Rescale에서 Keras를 사용하는 신경망

Rescale은 이제 Theano 기반 Keras를 포함한 다양한 신경망 소프트웨어 패키지 실행을 지원합니다. Keras는 사용자가 신경망을 계층별로 정의하고 훈련하고 검증한 다음 이를 사용하여 새 이미지에 레이블을 지정할 수 있게 해주는 Python 패키지입니다. 이번 포스팅에서는 CNN(컨벌루션 신경망) 기준으로 이미지를 분류합니다. CIFAR10 데이터세트. 그런 다음 이 훈련된 모델을 사용하여 새 이미지를 분류합니다.
우리는 수정된 버전을 사용할 것입니다. Keras CIFAR10 CNN 훈련 예시 수정된 버전의 훈련 스크립트를 단계별로 진행하는 것부터 시작하겠습니다.
CIFAR10 데이터세트
CIFAR10 이미지 분류 데이터 세트를 다운로드할 수 있습니다. 여기에서 지금 확인해 보세요.. 이는 약 60000개의 32×32 픽셀 이미지로 구성되며 각 이미지에는 10개의 카테고리가 제공됩니다. Python 버전의 데이터 세트를 직접 다운로드하거나 Keras의 내장 데이터 세트 다운로더를 사용할 수 있습니다(자세한 내용은 나중에 설명).
다음 코드를 사용하여 이 데이터 세트를 로드합니다.
from keras.datasets import cifar10 from keras.utils import np_utils nb_classes = 10 def load_dataset(): # 훈련 세트와 테스트 세트 간에 섞이고 분할된 데이터 (X_train, y_train), (X_test, y_test) = cifar10.load_data() print ('X_train 모양:', X_train.shape) print(X_train.shape[0], 'train 샘플') print(X_test.shape[0], 'test Samples') # 클래스 벡터를 이진 클래스 행렬로 변환 Y_train = np_utils .to_categorical(y_train, nb_classes) Y_test = np_utils.to_categorical(y_test, nb_classes) X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255 X_test /= 255 return X_train, Y_train, X_테스트, Y_테스트
우리는 cifar10 여기에서 데이터 로더를 사용하여 카테고리 레이블을 원-핫 인코딩으로 변환한 다음 8비트 RGB 값을 0-1.0 범위로 스케일링합니다.
XNUMXD덴탈의 엑스트레인 및 X_테스트 출력은 훈련 및 테스트 세트의 모든 이미지에 대한 RGB 픽셀 값의 numpy 행렬입니다. 50000개의 훈련 이미지와 10000개의 테스트 이미지가 있고 각 이미지는 32개의 색상 채널을 가진 32×3 픽셀이므로 각 행렬의 모양은 다음과 같습니다.
| 엑스트레인 | (50000, 3, 32, 32) |
| Y_트레인 | (50000) |
| X_테스트 | (10000, 3, 32, 32) |
| Y_테스트 | (10000) |
Y 행렬은 10개 및 50000개 이미지 그룹에 대한 10000개 이미지 클래스 중 하나를 나타내는 순서 값에 해당합니다.
| 비행기 | 0 |
| 자동차 | 1 |
| 새 | 2 |
| 방법 | 3 |
| 사슴 | 4 |
| 개 | 5 |
| 개구리 | 6 |
| 말 | 7 |
| 발송 | 8 |
| 트럭 | 9 |
단순화를 위해 이 예에서는 올바른 크기의 이미지에 대해 더 이상 전처리를 수행하지 않습니다. 실제 이미지 인식 문제에서는 일종의 정규화를 수행합니다. ZCA 미백및/또는 지터링. Keras는 이러한 사전 처리 중 일부를 이미지 데이터 생성기 클래스입니다.
