet のような大規模なデータセットが同期するのを待つのは無駄です。 このため、小さいものから始めます 花 データセットを作成し、実際に動作する例が得られたら ImageNet に移動します。
TensorFlow は、次のようにフォーマットされた画像を処理します。 TFレコード まず、花のデータセットから PNG をダウンロードして、この形式になるように前処理しましょう。 今日紹介するすべての例は、 tensorflow/モデルリポジトリ GitHub 上にあるため、まずそのリポジトリのクローンを作成します。
git clone https://github.com/tensorflow/models
今、私たちは バゼル 花のダウンロードと前処理スクリプトを作成し、そのスクリプトを実行するツールを構築します。
Pushd モデル/inception bazel clean bazel ビルド inception/download_and_preprocess_flowers Popd モデル/inception/bazel-bin/inception/download_and_preprocess_flowers $(pwd)/flowers
これにより、約 220MB のアーカイブがダウンロードされ、次のようなものが作成されます。
$ ls flowers flowers_photos.tgz train-00000-of-00002 validation-00000-of-00002 raw-data train-00001-of-00002 validation-00001-of-00002
このアーカイブを組み立てて、Rescale にアップロードします。 必要な情報はすべて TFRecord としてエンコードされているため、オプションで生データとアーカイブ ファイルを削除できます。
Pushd flowers rm -rf raw-data flowers_photos.tgz Popd tar czf flowers.tar.gz flowers
これらすべての操作を Rescale の前処理ジョブにまとめました。 ここ 自分でクローンを作成して実行できるようにします。
次に、作成した flowers.tar.gz ファイルを取得して、次のステップの入力ファイルに変換しましょう。
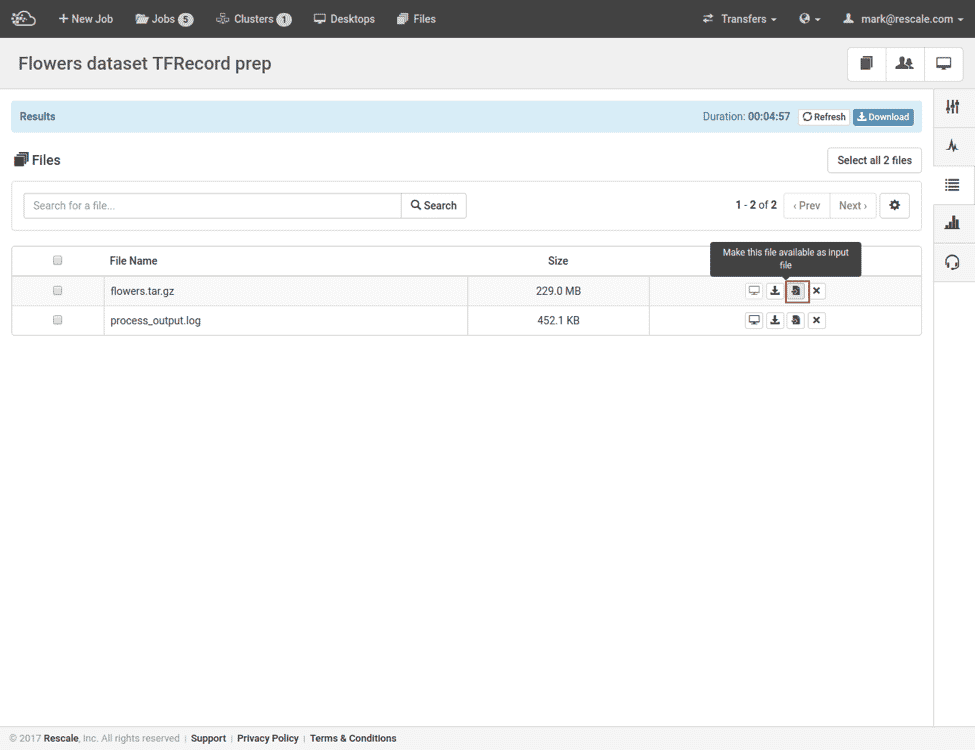
これで、前処理された花の画像 TFRecord をトレーニングできるようになりました。
単一ノード – 複数の GPU
次のステップは、この入力データセットを取得し、それを使用してモデルをトレーニングすることです。 前述のように、Tensorflow/models リポジトリの Inception v3 DNN アーキテクチャを使用します。 複数の GPU を備えた単一ノードでのトレーニングは次のようになります。
まず、単一ノードで実行される再スケール ジョブを作成します。これは、複数ノードの場合よりも可動部分が少ないためです。 このジョブでは実際に 3 つのプロセスを実行します。
- メインの GPU ベースのモデル トレーニング
- 検証セット上のチェックポイントが設定されたモデルの CPU ベースの評価
- TensorBoard 視覚化ツール
それでは始めましょう! まず、 トレーニング & 評価 スクリプト。
Pushd モデル/インセプション バゼル クリーン バゼル ビルド インセプション/imagenet_train インセプション/imagenet_eval Popd
次に、いくつかの出力ディレクトリを作成し、メインのトレーニング プロセスを開始します。
mkdir -p out/train out/eval models/inception/bazel-bin/inception/imagenet_train --num_gpus=$RESCALE_GPUS_PER_SLOT --batch_size=32 --train_dir=out/train --data_dir=flowers
