
ディープ ニューラル ネットワークのハイパーパラメーターの最適化
Rescale の実験計画法 (DOE) フレームワークは、機械学習モデルのパフォーマンスを最適化する簡単な方法です。 この記事では、ディープ ニューラル ネットワークでハイパーパラメーターの最適化を実行するためのワークフローについて説明します。 Rescale の DOE の概要については、を参照してください。 このウェビナー.
ディープ ニューラル ネットワーク (DNN) は、ロボット工学、自動運転車、画像検索、顔認識、音声認識など、現在多くのアプリケーションで使用されている人気のある機械学習モデルです。 この記事では、画像分類を行うためにいくつかのニューラル ネットワークをトレーニングし、Rescale を使用して DNN モデルのパフォーマンスを最大化する方法を示します。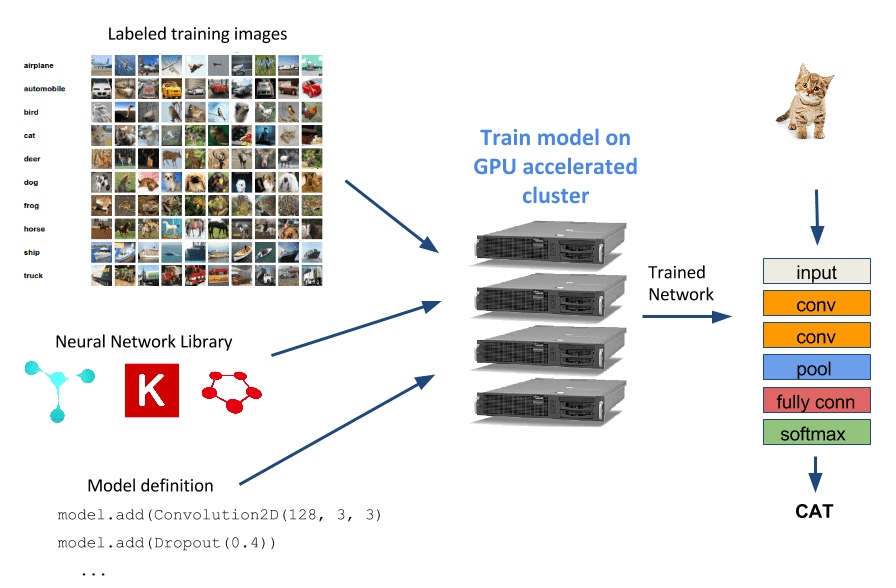
Rescale での画像分類 DNN のトレーニングの概要については、を参照してください。 この前の記事。 この記事では、基本的なモデル トレーニングの例を拡張し、ハイパーパラメーター最適化と呼ばれる手法を通じてネットワークのパフォーマンスを向上させる方法を示します。
ハイパーパラメータの最適化
DNN を使用するタスクの一般的な開始点は、文献で公開されているモデルを選択し、それを選択したニューラル ネットワーク トレーニング フレームワークに実装することです。あるいは、さらに簡単には、次のサイトから実装済みのモデルをダウンロードします。 カフェモデル動物園。 その後、トレーニング データセットでモデルをトレーニングすると、パフォーマンス (分類精度、トレーニング時間など) が十分ではないことが判明する場合があります。 この時点で、戻ってトレーニングするまったく新しいモデルを探すこともできますし、現在のモデルを調整して希望する追加のパフォーマンスを得ることができます。 特定のニューラル ネットワーク アーキテクチャのパラメーターを調整するプロセスは、ハイパーパラメーターの最適化として知られています。 以下は、人々が頻繁に変更するハイパーパラメータの簡単なリストです。
- 学習率
- バッチサイズ
- トレーニングエポック
- 画像処理パラメータ
- レイヤー数
- 畳み込みフィルタ
- 畳み込みカーネルのサイズ
- ドロップアウト率
上記の大規模なハイパーパラメータのリストを考慮すると、モデル アーキテクチャを設定した後でも、同様のニューラル ネットワークのバリアントが多数存在します。 私たちの仕事は、ニーズを十分に満たすパフォーマンスを発揮するバリアントを見つけることです。
ランダム化されたハイパーパラメータ検索 DOE