네트워크 정의
다음 단계는 훈련하려는 신경망 아키텍처를 정의하는 것입니다.
from keras.models import Sequential from keras.layers.core import Dense, Dropout, Activation, Flatten from keras.layers.convolutional import Convolution2D, MaxPooling2D def make_network(): model = Sequential() model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape=(img_channels, img_rows, img_cols))) model.add(Activation('relu')) model.add(Convolution2D(32, 3, 3)) model.add(Activation(' relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Convolution2D(64, 3, 3, border_mode='same')) model.add (활성화('relu')) model.add(Convolution2D(64, 3, 3)) model.add(활성화('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add (Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(nb_classes )) model.add(Activation('softmax')) 반환 모델
이 네트워크에는 4개의 컨벌루션 레이어와 2개의 Dense 레이어가 있습니다. 추가 레이어를 추가할 수 있고 레이어를 제거하거나 변경할 수 있지만 첫 번째 레이어는 입력 이미지(3, 32, 32)와 크기가 동일해야 하고 마지막 밀집 레이어는 클래스 수와 동일한 수의 출력을 가져야 합니다. 우리는 라벨(10)로 사용하고 있습니다. 마지막 조밀한 층이 다음입니다. 소프트 맥스 출력을 합이 0이 되는 (1, 1) 범위로 압축하는 레이어입니다.
교육 및 테스트
다음으로 네트워크를 훈련하고 테스트합니다.
def train_model(model, X_train, Y_train, X_test, Y_test): sgd = SGD(lr=0.01,decay=1e-6, Momentum=0.9, Nesterov=True) model.compile(loss='categorical_crossentropy',optimizer=sgd) model.fit(X_train, Y_train, nb_epoch=nb_epoch, 