

クイックヒント: 出力ファイルを圧縮する

クラウド HPC の主な課題の XNUMX つは、オンプレミスのマシンとクラウド内のマシンの間で転送する必要があるデータの量を最小限に抑えることです。 従来のオンプレミス システムとは異なり、この転送ははるかに遅く信頼性の低いワイド エリア ネットワーク上で行われます。 すでに触れたように、 前に、最善の方法は、後処理をリモートで実行し、不必要なデータ転送を避けることです。
とはいえ、多くのユーザーにとって一般的なシナリオは、シミュレーションを実行し、ジョブからすべての出力ファイルをワークステーションに転送することです。
ジョブが完了すると、作業ディレクトリ内の各ファイルが暗号化され、クラウド ストレージにアップロードされます。 これにより、出力ファイルの小さなサブセットをマシンにダウンロードするだけで済むユーザーに柔軟性が提供されます。 ただし、そのトレードオフとして、各ファイルの転送時に追加のオーバーヘッドが発生します。 ネットワーク経由でデータを転送する場合、XNUMX つのファイルに詰め込めるデータが多いほど良いです。 さらに、多くのエンジニアリング コードは、圧縮率の高いファイルを生成します。 ファイルの圧縮には余分な時間がかかりますが、圧縮に費やした時間と小さなファイルの転送にかかる時間が、大きな非圧縮アーカイブのアップロードに費やした時間よりも短い場合は、それでも利点が得られます。 圧縮とその後の転送に全体的に時間がかかるとしても、転送プロセス全体における本当のボトルネックは、クラウド ストレージとユーザーのワークステーション間の最後のホップになります。 ここで転送する圧縮ファイルが小さいと、ユーザーのインターネット接続速度に応じて大きな違いが生じる可能性があります。
ジョブのすべての出力ファイルをダウンロードする必要があることが事前にわかっている場合は、一般に、各ファイルを個別に転送するのではなく、最初に単一の圧縮アーカイブ ファイルを生成することが最善です。 Linux tar コマンドを使用すると、圧縮アーカイブを簡単に作成できますが、MPI クラスターで利用可能な追加のコンピューティング能力を使用してアーカイブを生成することはありません。
Jeff Gilchrist は、MPI クラスター上で実行される使いやすい bz2 コンプレッサーを開発しました (https://compression.ca/mpibzip2/)。 静的 bzip2 ライブラリ参照を使用して Linux バイナリをコンパイルし、利用できるようにしました。 ここ 自分の仕事に簡単に組み込めるようにダウンロードしてください。 バイナリは、OpenMPI 1.6.4 mpic++ ラッパー コンパイラを使用してビルドされました。 使用している MPI フレーバーによっては、再コンパイルが必要になる場合があることに注意してください。
これを使用するには、mpibzip2 実行可能ファイルをジョブの追加入力ファイルとしてアップロードします。 次に、ジョブ設定ページの分析コマンドの末尾に次のコマンドを追加します。
tar cf files.tar –exclude=mpibzip2 *
mpirun -np 16 mpibzip2 -v files.tar
探す ! -name 'files.tar.bz2' -type f -exec rm -f {} +
まず、並列 bzip ユーティリティ以外のすべてを含む、files.tar という名前の tar ファイルが作成されます。 次に、mpibzip2 実行可能ファイルを起動し、files.tar.bz2 という圧縮アーカイブを生成します。 最後に、files.tar.bz2 を除くすべてのファイルが削除されます。 これにより、個々のファイルと圧縮アーカイブの両方がクラウド ストレージにアップロードされなくなります。
mpirun 呼び出しの -np 引数は、クラスター内のコアの数を反映する必要があることに注意してください。 ここでは、コマンドは 16 ニッケル コア クラスター上で実行されています。
さらに注意すべき点は、Windows はデフォルトでは bz2 または tar ファイルをサポートしていないことです。 7-Zip をインストールすると、この形式と他の多くの形式のサポートを追加できます。
簡単なテストとして、2.1 ファイルにまたがる 369 GB 相当の出力データを含む圧縮アーカイブを OpenFOAM ジョブから構築し、結果のファイルをクラウド ストレージにアップロードしました。
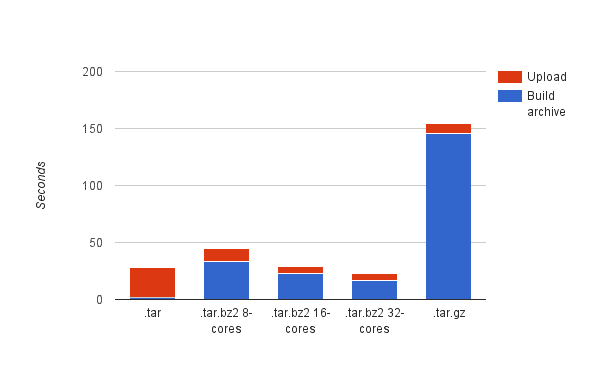
ベースラインとして、非圧縮 tar ファイルを構築しました。 また、tar コマンドで -z フラグを使用して、gzip 圧縮 tar ファイルの作成も試みました。 最後に、2、8、および 16 ニッケル コアを使用して bz32 圧縮アーカイブを構築してみました。
当然のことですが、ベースラインのケースでは、アーカイブの構築にかかる時間はごくわずかで、全体時間の大部分はより大きなファイルのアップロードに費やされます。 ファイルを圧縮すると、全体的な時間の内訳が逆転し、時間の大部分がファイルの圧縮に費やされます。 また、当然のことですが、複数のコアを利用すると、tar コマンドに付属するシングルコアの gzip サポートを使用するよりも大幅に高速化されます。 約 16 コアでは、全体の時間はベースラインの場合とほぼ同じになります。
ただし、圧縮ステップの実際の効果は、圧縮された bz2 ファイルが非圧縮の tar よりもほぼ 5 倍小さい (439 MB 対 2.1 GB) ため、ユーザーが出力をローカル ワークステーションにダウンロードしようとすると明らかになります。
繰り返しになりますが、後処理と視覚化をできるだけクラウドにプッシュすることが、データ転送を最小限に抑える最善の方法であると信じています。 ただし、多数の出力ファイルが必要な場合は、事前に圧縮アーカイブを準備するために少し時間を費やすことで、多くの場合、転送時間を大幅に短縮できます。 将来的には、この投稿で説明した手動手順の多くを自動化し、よりシームレスなプロセスにする予定です。 乞うご期待!