Rescale プラットフォームを使用して、ハイパーパラメーターをサンプリングし、GPU を使用してこれらのさまざまなネットワーク バリアントをトレーニングするための実験計画法ジョブを作成します。
最初の例では、次の XNUMX つから始めます。 畳み込みネットワークの例 Keras github リポジトリから MNIST 数字分類器をトレーニングします。 このネットワークを使用して、次のネットワーク パラメーターを変更します。
- nb_filters: 畳み込み層のフィルターの数
- nb_conv_size: 畳み込みカーネルのサイズ
上記のテンプレート値を持つように例を変更しました。テンプレート変数を含むスクリプトの抜粋は次のとおりです。
model.add(Convolution2D(${nb_filters}, ${nb_conv_size},
${nb_conv_size}))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
注意してください nb_filters & nb_conv_size で囲まれたパラメータ ${}。 これで、このテンプレートを使用する Rescale プラットフォーム上で DOE ジョブを作成する準備が整いました。
手順に従って進みたい場合は、サンプル ジョブのクローンを作成できます。
Keras MNIST DOE
まず、右上隅で DOE ジョブ タイプを選択し、 mnist.pkl.gz データセット Keras github リポジトリから。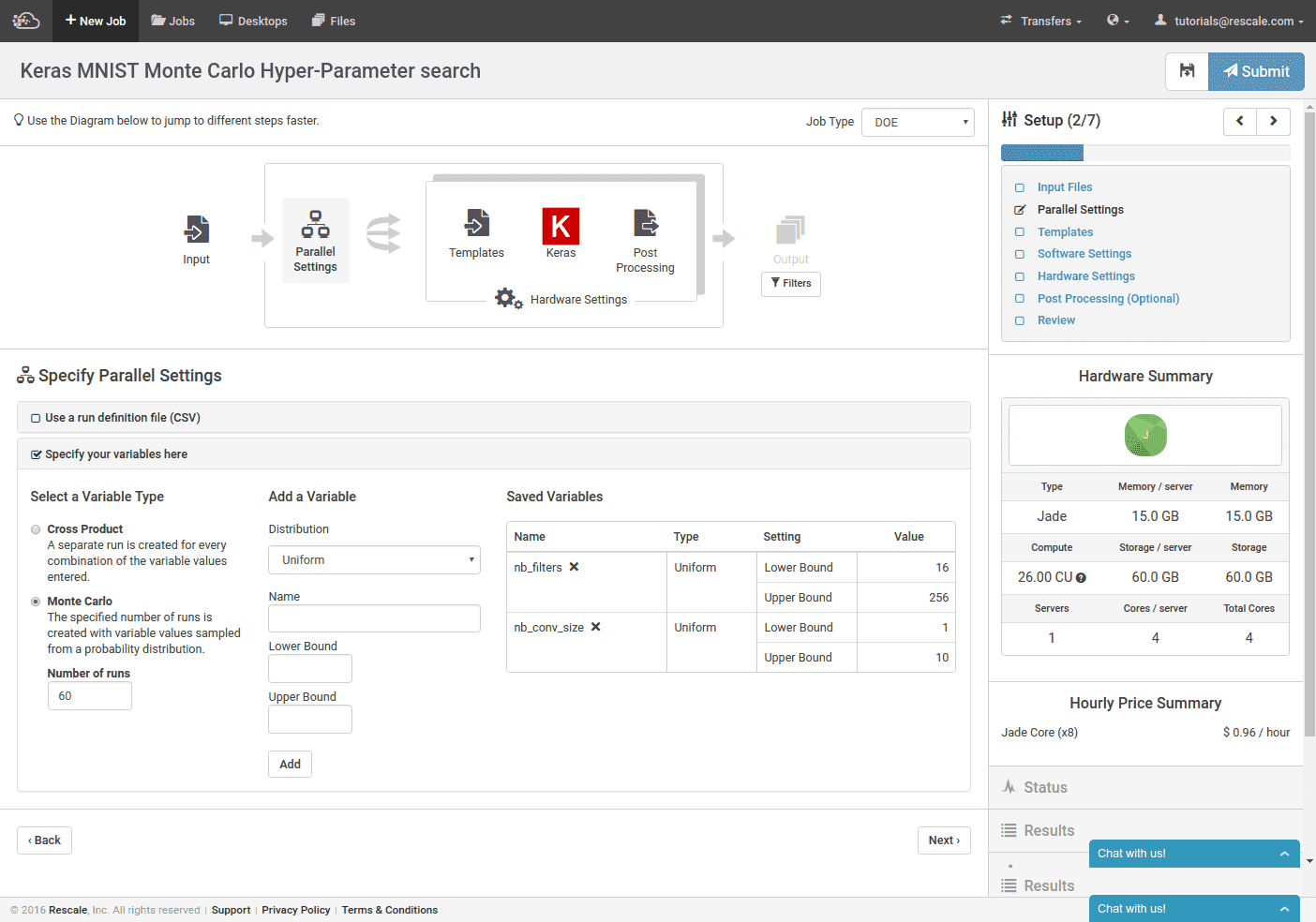
次に、モンテカルロ DOE (左下) を実行していること、60 の異なるトレーニング実行を実行することを指定し、テンプレート変数を指定します。 一様分布からサンプリングする両方のパラメータをやや恣意的に選択します。 畳み込みカーネルのサイズの範囲は 1 ~ 10 (各画像サイズは 28×28 であるため、28 を超えると機能しません)、畳み込みフィルターの数の範囲は 16 ~ 256 です。
代わりに CSV を使用してテンプレート変数の範囲を指定できることに注意してください。 この例では、変数のランダムな値を手動でサンプリングします。CSV は次のようになります。
Nb_filters、nb_conv_size 16、3 45、8 32、4 ...
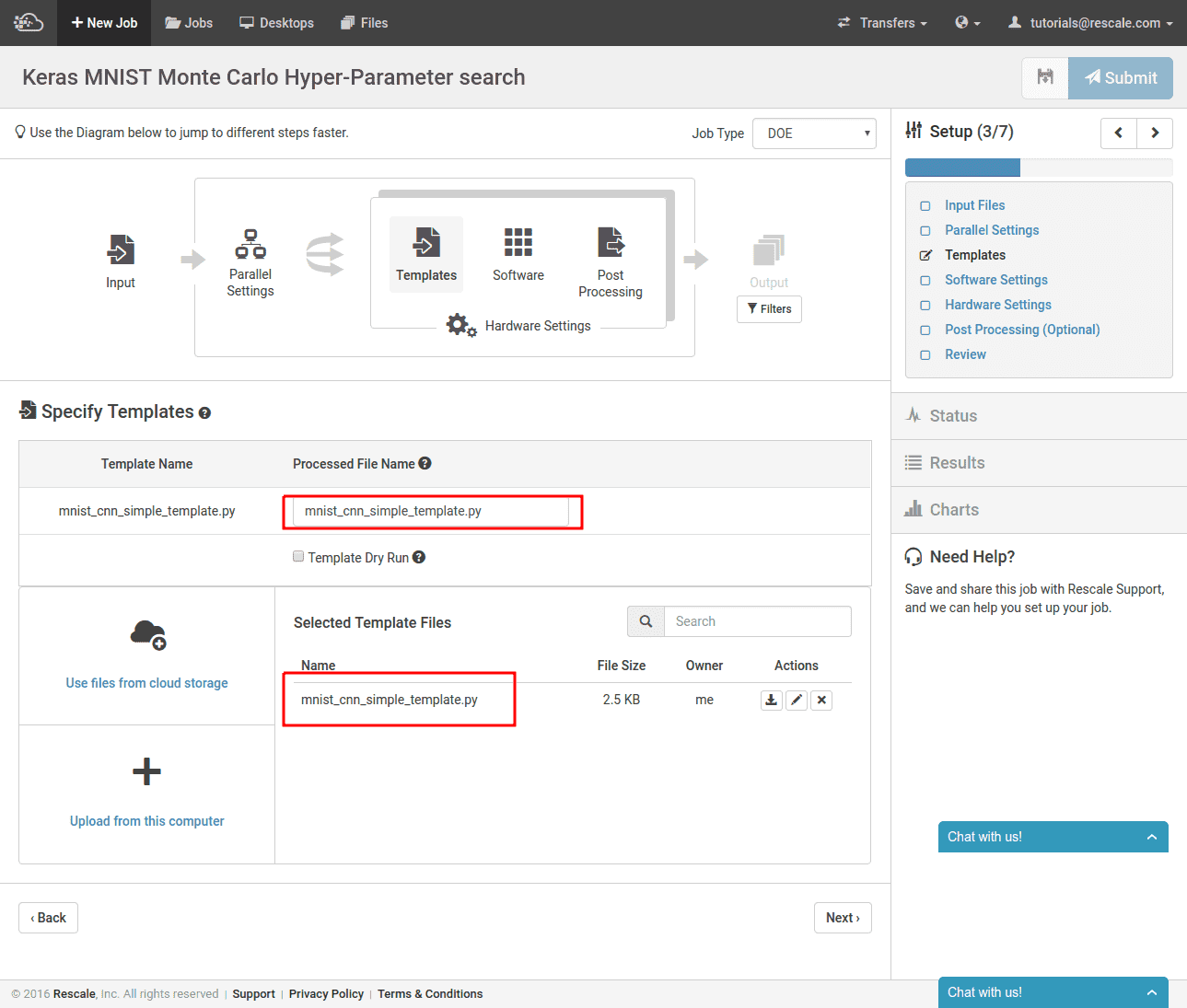
次に、上で作成した Keras スクリプト テンプレートをアップロードする必要があります。 この時点で、挿入された値を使用してスクリプトの新しい名前を指定することもできます。 ここで行ったように、名前を同じにしたいだけの場合も問題ありません。 マテリアライズされたバージョンはテンプレートを上書きしません。