$RESCALE_GPUS_PER_SLOT すべての Rescale ジョブ環境で設定される変数です。 このコマンド ラインでは、トレーニング イメージを含む flowers ディレクトリと、TensorFlow がログとモデル ファイルを出力する空の out/train ディレクトリを指定します。
検証セットの精度の評価は個別に行うことができ、GPU アクセラレーションは必要ありません。
CUDA_VISIBLE_DEVICES='' models/inception/bazel-bin/inception/imagenet_eval --eval_dir=out/eval --checkpoint_dir=$HOME/work/out/train --eval_interval_secs=1200 --data_dir=flowers
imagenet_eval ループ状態にあり、毎回起動します eval_interval_secs 最近トレーニングされたモデルのチェックポイントの精度を評価するには out/train の検証 TFRecord に対して flowers ディレクトリ。 精度の結果はログに記録されます out/eval. CUDA_VISIBLE_DEVICES ここで重要なパラメータです。 TensorFlow は、GPU を使用しない場合でも、デフォルトで常に GPU メモリにロードされます。 このパラメーターがないと、トレーニングと評価の両方のプロセスで GPU 上のすべてのメモリが使い果たされ、トレーニングが失敗します。
最後に、TensorBoard は TensorFlow の進行状況を監視するための便利なツールです。 TensorBoard は独自の Web サーバーを実行して、トレーニングの進行状況のプロット、モデルのグラフ、およびその他の視覚化を表示します。 開始するには、それを指定するだけです。 out トレーニングおよび評価プロセスが出力されるディレクトリ:
CUDA_VISIBLE_DEVICES='' テンソルボード --logdir=out
TensorBoard は、logdir のすべてのサブディレクトリ内のログを取り込み、トレーニング データと評価データを一緒に表示します。
これをすべてまとめると、次のようになります。
DATASET=flowers Pushd models/inception bazel clean bazel build inception/imagenet_train inception/imagenet_eval Popd mkdir -p out/train out/eval echo "$RESCALE_GPUS_PER_SLOT GPU でのトレーニング" CUDA_VISIBLE_DEVICES='' tensorboard --logdir=out & ( sleep 600; CUDA_VISIBLE_DEVICES= モデル/inception/bazel-bin/inception/imagenet_eval --eval_dir=out/eval --checkpoint_dir=$HOME/work/out/train --eval_interval_secs=1200 --num_examples=350 --data_dir=$DATASET ) &モデル/inception/bazel-bin/inception/imagenet_train --num_gpus=$RESCALE_GPUS_PER_SLOT --batch_size=32 --train_dir=out/train --data_dir=$DATASET
これはすべて単一のシェルで実行されるため、TensorBoard と評価プロセスをバックグラウンドで実行します。 また、トレーニング プロセスの初期化と最初のモデル チェックポイントの作成に数分かかるため、評価プロセスの開始も遅らせます。
このトレーニング ジョブは Rescale で実行できます ここ.
