

軽量の Azure InfiniBand クラスターのセットアップ

クラウドでHPCに対して平準化された重要な批判のXNUMXつは、オンプレミスクラスターと比較した場合、ノード間の比較的遅い相互接続速度です。 多くのニッチプロバイダーがこのギャップに対処するためのインフィニバンド接続を提供していますが、マイクロソフトはこのタイプの高帯域幅、低遅延の相互接続を新しいものと提供する最初の主要プロバイダーです ビッグコンピューティング 解決。 大規模なデータセンターを管理しながら、企業がワークロードをクラウドに移行するために必要なセキュリティコンプライアンスの問題や認証にも対処できるリソースを備えている企業は比較的少ないため、これは興味深いニュースです。 公正かどうかにかかわらず、Microsoft、Amazon、またはGoogleの支援を受けることで、企業のITバイインを取得することに大きな違いが生じる可能性があります。
による スペック、新しい A8 および A9 インスタンス サイズは、RDMA による InfiniBand 接続を提供します。 この最後のビットは、特に重要です このブログ記事 正しく指摘されていますが、InfiniBand だけでは十分ではありません。 使用されているトランスポートによって重大な違いが生じ、TCP のパフォーマンスは非常に低下します。 Microsoft によると、Big Compute インスタンスは、ベアメタルに近いパフォーマンスを提供する仮想化 RDMA をサポートしています。 この発表は、クラウドで密結合シミュレーションを実行したいと考えているユーザーにとっては恩恵となるはずです。 このタイプの「おしゃべりな」MPI アプリケーションは、基盤となるネットワークの遅延の影響を非常に受けやすくなります。 しかし、プラットフォームを試してみると、現在のプラットフォームには参入障壁がいくつかあると思います。
まず、RDMA機能は、MS-MPI – MicrosoftのMPI実装によってのみサポートされているNetwork Directというインターフェイスを介して公開されます。 これらのライブラリに対してアプリケーションを再コンパイルする必要があります。 MPIは明確に定義された標準であり、MS-MPIはMPICHに基づいているため、これはそれほど大きくはありません。これは広くサポートされています。 ただし、より大きな問題は、Windowsで実行するにはアプリケーションを書き込む必要があることです。 ありがたいことに、今日使用されている人気のあるエンジニアリングアプリケーションの多くには、MS-MPIをサポートするWindowsバージョンが既にあります。 少なくとも逸話的には、アプリケーションをで再コンパイルできるようです 少ない労力.