使用するトレーニング ライブラリを選択します。 検索ボックスで「Keras」を検索し、選択します。 次に、K520/Theano 互換バージョンを選択します。 最後に、コマンド ラインを入力してトレーニング スクリプトを実行します。 コマンドの最初の部分は、MNIST データセット アーカイブを Keras が見つけられる場所にコピーするだけです。 あとは、Python スクリプトを呼び出すだけです。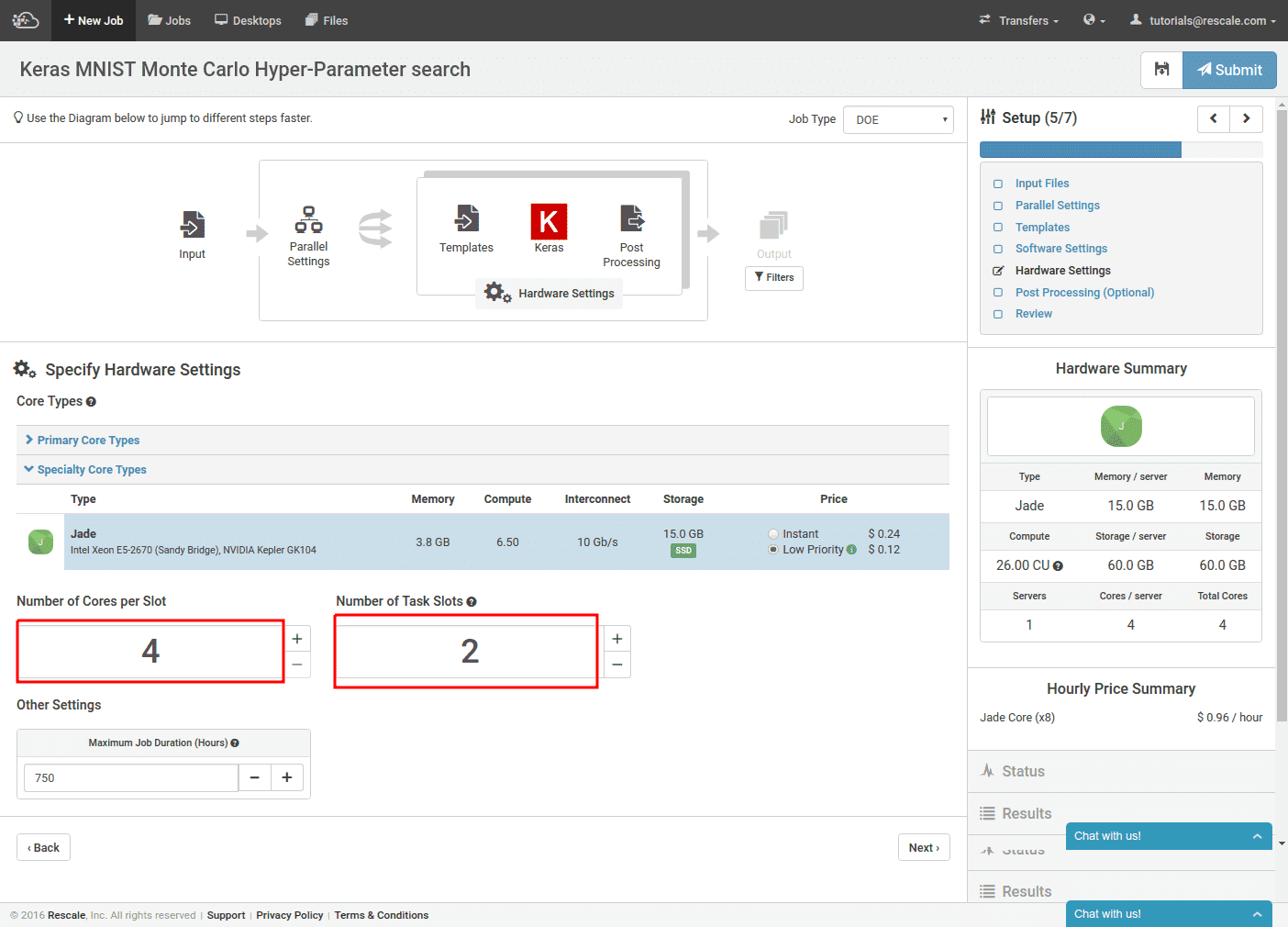
K520 で動作するように構成された Keras のバージョンを選択したため、ハードウェア タイプはすでに Jade に絞り込まれています。 左側で各トレーニング クラスターのサイズを設定できるようになりました。 ここでのカウントは CPU コアの数です。 Jade ハードウェア タイプの場合、各ハードウェアに 4 つの CPU コアがあります。 GPU。 右側では、プロビジョニングする個別のトレーニング クラスターの数を設定します。 この場合、クラスターごとに 2 つの GPU を備えた XNUMX つのトレーニング クラスターを使用しています。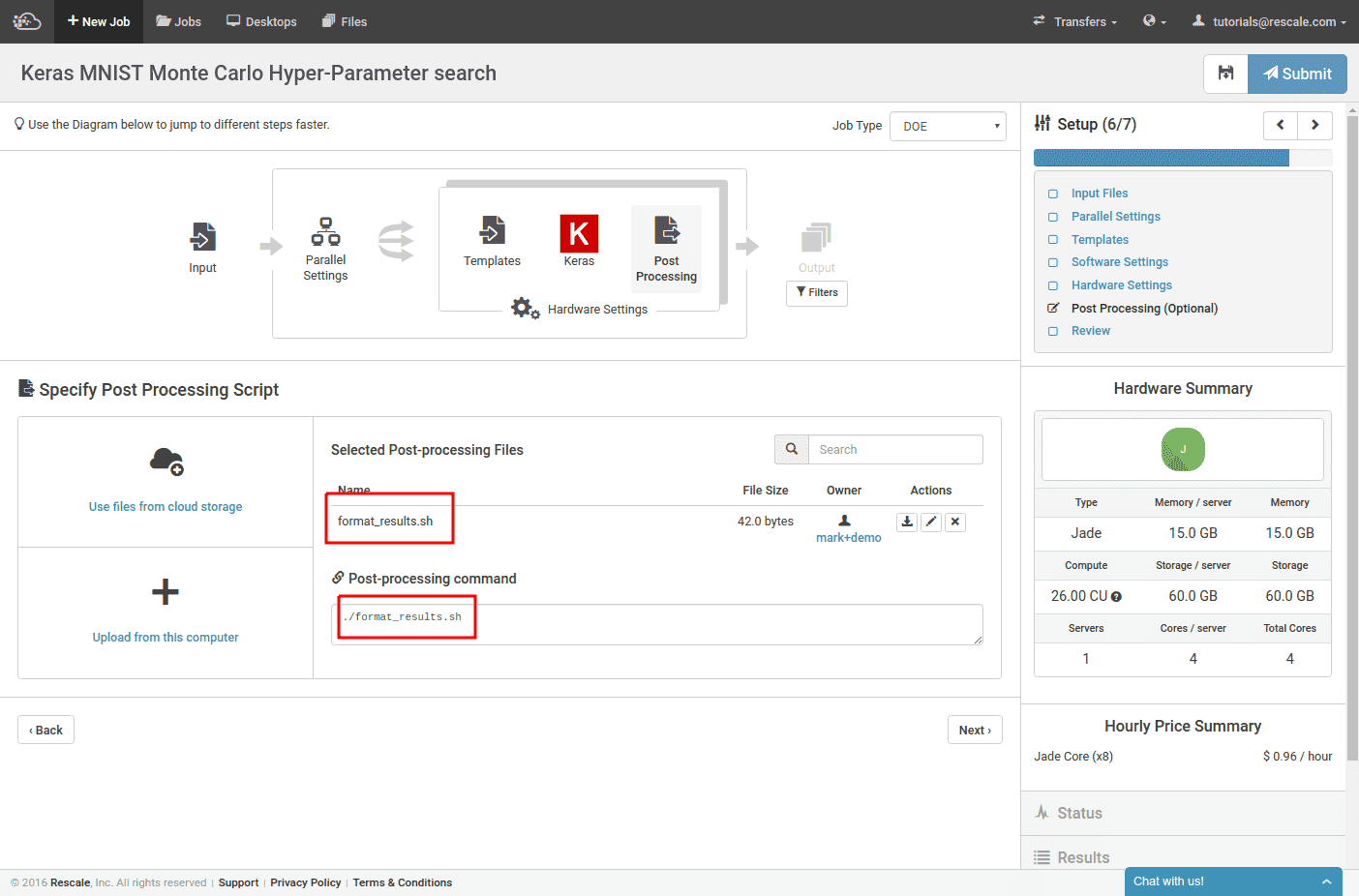
最後のステップは、後処理スクリプトを指定することです。 このスクリプトは、トレーニング ジョブの出力を解析し、後で表示する結果ページに表示するために Rescale で使用できるメトリクスを作成するために使用されます。 予期される出力形式は、値ごとに XNUMX 行です。
[名前]\t[値]
トレーニング スクリプトは出力の最後の行として適切にフォーマットされた精度をすでに出力しているため、 結果出力後処理スクリプトは最後の行を解析するだけで済みます。
右上でジョブを送信できるようになり、リアルタイム クラスター ステータス ページに移動します。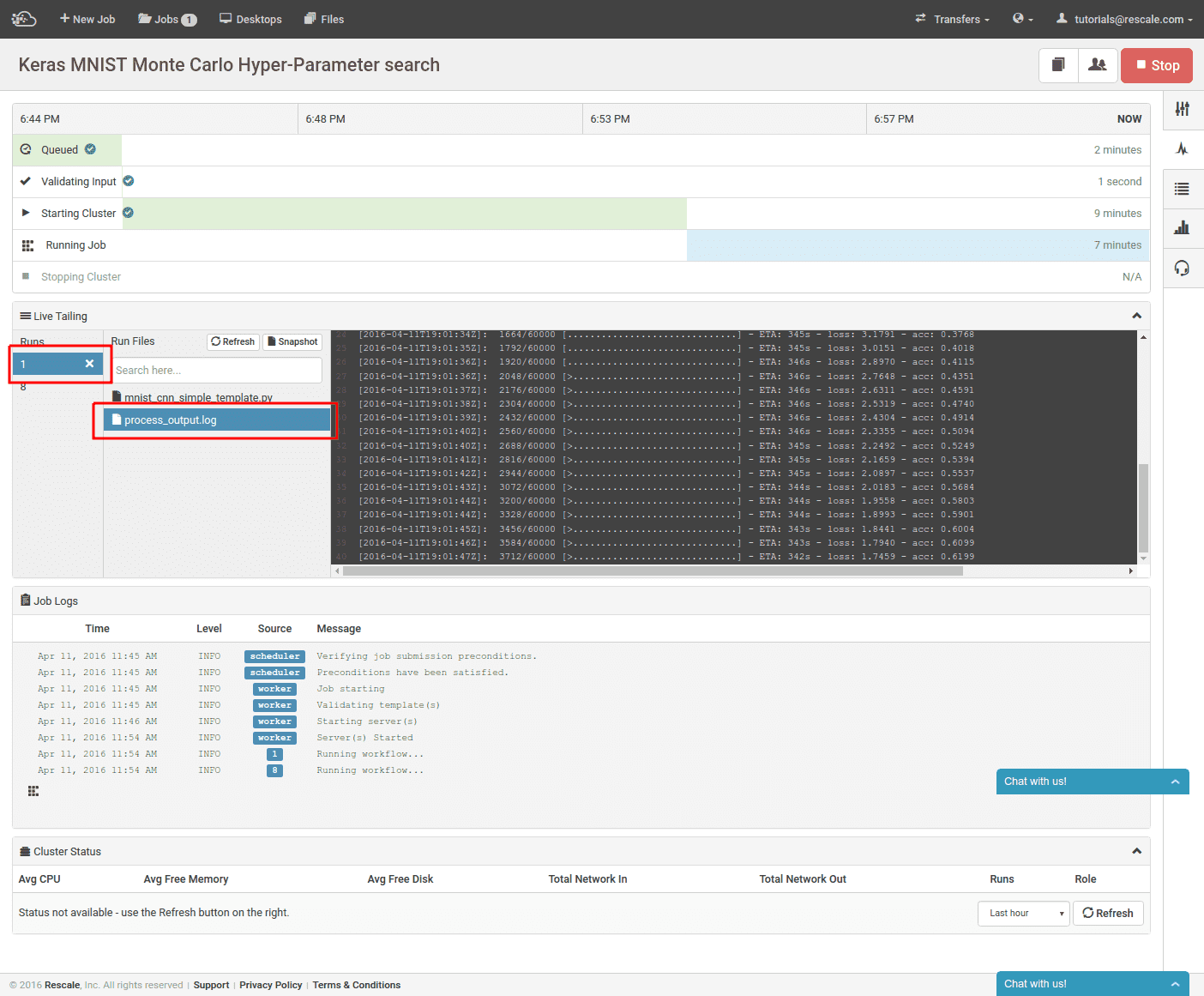
クラスターがプロビジョニングされ、ジョブが開始されると、トレーニング ジョブの進行状況を確認できます。 ライブ テーリング ウィンドウで実行を選択し、 process_output.log。 トレーニングがすでに開始されている場合は、トレーニングの進行状況と現在のトレーニングの精度を表示できます。 選択した実行番号の横にある「x」を選択することで、個々の実行を手動で終了できます。 これにより、パラメータの精度が明らかに低い場合に、ユーザーは実行を早期に停止できます。