배치_크기=batch_size, 유효성 검사_split=0.1, show_accuracy=True, verbose=1) print('테스트 중...') res = model.evaluate(X_test, Y_test, 배치_크기=batch_size , verbose=1, show_accuracy=True) print('테스트 정확도: {0}'.format(res[1]))
여기서 우리가 선택한 확률적 경사하강법 우리의 최적화 방법으로는 교차 엔트로피 손실. 그런 다음 다음을 사용하여 모델을 훈련합니다. 적당한() 방법. 훈련 에포크 수(데이터를 반복하는 횟수)와 배치 크기(네트워크에서 한 번에 평가할 입력 수)를 지정합니다. 배치 크기가 클수록 훈련 중 메모리 사용량이 늘어납니다. 네트워크가 훈련된 후 테스트 데이터 세트와 비교하여 모델을 평가하고 정확도를 인쇄합니다.
모델 저장
마지막으로 훈련된 모델을 나중에 다시 사용할 수 있도록 파일에 저장합니다.
def save_model(모델): model_json = model.to_json() open('cifar10_architecture.json', 'w').write(model_json) model.save_weights('cifar10_weights.h5', overwrite=True)
Keras는 모델 아키텍처 저장(우리의 경우 출력은 무엇입니까?)을 구별합니다. make_network()) 및 훈련된 가중치. 가중치는 HDF5 형식으로 저장됩니다.
Keras는 저장된 모델이 다양한 버전의 Keras 및 Theano에서 호환된다는 것을 보장하지 않습니다. 가능하다면 동일한 버전의 Keras 및 Theano를 사용하여 저장된 모델을 로드하는 것이 좋습니다.
훈련 작업 재조정
이제 내용을 설명했으니 cifar10_cnn.py 우리가 실행할 훈련 스크립트를 사용하면 이미 실행되도록 최적화된 GPU 노드에서 훈련할 Rescale 작업을 생성할 것입니다. NVIDIA GPU. 이 직업은 Rescale에서 공개적으로 사용 가능. 먼저 훈련 스크립트와 CIFAR10 데이터 세트를 업로드합니다.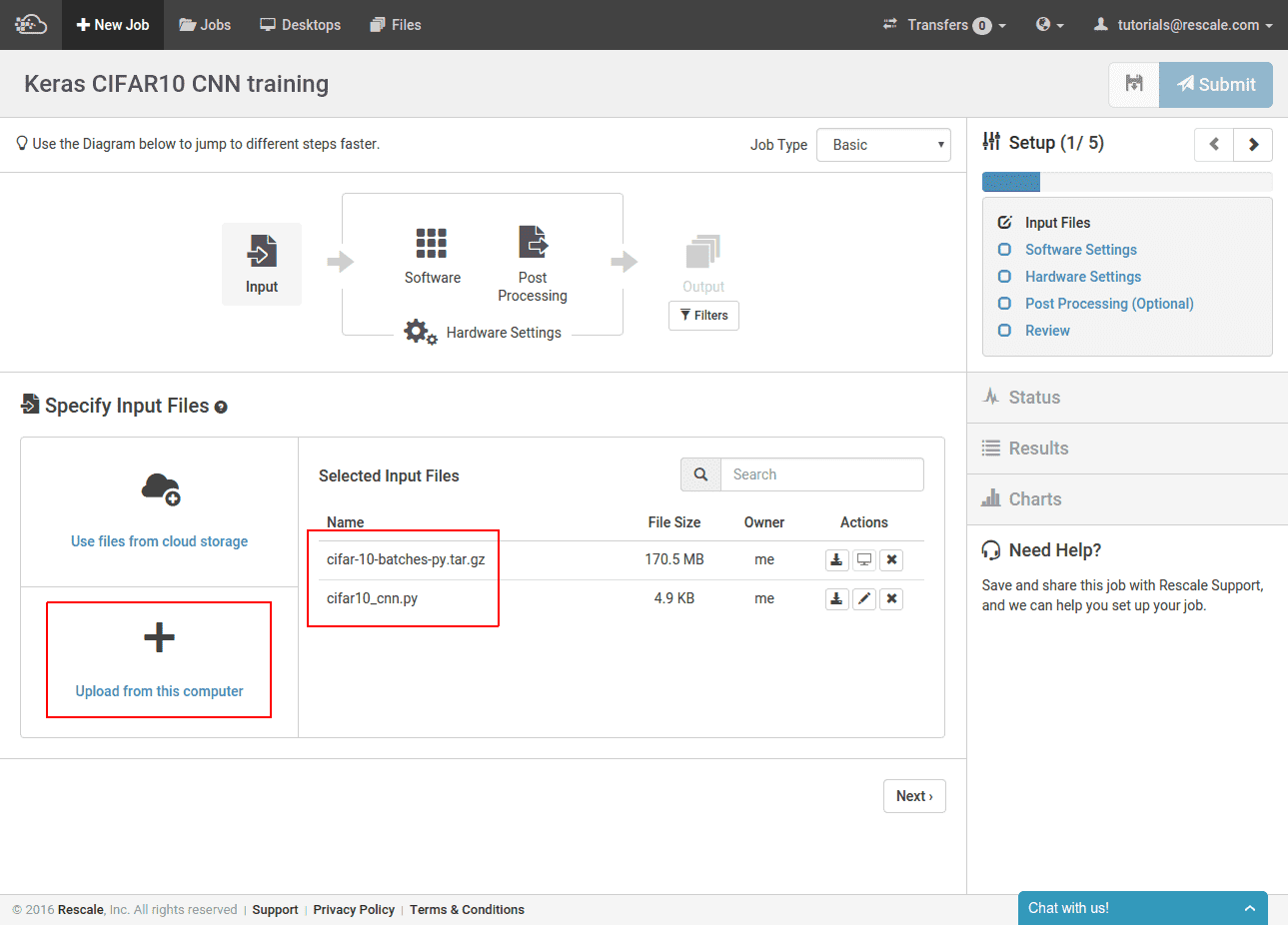
여기서는 작업이 실행될 때마다 CIFAR 사이트에서 데이터세트를 다시 다운로드하는 것을 방지하기 위해 Keras에서 다운로드한 CIFAR10 이미지의 사전 처리된 버전을 업로드합니다. 이 단계는 선택사항이므로 대신 cifar10_cnn.py 스크립트.
