Rescale の複数の GPU を使用したディープ ラーニング: トーチ

今日は、複数の GPU を利用して単一のニューラル ネットワークをトレーニングする方法について説明します。 トーチ 機械学習ライブラリ。 これは、複数の GPU と複数のノードを使用するためにディープ ニューラル ネットワーク (DNN) トレーニング ワークロードをスケールアップする手法に関する一連の記事の最初の記事です。
このシリーズでは、単一ネットワークのトレーニングの並列化に焦点を当てます。 構成パラメータを最適化するために複数のネットワークを効率的にトレーニングするという、恥ずかしいほど並列的な問題の詳細については、以下を参照してください。 ハイパーパラメータの最適化に関する以前の投稿.
トーチについて
Torch は、Lua プログラミング言語上に構築された軽量で柔軟な tensor ライブラリです。 Torch は機械学習の研究者に人気があるため、多くの新しいディープ ニューラル ネットワークのアイデアがまず Torch に実装され、オープンソース拡張機能として利用可能になります。 したがって、最先端の深層学習は、多くの場合、Torch で最初に使用できるようになります。
この欠点は、Torch ドキュメントが実装に遅れることが多いため、実際にやりたいことを示す例が github で見つからない限り、どの Torch モジュールを使用する必要があり、どのように使用するかを理解するのが困難になる可能性があることです。
この一例は、Torch に複数の GPU を使用してニューラル ネットワークをトレーニングさせる方法です。 インターネットで「マルチ GPU トーチ」を検索すると、次のような結果が得られます。 このgithubの問題 上位の結果の XNUMX つとして挙げられます。 このことから、トーチ環境から複数の GPU にアクセスできることがわかりましたが、この低レベルの構造を使用して複雑なネットワークをトレーニングするにはどうすればよいでしょうか?
データとモデルの並列性
単一のニューラル ネットワークをトレーニングする作業を並列化する場合、作業を分割する方法には 2 つの選択肢があります。モデル並列処理とデータ並列処理です。
モデル並列処理を使用すると、各 GPU は、特定のデータ バッチに対してネットワーク内のノードのチャンクを実行します。
データ並列処理を使用すると、各 GPU がさまざまなデータ バッチに対してネットワーク全体を実行します。
この違いについては詳しく説明します この論文ではただし、どちらを使用するかの選択は、GPU 間でどのような種類の同期が必要かに影響します。 データの並列処理にはモデル パラメーターの同期が必要で、モデルの並列処理にはチャンク間の入力値と出力値の同期が必要です。
簡単なトーチの例
次に、畳み込みニューラル ネットワークをトレーニングする簡単な例を見ていきます。 Torch 自体での単体テスト。 このネットワークには、2 つの畳み込み層と 2 つの整流層があります。 ネットワーク上で単純な前方および後方パスを実行します。 トレーニングのために誤差勾配を実際に計算する代わりに、物事をシンプルにするために誤差勾配をランダムなベクトルに設定するだけです。
'nn' が必要です モデル = nn.Sequential() モデル:add(nn.SpatialConvolution(3, 3, 3, 5)) モデル:add(nn.ReLU(true)) モデル:add(nn.SpatialConvolution(3, 3) , 3, 5)) モデル:add(nn.ReLU(true)) 入力 = torch.round(torch.Tensor(16, 3, 10, 10):uniform(0, 255)) 出力 = model:forward(input ) fakeGradients = 出力:clone():uniform(-0.1, 0.1) モデル:backward(input, fakeGradients)
次に、GPU で実行できるように変換しましょう (この例は、CUDA 互換の GPU がある場合にのみ実行されます)。
'cutorch' が必要です 'cunn' が必要です Cutorch.setDevice(1) モデル = nn.Sequential() モデル:add(nn.SpatialConvolution(3, 3, 3, 5)) モデル:add(nn.ReLU(true)) モデル:add(nn.SpatialConvolution(3, 3, 3, 5)) model:add(nn.ReLU(true)) model:cuda() input = torch.round(torch.CudaTensor(16, 3, 10, 10) :uniform(0, 255)) 出力 = モデル:フォワード(入力) fakeGradients = 出力:clone():uniform(-0.1, 0.1) モデル:バックワード(入力, fakeGradients)
これを GPU で実行するには、次のように呼び出します。 cuda()ネットワーク上で入力を CudaTensor.