ジョブが完了すると、結果ページに各実行に使用されたハイパーパラメータと精度の結果が要約されます。 上記のケースでは、Keras の例から取得した最初のモデルの精度は 99.1% でしたが、得られた最良の結果の精度は約 99.4% で、若干の改善が見られました。 最も正確なモデルの重みをダウンロードしたい場合は、精度順に並べ替えて、実行の詳細を選択できます。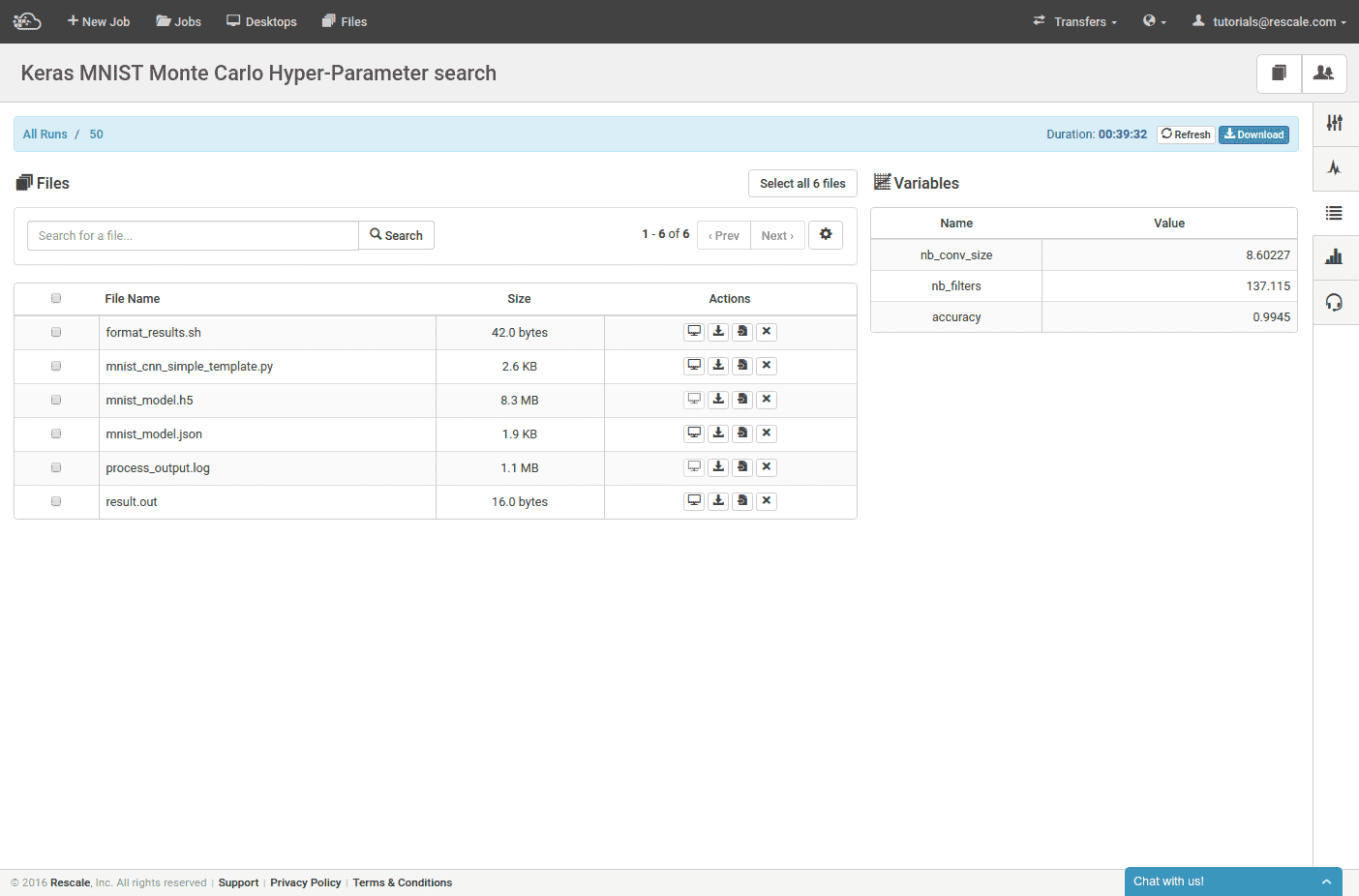
他の結果ファイルには次のようなものがあります。 mnist_model.json & mnist_model.h5これらは、モデルを Keras に再ロードするために必要なモデル アーキテクチャ ファイルとモデルの重みファイルです。 すべての実行からのすべてのデータを XNUMX つの大きなアーカイブとしてダウンロードしたり、結果テーブルを CSV としてダウンロードしたりすることもできます。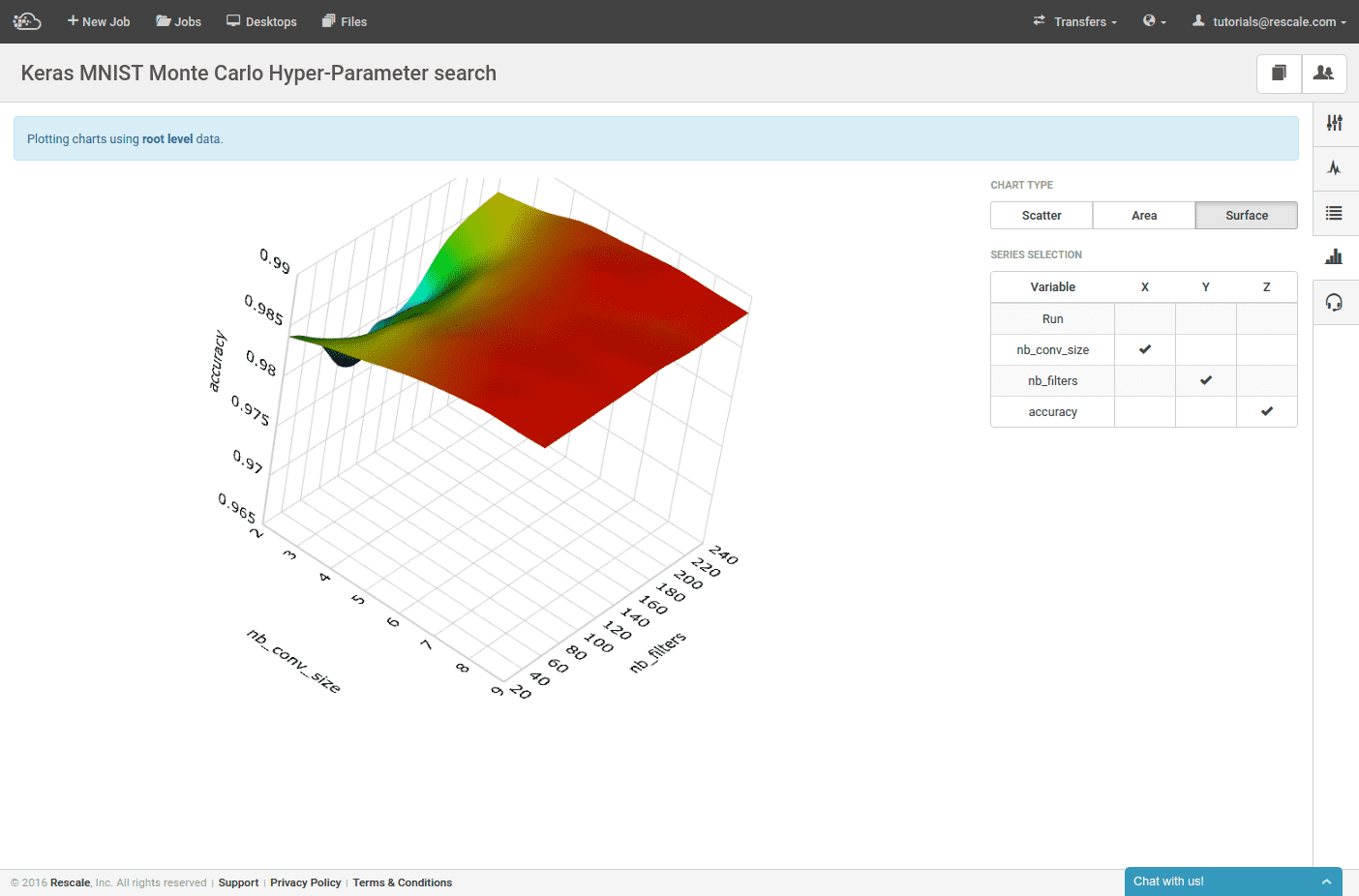
精度の結果は、グラフタブで視覚化することもできます。
独自のハイパーパラメーター オプティマイザーを導入する
Rescale は、詳細に記載されているように、サードパーティの最適化ソフトウェアの使用をサポートしています。 ここ。 次に、機械学習の文献に基づいてブラックボックス オプティマイザーを実行するための Rescale 最適化ジョブの作成について説明します。
Rescale 最適化 SDK を使用して、 Sequential Model-based Algorithm Configuration (SMAC) オプティマイザー ブリティッシュコロンビア大学出身。 SMAC オプティマイザーは、ハイパーパラメーターの選択に基づいて、ニューラル ネットワークのパフォーマンスのランダム フォレスト モデルを構築します。 バージョン 2.10.03 を使用します。 ここ.
オプティマイザーは、次の構成をとる Java アプリケーションです。
- 「シナリオ」ファイル: 実行するオプティマイザーのコマンド ラインを指定します。この場合、これはネットワーク トレーニング スクリプトです。
- パラメータ ファイル: ハイパーパラメータの名前と値の範囲を指定します。
SMAC がトレーニング スクリプトを実行するとき、現在のハイパーパラメータの選択を渡してコマンド ライン フラグとして評価します。 実行結果は、次のような文字列形式で stdout で受け取ることが期待されます。
このアルゴリズムの実行結果: 、 、 、 、 、
まず、この実験で変更するハイパーパラメータのパラメータ ファイルを作成します。
nb_filters 整数 [4、256] [32] nb_conv 整数 [1、20] [3] nb_pool 整数 [1、20] [2] ドロップアウト 1 実数 [0、1] [0.25] ドロップアウト 2 実数 [0、1] [0.5]