다음으로 Keras를 선택하고 명령줄을 지정합니다.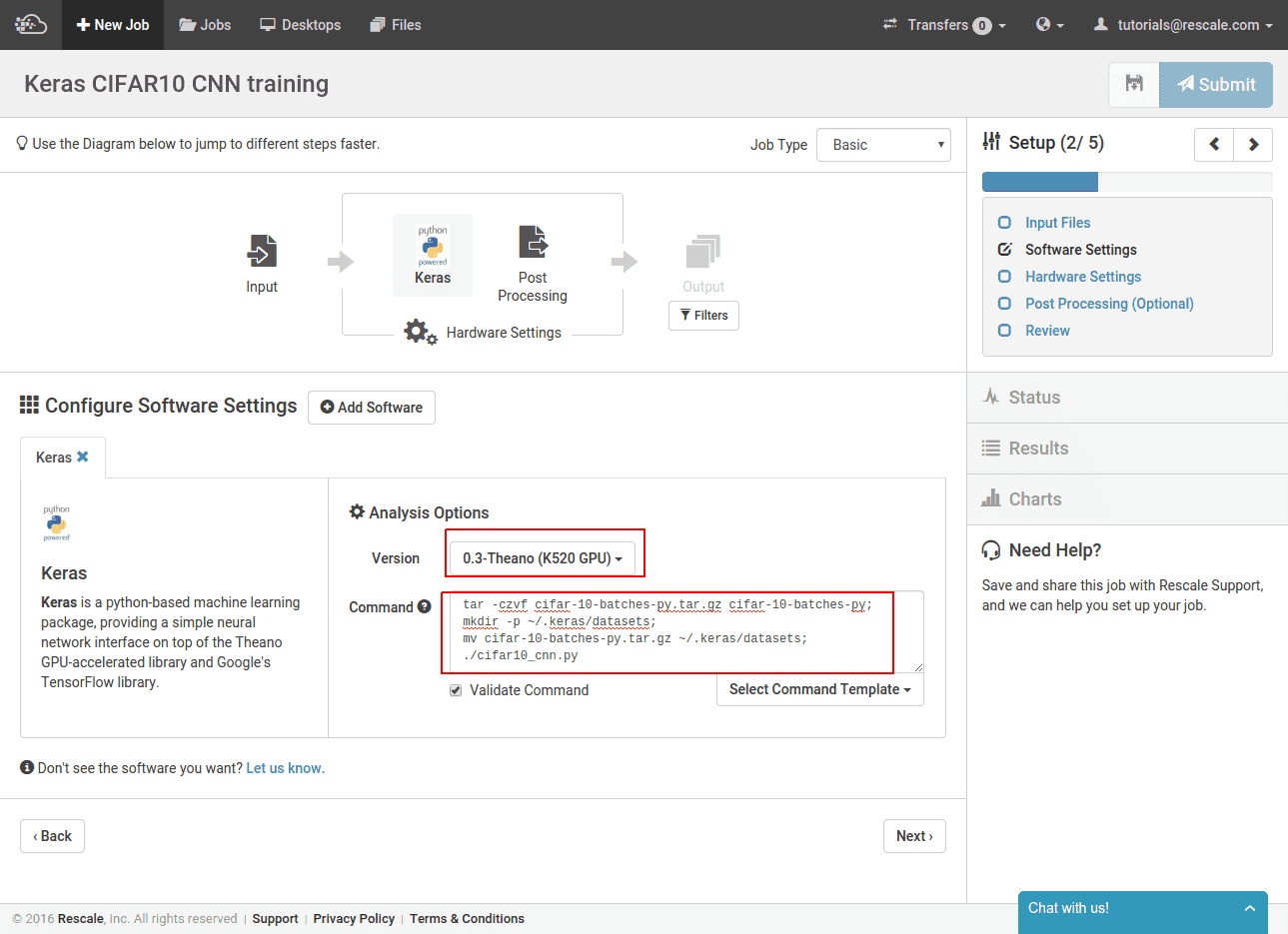
소프트웨어 선택기에서 Keras를 선택한 다음 Theano 지원 K520 GPU 버전의 Keras를 선택합니다. 명령줄은 우리가 업로드한 데이터 세트를 다시 압축한 다음 아카이브를 기본 Keras 데이터 세트 위치로 이동합니다. ~/.keras/datasets. 그런 다음 훈련 스크립트를 호출합니다. CIFAR10 세트를 직접 업로드하지 않기로 결정한 경우 모든 아카이브 조작 명령을 생략하고 교육 스크립트만 실행할 수 있습니다. 그러면 데이터세트가 작업 클러스터에 자동으로 다운로드됩니다.