TensorBoard は認証なしで独自の Web サーバーを実行するため、Rescale ではデフォルトでアクセスがブロックされます。 TensorBoard にアクセスする最も簡単な方法は、ノードへの SSH トンネルを開いてポート 6006 に転送することです。
ssh -L 6006:ローカルホスト:6006 @
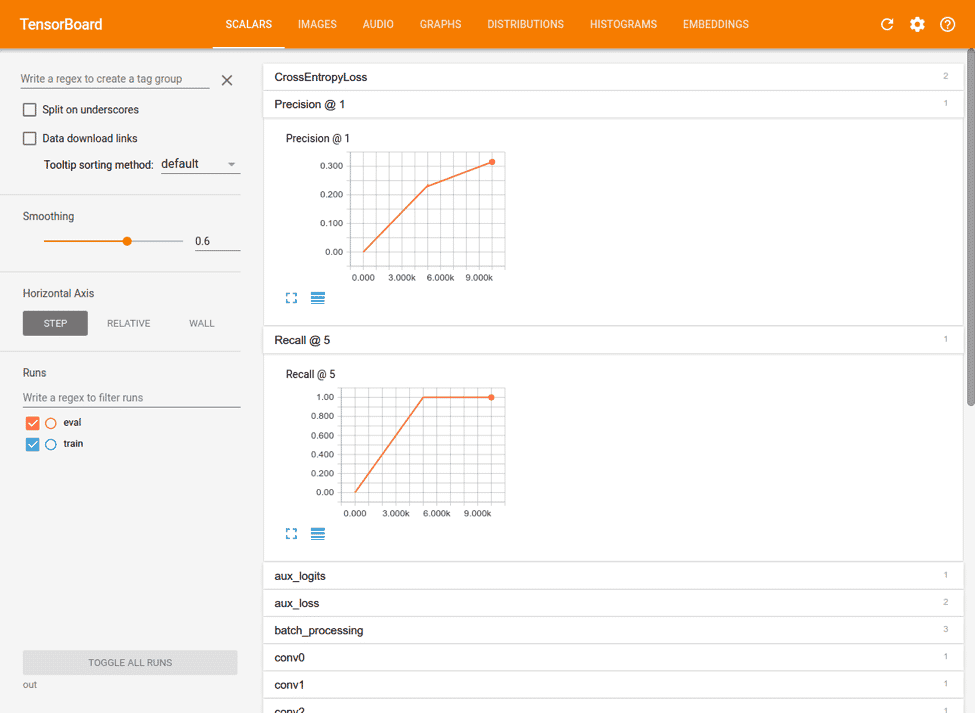
https://localhost:6006 に移動すると、次のような内容が表示されるはずです。
複数のノード
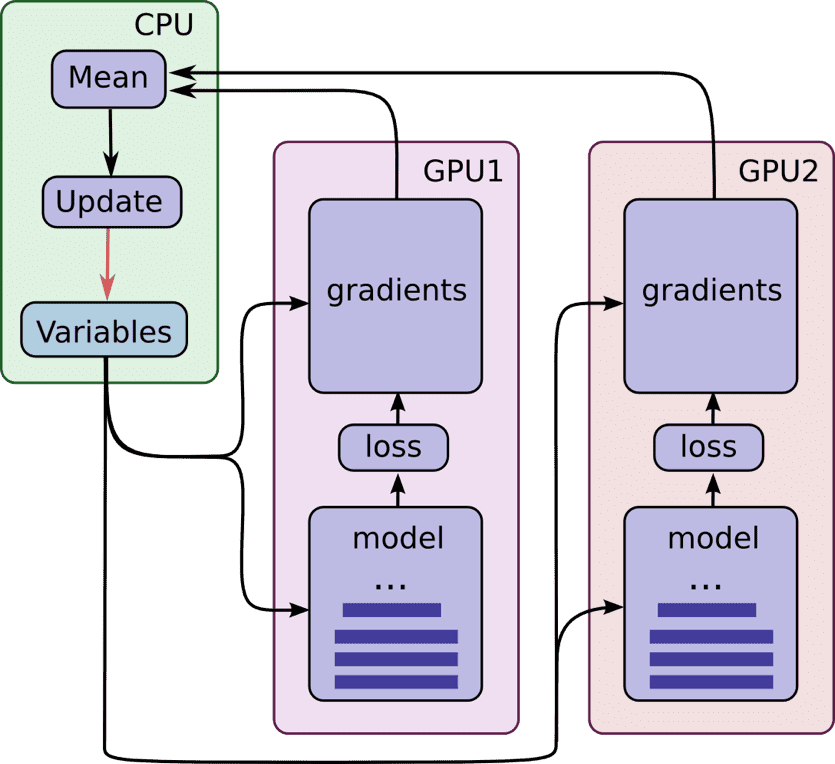
現在の最先端技術では、ノードに装着できる GPU カードの総数は約 8 枚に制限されています。さらに、TensorFlow プロセスが GPU 間で作業を分散するために使用するメカニズムである CUDA ピアツーピア システムは、現在、 8 つの GPU デバイスに制限される。 これらの数は今後も増加しますが、大規模なモデルやデータセットのトレーニングをスケールアウトするメカニズムがあると依然として便利です。 TensorFlow 分散トレーニングは、ネットワーク上の異なるトレーニング プロセス間で更新を同期するため、あらゆるネットワーク ファブリックで使用でき、CUDA 実装の詳細によって制限されません。 分散トレーニングはいくつかの要素で構成されます。 労働者 & パラメータサーバー ここに示すように:
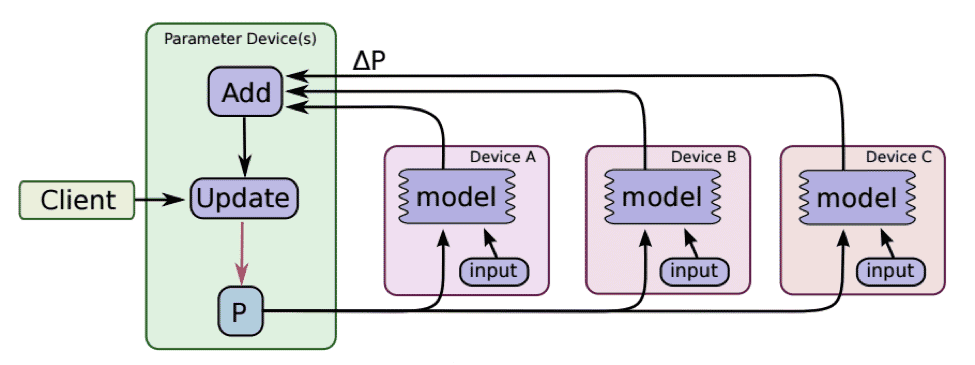
(https://github.com/tensorflow/models/tree/master/inception#how-to-train-from-scratch より)
パラメーター サーバーは、入力バッチの評価に使用されるモデル パラメーターを提供します。 各ワーカーのバッチが完了すると、エラー勾配がパラメーター サーバーにフィードバックされ、パラメーター サーバーはそれらを使用して新しいモデル パラメーターを生成します。 GPU クラスターのコンテキストでは、ワーカー プロセスを実行してクラスター内の各 GPU を使用し、勾配の処理に対応するのに十分なパラメーター サーバーを選択できます。
指示に従う ここでは、GPU ごとにワーカーを設定し、ノードごとにパラメータ サーバーを設定します。 すべての Rescale クラスターに付属する MPI 構成を利用します。
まず、各パラメータ サーバーとワーカーに渡されるホスト文字列を生成する必要があります。各プロセスは一意のパラメータを取得します。 ホスト名:ポート 組み合わせ、たとえば:
--ps_hosts='host1:2222,host2:2222' --worker_hosts='host1:2223,host1:2224,host2:2223,host2:2224'
パラメータ サーバーにはホストごとに XNUMX つのエントリが必要で、ワーカーには GPU ごとに XNUMX つのエントリが必要です。 すべての Rescale クラスターで自動的にセットアップされるマシン ファイルを利用します。 $HOME/machinefile クラスター内のホストのリストがあるだけで、 $HOME/machinefile.gpu には、各ホストの GPU の数が注釈として付けられたホストのリストがあります。 それらを解析して、Python スクリプトでホスト文字列を生成します。 make_hoststrings.py