ここで、畳み込みフィルター数と畳み込みカーネル サイズを変更することに加えて、ドロップアウト率とプーリング層のサイズも変更します。
ここで、SMAC の入力と結果に対応するために以前のトレーニング スクリプトに加えられた変更を見てみましょう。
parser = argparse.ArgumentParser() parser.add_argument('-nb_filters', dest='nb_filters', type=int) parser.add_argument('-nb_pool', dest='nb_pool', type=int) parser.add_argument(' -nb_conv', dest='nb_conv', type=int) parser.add_argument('-dropout1', dest='dropout1', type=float) parser.add_argument('-dropout2', dest='dropout2', type= float) parser.add_argument('other', nargs='+')
ハイパーパラメータ値をテンプレートとして挿入するのではなく、argparse を使用して SMAC によって提供されるフラグを解析するようになりました。
(X_train_orig, y_train_orig), (X_test, y_test) = mnist.load_data() X_train = X_train_orig[:50000] y_train = y_train_orig[:50000] X_val = X_train_orig[50000:] y_val = y_train_orig[50000:]
オプティマイザーにエラーを入力し、オプティマイザーがそのエラーに基づいて新しいパラメーターを選択するため、検証データセットとテスト データセットを別々に保持するようになりました。 上記では、元のトレーニング データをトレーニング セットと検証セットに分割しています。 オプティマイザによるオーバーフィットの危険性のない評価対象のエラー メトリックを得るために、別のテスト データセットを保持することが重要です。 最適化アルゴリズムは検証エラーのみを確認します。
model.fit(X_train, Y_train,batch_size=batch_size, nb_epoch=nb_epoch, show_accuracy=True,verbose=1, validation_data=(X_val, Y_val)) val_score = model.evaluate(X_val, Y_val, show_accuracy=True,verbose=0) test_score = model.evaluate(X_test, Y_test, show_accuracy=True,verbose=0) e としての例外を除く: print(e) print('トレーニング実行中のエラー') satisfiable = False 最終的に: json = model.to_json() open(' mnist_model.json', 'w').write(json) model.save_weights('mnist_model.h5') print('テスト エラー:', 1 - test_score[1]) print('Val エラー:', 1 - val_score [1]) print('アルゴリズム実行の結果: {0}, {1}, {2}, {3}, {4},'.format( 満足できる場合は 'SAT'、それ以外の場合は 'UNSAT', time.time( ) - t0, 1, 1 - val_score[1], 1337 ))
ここでは、モデルをトレーニングし、検証およびテスト データセットで評価し、結果を SMAC 固有の形式で出力します (「アルゴリズムの結果…」)。 また、トレーニングと検証でのエラーもキャッチし、SMAC に対して「UNSAT」として実行されるマークを付けます。これにより、SMAC はパラメータの無効な組み合わせであることが認識されます。
SMAC が Rescale python SDK を呼び出すために、smac_opt.py という名前のラッパー スクリプトを作成し、SMAC がそれを呼び出すようにシナリオ ファイルで指定します。 次に、ラッパーは、実行するトレーニング スクリプトを送信します。
ラッパー スクリプトからの重要な抜粋をいくつか示します。
if __name__ == '__main__': print object_function(sys.argv[1:])
まず、スクリプトに渡されたすべてのコマンド ライン フラグを取得し、目的関数に直接渡します。 これは、ハイパーパラメータの各セットに対して呼び出される目的関数です。
def object_function(X): iteration = os.getpid() # 各反復に独自のファイルを与える run_dir = 'run-{0}'.format(iteration) Output_file = 'output-{0}'.format(iteration) copy_input( 'input', run_dir) # パッケージ化しましょう zip_file = 'run.zip' filezip(run_dir, zip_file) # オプティマイザーノードにディレクトリを保持する必要はありません shutil.rmtree(run_dir)