第 XNUMX に、MPI クラスターの構成は、Windows の世界と Linux の世界では大きく異なります。 Windows は確かに素晴らしいパフォーマンスを発揮することができますが、 MPIベンチマーク 数字では、HPC開業医の大部分が現在Linuxで実行されています。 Linux用のクラウド内のMPIクラスターの構成は、通常、次のように要約します。「インスタンスを起動し、パッケージマネージャーを使用して選択のMPIフレーバーをインストールし、クラスター内のすべてのノードにパスワードレスSSHを設定し、MachineFileを作成します」。 Windowsでは、推奨されるアプローチは、WindowsサーバーボックスにHPCパックをインストールして構成することです(前提またはクラウド内)。 これは、Linuxに精通している人にとって困難であり、Windows Server管理のニュアンスに精通していません。 HPCパックソリューションは堅牢でフル機能がありますが、いくつかのベンチマークや単純なXNUMX回限りのシミュレーションを実行したい場合、少しヘビー級を感じます。 いいことは、ようなツールです スタークラスター Active Directoryを構成することなく、できるだけ早く人々を育てて実行するには、SQL Serverをインストールするか、PowerShellとREST APIを把握します。
HPCパックなしでAzureにMS-MPIをインストールできることがわかりますが、これを行う方法については多くのガイダンスがあるようには見えません。 さらに、Windows に移植された SSH サーバーと UNIX ユーティリティが多数あります。 別のHPCパックインスタンスをインストール、構成、および管理することなく、WindowsでMPIクラスターを起動する簡単な方法が必要でした。 最終的に実験したのは、PAASオファーを使用して、各ノードで次の操作を実行するために一連の起動タスクを含むクラウドサービスを展開することでした。
- MS-MPI をインストールします (スタンドアロン インストーラーが利用可能です) ここ)
- SMPDを起動します
- OpenSSHサーバーとUNIXコマンドラインユーティリティの標準セットをインストールして構成する
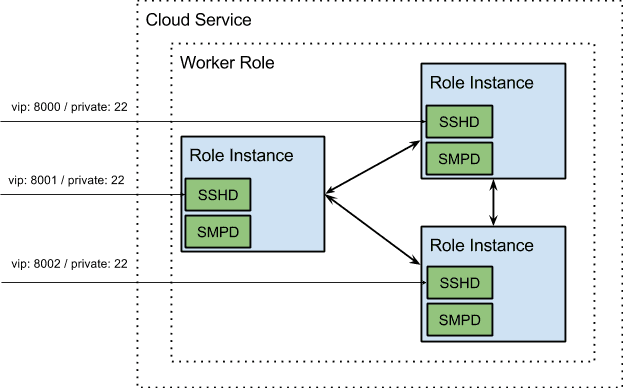
各クラウドサービスには、単一の仮想IP(VIP)が割り当てられています。 これを回避するために、インスタンス内部エンドポイントを使用して、ユーザーが異なるポートを使用して個々のノードにSSHをsshできるようにしました。 内部エンドポイントが開かれ、各ロール インスタンスが他のロール インスタンスで実行されている SMPD デーモンに接続できるようになります。 これらすべての最終結果は、展開が簡単な .cspkg ファイルとそれに付随する構成 XML です。 ユーザーは SSH でロール インスタンスに接続し、使い慣れた UNIX コマンドを使用できます。