#!/usr/bin/env python import os.path PS_PORT = 2222 WORKER_PORT_START = 2223 ps_string = ','.join('{0}:{1}'.format(hostname.strip(), PS_PORT) のホスト名open(os.path.expanduser('~/machinefile'))) ワーカー = [] open(os.path.expanduser('~/machinefile.gpu')) のホストライン: ホスト名、スロット、最大スロット = hostline.split () スロット = int(slots.split('=')[1]) ワーカー += ['{0}:{1}'.format(hostname, WORKER_PORT_START + i) for i in range(slots)] print ps_string 、'、'.join(ワーカー)
次に、これらのホスト文字列を取得して、 imagenet_distributed_train 適切なタスク ID と GPU ホワイトリストを含むスクリプト、 tf_mpistart.sh:
#!/bin/bash PROC_TYPE=$1 DATADIR=$2 host_strings=$(./make_hoststrings.py) PS_HOSTS=$(echo $host_strings |cut -d' ' -f1) WORKER_HOSTS=$(echo $host_strings |cut -d' ' -f2) TASK_ID=$OMPI_COMM_WORLD_RANK if [ $PROC_TYPE == 'ps' ]; then CUDADEV='' else CUDADEV=$OMPI_COMM_WORLD_LOCAL_RANK fi CUDA_VISIBLE_DEVICES=$CUDADEV models/inception/bazel-bin/inception/imagenet_distributed_train --batch_size=32 --data_dir=$DATADIR --train_dir=out/train --job_name=$PROC_TYPE --task_id=$TASK_ID --ps_hosts="$PS_HOSTS" --worker_hosts="$WORKER_HOSTS" >>${PROC_TYPE}-$TASK_ID.log 2>&1
tf_mpistart.sh OpenMPI で実行されます mpirun so $OMPI* 環境変数は自動的に挿入されます。 を使用しております $OMPI_COMM_WORLD_RANK グローバルタスクインデックスを取得し、 $OMPI_COMM_WORLD_LOCAL_RANK ノードのローカル GPU インデックスを取得します。
さて、すべてをまとめると次のようになります。
DATASET=flowers mv tf_mpistart.sh make_hoststrings.py models $DATASETshared/cdsharedpushdmodels/inceptionbazelcleanbazel --output_base=$HOME/work/shared/.cachebuildinception/imagenet_distributed_traininception/imagenet_evalpopdmkdir -pout/ train out/eval CUDA_VISIBLE_DEVICES= tensorboard --logdir=out & mpirun -machinefile ~/machinefile ./tf_mpistart.sh ps & ( sleep 600; CUDA_VISIBLE_DEVICES= models/inception/bazel-bin/inception/imagenet_eval --eval_dir=out/eval --checkpoint_dir=$HOME/work/shared/out/train --eval_interval_secs=1200 --num_examples=350 --data_dir=$DATASET ) & mpirun -machinefile ~/machinefile.gpu ./tf_mpistart.sh ワーカー