目的関数を開始するには、このトレーニング実行の入力ファイルを .zip ファイルにパッケージ化します。
コマンド = 'python mnist_cnn_smac.py {0} | python format_results.py > {1}' command = concatenate_shell_commands( 'unzip ' + zip_file, 'rm ' + zip_file, 'cd ' + run_dir, COMMAND.format(' '.join(X), '../' + Output_file ), 'cd ..' ) run = rescale.submit( コマンド、input_files=[zip_file]、output_files=[output_file]、var_values=get_val_dict(X) ) run.wait()
ここでは、実行するトレーニング スクリプト コマンドをフォーマットします。 SMAC (変数 `X`) からトレーニング スクリプトにフラグを渡しているだけであることに注意してください。 次に、入力ファイルをトレーニング クラスターに送信してトレーニングを開始する submit コマンドを呼び出します。 また、`format_results` スクリプトを自分たちで呼び出すようになりました。
# 出力から目的関数の値を取得し、open(output_file) の行の Rescale に保存します: if re.match('Result of .*algorithm run.*', line): results = line m = re.match('テスト エラー: ([\de\.-]+).*', line) if m: testerr = float(m.group(1))quality = results.split(', ')[3] run.report( {'testerr': float(testerr), 'valerr': float(quality)}) 結果を返します
トレーニング スクリプトからの出力ファイルを解析して、予想される SMAC 結果行 (「アルゴリズム実行の結果…」) とテスト データセットのエラーを取得します。
最後に、SMAC にラッパー スクリプトを呼び出すように指示するシナリオ ファイルを指定する必要があります。
use-instances = false runObj = QUALITYnumberOfRunsLimit = 100 pcs-file = params.pcs algo = ./smac_opt.py check-sat-consistency = false check-sat-consistency-Exception = false
ここでの重要な部分は次のとおりです。