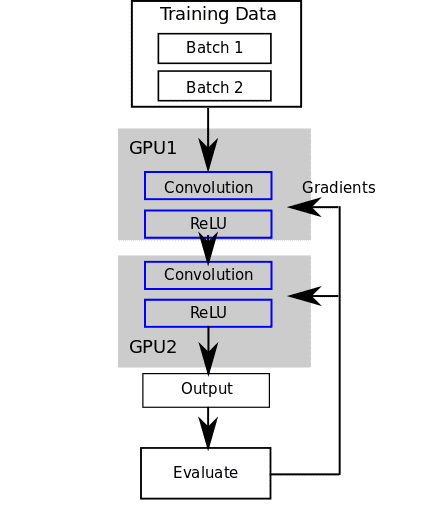
次に、モデルを 2 つの GPU に分散させてみましょう (モデルの並列パラダイムの例として)。 GPU デバイス ID を反復処理し、 カットーチ.withDevice 各レイヤーを特定の GPU に配置します。
require 'cutorch' require 'cunn' Cutorch.setDevice(1) モデル = nn.Sequential() for i=1, math.min(2, Cutorch.getDeviceCount()) do Cutorch.withDevice(i, function() モデル: add(nn.SpatialConvolution(3, 3, 3, 5)) end) Cutorch.withDevice(i, function() model:add(nn.ReLU(true)) end) end model:cuda() input = torch.round (torch.CudaTensor(16, 3, 10, 10):uniform(0, 255)) 出力 = モデル:フォワード(入力) fakeGradients = 出力:clone():uniform(-0.1, 0.1) モデル:バックワード(入力,偽のグラデーション)
これにより、畳み込み層と ReLU 層が各 GPU に配置されます。 前方パスと後方パスでは、GPU 1 と GPU 2 の間で出力を伝播する必要があります。
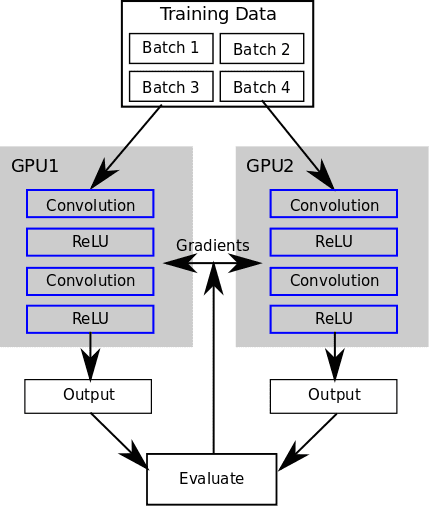
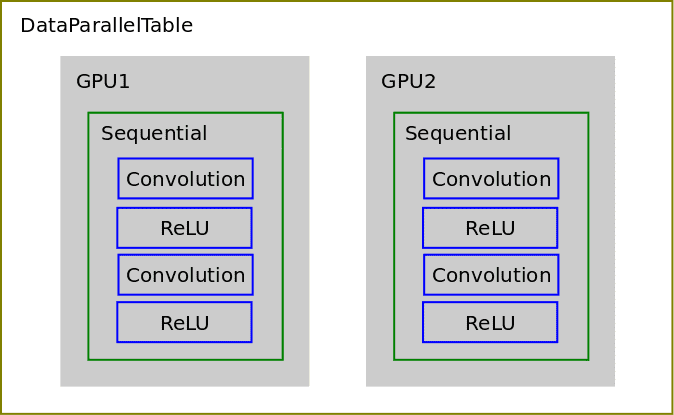
次に、 nn.DataParallelTable 複数の GPU で実行されているネットワーク全体のコピーにデータのバッチを配布します。 DataParallelTable は、複数のコンテナをラップし、それらのコンテナ全体に入力を分散するトーチ コンテナです。
'cutorch' が必要です 'cunn' が必要です Cutorch.setDevice(1) モデル = nn.Sequential() モデル:add(nn.SpatialConvolution(3, 3, 3, 5)) モデル:add(nn.ReLU(true)) モデル:add(nn.SpatialConvolution(3, 3, 3, 5)) model:add(nn.ReLU(true)) model:cuda() gpus = torch.range(1, Cutorch.getDeviceCount()):totable() dpt = nn.DataParallelTable(1):add(model, gpus):cuda() 入力 = torch.round(torch.CudaTensor(16, 3, 10, 10):uniform(0, 255)) 出力 = dpt:forward (入力) fakeGradients = 出力:clone():uniform(-0.1, 0.1) dpt:backward(input, fakeGradients)
したがって、元の Sequential コンテナー上で前方パスと後方パスを実行する代わりに、DataParallelTable コンテナー上でそれを実行し、データが各 GPU 上のネットワークのコピーに分散されます。
Rescaleの求人はこちら 上記のコードをすべて使用して、自分自身をクローンして実行できます。
より大きな例
次に、実際の DNN をトレーニングする際の DataParallelTable の使用方法を見てみましょう。 Sergey Zagoruyko の実装を使用します。 CIFAR10 のワイド残差ネットワーク github で。
In train.luaを見ると、ベース ニューラル ネットワークのすべての並列化がヘルパー関数によって適用されていることがわかります。
モデル:add(utils.makeDataParallelTable(net, opt.nGPU))
掘り下げる makeDataParallelTableを使用すると、上記の最後の例と同様の構造がわかります。 nn.DataParallelTable:追加
関数 utils.makeDataParallelTable(model, nGPU) nGPU > 1 の場合、ローカル gpus = torch.range(1, nGPU):totable() ローカル最速、ベンチマーク = cudnn.fastest、cudnn.benchmark ローカル dpt = nn.DataParallelTable(1, true, true) :add(model, gpus) :threads(function() local cudnn = require 'cudnn' cudnn.fastest, cudnn.benchmark = 最速、ベンチマーク end) dpt.gradInput = nil model = dpt:cuda() endリターンモデル終了
これらのジョブを複製して、Rescale でトレーニングを自分で実行できます。
10 エポックのトレーニングを実行した後、4 GPU ジョブは単一 GPU ジョブよりも約 3.33 倍高速に実行されることがわかります。 かなりスケールアップしてますね!
この記事では、Torch を使用したモデルとデータの並列 DNN トレーニングの実装例を示しました。 今後の投稿では、他のニューラル ネットワーク ライブラリを使用したマルチ GPU トレーニングの使用法とマルチノード スケーリングについて説明します。