同じディレクトリを大量に作成し、Bazel でボイラープレートを構築することから始めます。 2 つの例外は次のとおりです。
1. すべての入力ディレクトリをshared/サブディレクトリに移動し、ノード間で共有されるようにします。
2. ここで、次のコマンドを使用して bazel build コマンドを呼び出します。 --output_base bazel がビルド製品をシンボリックリンクしないようにする $HOME/.cache その代わりに、それらを共有ファイルシステム上で利用できるようにします。
次に TensorBoard を起動し、 imagenet_eval MPI マスター上でローカルに。 これら 2 つのプロセスは、mpirun を使用してノード間で複製する必要はありません。
最後に、パラメータサーバーを起動します。 tf_mpistart.sh ps そして、ノードマシンファイルごとに単一のエントリ、次にワーカー tf_mpistart.sh worker GPU ランクの machinefile.gpu を使用します。
ここに は、2 つの Jade ノード (8 つの K520 GPU) を使用して、花のデータセットに対して上記の分散トレーニングを実行するジョブの例です。 Rescale ですでにセットアップされている MPI インフラストラクチャを使用しているため、任意の数のノードまたはノードごとの GPU に対してこの同じ例を使用できることに注意してください。 適切なマシンファイルを使用すると、ワーカーとパラメータ サーバーの数がリソースに合わせて自動的に設定されます。
ImageNet でのトレーニング
これで、より小さな花のデータセットで TensorFlow 分散トレーニング ジョブを開始するための機構が開発されたので、完全な ImageNet データセットでトレーニングする準備が整いました。 ImageNet のダウンロードには許可が必要です ここ。 アクセスをリクエストすると、必要な tarball をダウンロードするためのユーザー名とパスワードが与えられます。
次に、上記の花のジョブと同様の準備ジョブを実行して、データセットをダウンロードし、画像を TFRecord にフォーマットします。
# ************************* # IMAGENET の値を以下に設定します # ****************** ******* DATA_DIR=$HOME/work/imagenet-data をエクスポートします。 IMAGENET_USERNAME をエクスポートします。 IMAGENET_ACCESS_KEY をエクスポートします。 cd モデル/inception bazel ビルド inception/download_and_preprocess_imagenet bazel-bin/inception/download_and_preprocess_imagenet "${DATA_DIR}" rm -rf imagenet -data/raw-data imagenet-data/*.gz tar -cf ilsvrc2012.tar imagenet-data rm -rf imagenet-data
この準備ジョブを Rescale で複製して実行できます。 ここ.