2 A9インスタンスに対していくつかのレイテンシと帯域幅のベンチマークを実行したかったのです。 まず、OSU Microbenchmark ライブラリの osu_latency ベンチマークと osu_bibw ベンチマークを MS-MPI に対して再コンパイルしました。 次に、上記のクラウドサービスを展開し、SCPを使用して各マシンにベンチマーク実行可能ファイルをコピーしました(移動する必要がある大きなファイルがある場合、SCPは実行可能なソリューションではないことに注意してください。 。 最後に、ノードの XNUMX つに SSH 接続して、実行可能ファイルを起動しました。
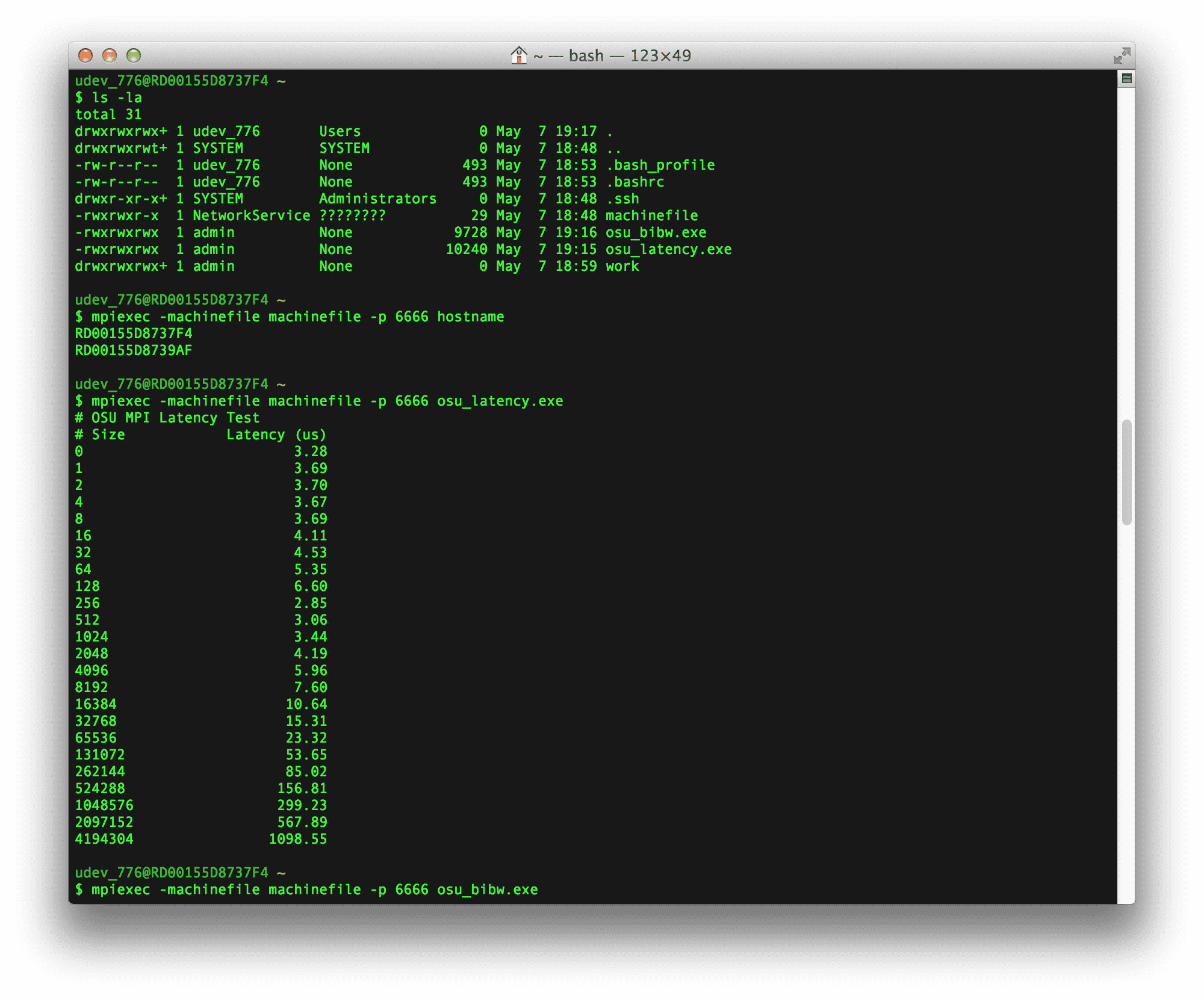
ベンチマークの結果は以下にあります。 ご覧のとおり、0バイトのレイテンシ数は〜3USであり、より大きなメッセージサイズのための双方向の帯域幅テストで〜7.5GB/sが転送されています。これは完全な飽和にかなり近いものです。
# OSU MPI Latency Test
# Size Latency (us)
0 3.28
1 3.69
2 3.70
4 3.67
8 3.69
16 4.11
32 4.53
64 5.35
128 6.60
256 2.85
512 3.06
1024 3.44
2048 4.19
4096 5.96
8192 7.60
16384 10.64
32768 15.31
65536 23.32
131072 53.65
262144 85.02
524288 156.81
1048576 299.23
2097152 567.89
4194304 1098.55
# OSU MPI Bi-Directional Bandwidth Test
# Size Bi-Bandwidth (MB/s)
1 0.43
2 0.87
4 1.69
8 3.35
16 6.82
32 13.69
64 18.64
128 29.12
256 486.75
512 1174.69
1024 2170.21
2048 3844.66
4096 5982.22
8192 2873.87
16384 7078.87
32768 6669.85
65536 4926.26
131072 4878.30
262144 5853.30
524288 6674.26
1048576 7066.08
2097152 7344.74
4194304 7479.30
これらは非常に印象的なパフォーマンス数です。 しかし、大規模な計算使用のための実際の転換点は、MicrosoftがIAASソリューションでLinux VMのサポートを追加すると、一度になると思われます。 オンラインで入手できるドキュメントから、このためのタイムラインが現在何であるかは明らかではありません(Windows ServerのIAASサポートは最近追加されました)。 2014 年に新たな低遅延相互接続戦争がどのように展開するかは興味深いところです。いつものように、Rescale はプロバイダーにとらわれず、顧客に入手可能な最高のハードウェアを提供するつもりです。