- pcs-file: パラメータを指定します
- algo: 実行するラッパー スクリプト
- numberOfRunsLimit: トレーニングの実行数を設定します。
- check-sat-consistency: 同じトレーニング データセットに対して、異なるパラメーターを選択すると、実行可能なモデルまたは実行不可能なモデルが生成される可能性があることをオプティマイザーに伝えます。
- これで入力ファイルがすべて揃ったので、ジョブを作成する準備が整いました。
ここでジョブのクローンを作成して自分で実行できます。
Keras MNIST SMAC オプティマイザー
input.tar.gz アーカイブは、mnist_cnn_smac.py トレーニング スクリプトと format_results.py 後処理スクリプトを含む input/ ディレクトリで構成されます。
以前と同じソフトウェアを選択し、Keras が K520 上の Theano 用に構成されました。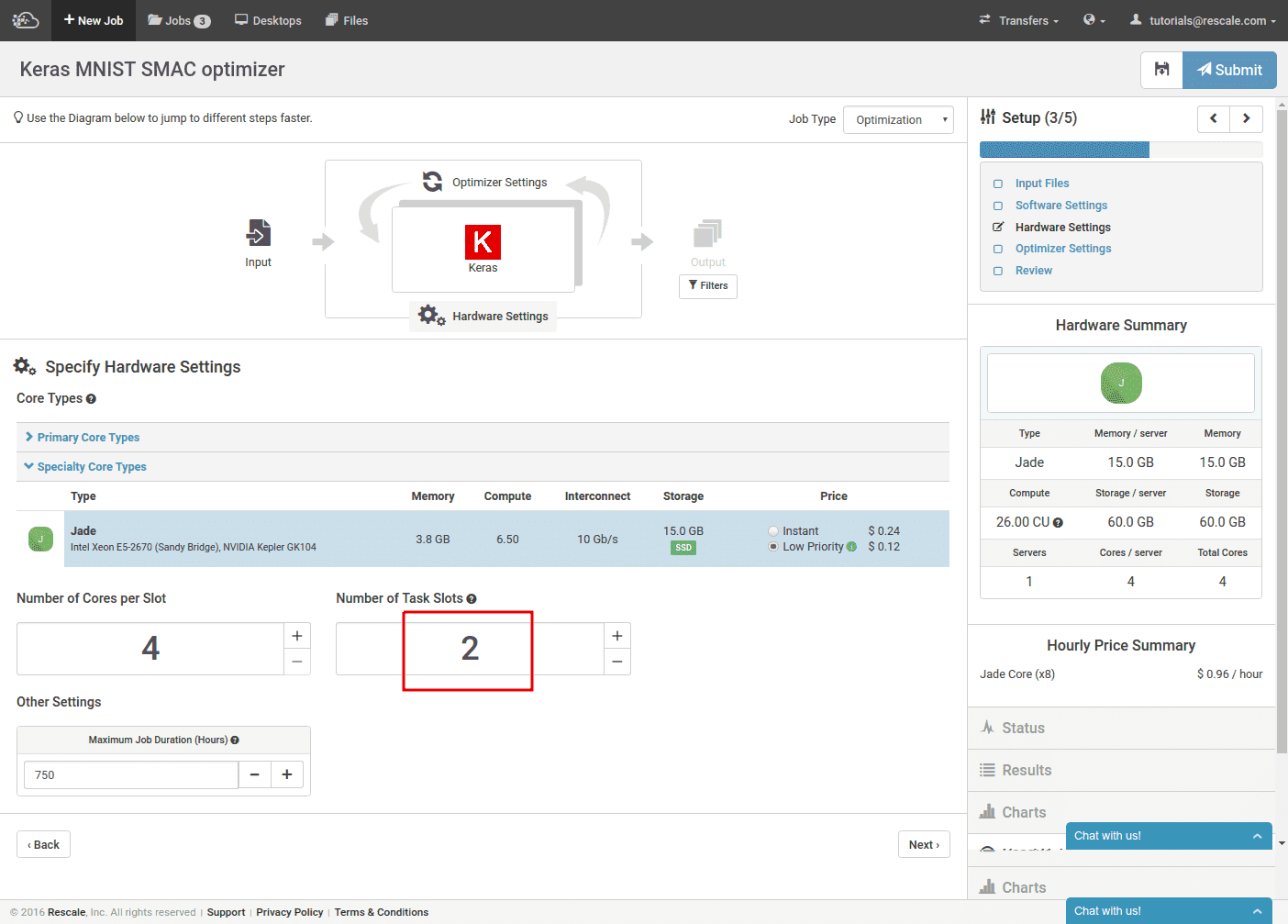
ハードウェアの選択もほぼ同じです。 2 つのネットワークを並行してトレーニングするために、再び 2 つのタスク スロットを選択します。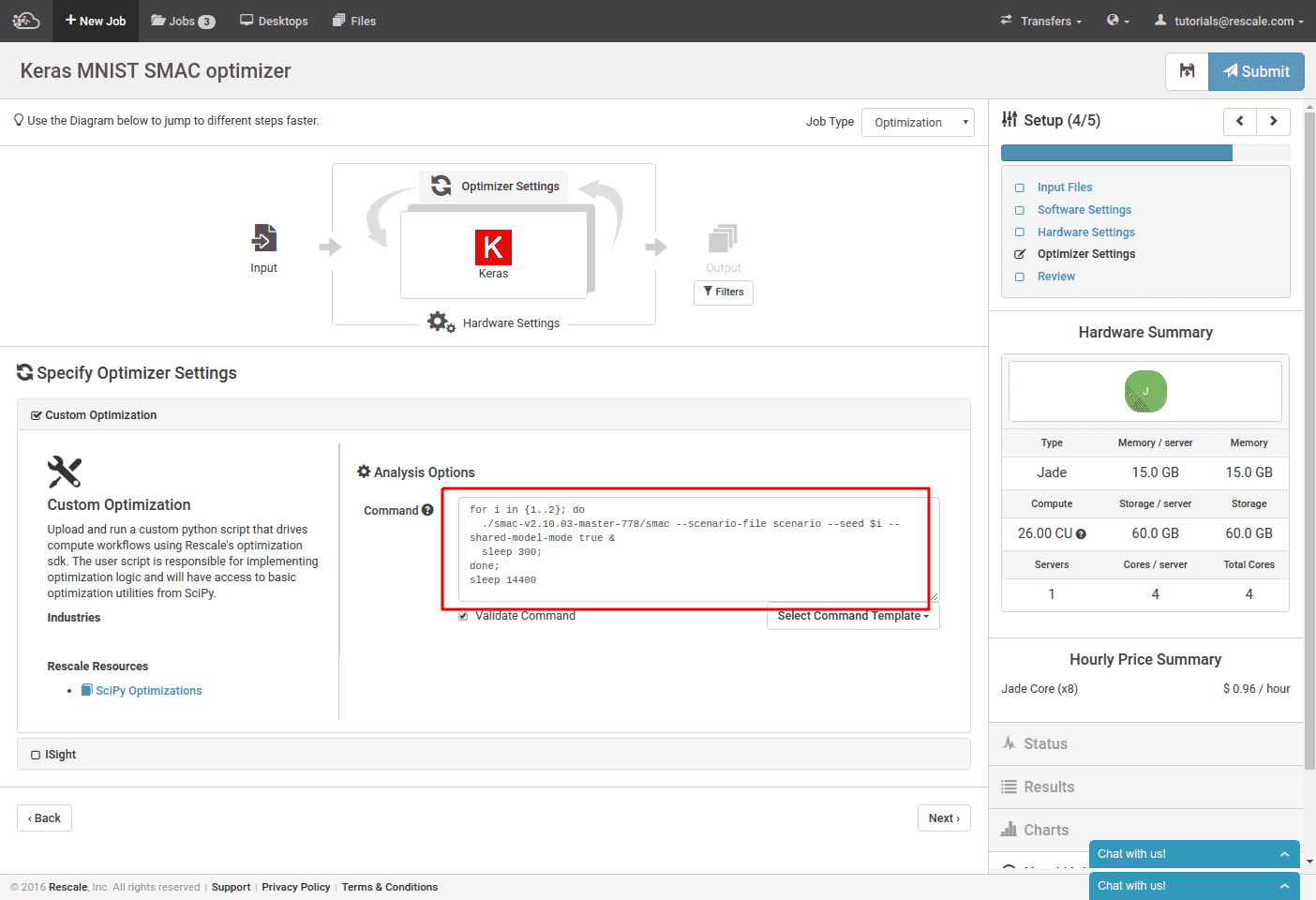
オプティマイザーでは、「カスタム最適化」を選択し、コマンド ラインを入力して SMAC を実行します。 このコマンドは、各 SMAC プロセスが一度に XNUMX つの反復しか実行しないため、複雑になります。 複数のトレーニングを並行して実行するには、SMAC の「共有モデル モード」を使用する必要があります。 このモードをオンにすると、SMAC は現在のディレクトリで他の SMAC プロセスからのオプティマイザ結果を定期的にチェックし、それらの結果を組み込むように指示されます。 このモードでは、「-seed」を SMAC プロセスごとに異なる値に設定する必要があります。
複数のオプティマイザー プロセスを一度に実行する必要があるため、すべての呼び出しをバックグラウンドで実行し、このオプティマイザーを実行したい最大時間スリープします。 この場合、4時間待ちとなります。
このジョブは送信する準備ができました。 実行後は、現在の反復をライブで実行し、最後に、前のランダム化の場合と同様に結果を表示できます。 結果には、ハイパーパラメータの各セットの検証エラーとテストエラーの両方が表示されます。
まとめ
この記事では、ニューラル ネットワークのハイパーパラメーターの空間を検索する 2 つの方法を示しました。 XNUMX つはランダム化検索を使用し、もう XNUMX つは Rescale 最適化 SDK を利用したより高度な最適化ツールを使用しました。