ImageNet サイト (ILSVRC3_img_train.tar、ILSVRC2012_img_val.tar、および ILSVRC2012_bbox_train_v2012.tar.gz) から 2 つの必要な入力を既にダウンロードし、HTTP 経由でアクセスできる場所 (AWS S3 バケットなど) に配置している場合は、カスタマイズできます。 モデル/インセプション/インセプション/データ/download_imagenet.sh tensorflow/models リポジトリ内でカスタムの場所からダウンロードします。
# ************************ # BASE_URL の値を以下に設定 # ******************* ***** エクスポート DATA_DIR=$HOME/work/imagenet-data エクスポート BASE_URL= sed -i "s#BASE_URL=.*#BASE_URL=${BASE_URL}#" download_imagenet_noauth.sh mv download_imagenet_noauth.sh モデル/インセプション/インセプション/data/download_imagenet.sh cd モデル/inception bazel ビルド inception/download_and_preprocess_imagenet bazel-bin/inception/download_and_preprocess_imagenet "${DATA_DIR}" rm -rf imagenet-data/raw-data imagenet-data/*.gz tar -cf ilsvrc2012。 tar イメージネット データ rm -rf イメージネット データ
このバージョンの準備ジョブのクローンを作成して実行します ここ.
最後に、先頭の $DATASET 変数を変更することで、マルチ GPU 花のジョブに若干の変更を加え、flowers ディレクトリの代わりに imagenet-data データセット ディレクトリを取得できます。
DATASET=imagenet-data Pushd models/inception bazel clean bazel build inception/imagenet_train bazel build inception/imagenet_eval Popd mkdir -p out/train out/eval echo "$RESCALE_GPUS_PER_SLOT GPU でのトレーニング" CUDA_VISIBLE_DEVICES= tensorboard --logdir=out & ( sleep 600; CUDA_VISIBLE_DEVICES= モデル/インセプション/bazel-bin/inception/imagenet_eval --eval_dir=out/eval --checkpoint_dir=$HOME/work/out/train --eval_interval_secs=1200 --data_dir=$DATASET ) & モデル/インセプション/bazel-bin/inception/imagenet_train --num_gpus=$RESCALE_GPUS_PER_SLOT --batch_size=32 --train_dir=out/train --data_dir=$DATASET rm -rf $DATASET モデル
そして分散トレーニングのケース:
DATASET=imagenet-data Pushd models/inception bazel clean bazel build inception/imagenet_train bazel build inception/imagenet_eval Popd mkdir -p out/train out/eval echo "$RESCALE_GPUS_PER_SLOT GPU でのトレーニング" CUDA_VISIBLE_DEVICES= tensorboard --logdir=out & ( sleep 600; CUDA_VISIBLE_DEVICES= モデル/インセプション/bazel-bin/inception/imagenet_eval --eval_dir=out/eval --checkpoint_dir=$HOME/work/out/train --eval_interval_secs=1200 --data_dir=$DATASET ) & モデル/インセプション/bazel-bin/inception/imagenet_train --num_gpus=$RESCALE_GPUS_PER_SLOT --batch_size=32 --train_dir=out/train --data_dir=$DATASET rm -rf $DATASET モデル
TensorFlow を使用してマルチ GPU、単一およびマルチノードのモデル トレーニングを実行するための詳細をすべて確認しました。 今後の投稿では、分散トレーニングのパフォーマンスへの影響について説明し、さまざまなサーバー構成で分散トレーニングがどの程度うまく拡張できるかを見ていきます。
ジョブの再スケール
この例で使用される Rescale ジョブの概要を次に示します。 リンクをクリックしてジョブを Rescale アカウントにインポートします。
花のデータセットの前処理
単一ノードの花のトレーニング
複数ノードの花のトレーニング
ImageNet ILSVRC2012 のダウンロードと前処理
既存の S2012 バケットからの ImageNet ILSVRC3 ダウンロード