마지막 단계에서는 실행하려는 GPU 하드웨어를 선택합니다.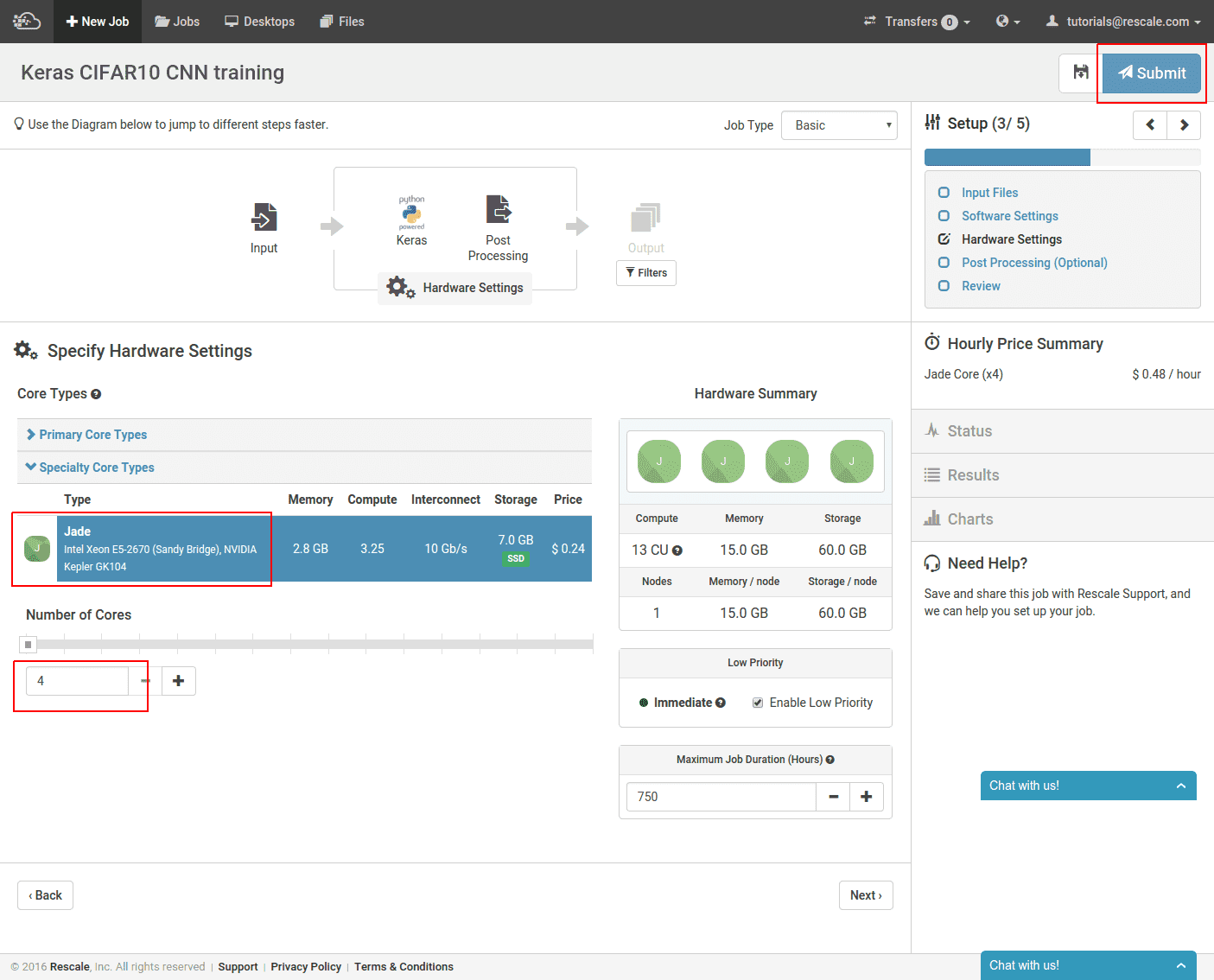
여기서 우리는 다음을 선택했습니다. 옥 코어 유형 및 최소 4 코어 이 유형의 경우. 마지막으로 작업을 제출합니다.
훈련이 시작되기 전에 클러스터를 프로비저닝하고 네트워크를 컴파일하는 데 약 15분이 소요됩니다. 시작되면 다음을 선택하여 진행 상황을 볼 수 있습니다. process_output.log.
작업이 완료되면 훈련된 모델 파일을 사용할 수 있습니다. 지금 보여드리는 것처럼 작업 결과 페이지에서 다운로드하거나 새 작업에서 사용할 수 있습니다.
새 이미지 분류
훈련 작업을 위해 사전 처리된 numpy 형식의 데이터 세트를 사용했습니다. 그렇다면 인터넷에서 실제 이미지를 가져오려면 어떻게 해야 할까요? 그리고 그걸 분류해? 부터 개 및 방법 2개 클래스 중 10개입니다. CIFAR10에 표현된 이미지 중에서 개와 고양이 이미지를 선택합니다. 인터넷을 통해 분류해 보세요.

이미지를 로드하고 축소하는 것부터 시작합니다.
numpy를 np로 가져오기 import scipy.misc def load_and_scale_imgs(): img_names = ['standing-cat.jpg', 'dog-face.jpg'] imgs = [np.transpose(scipy.misc.imresize(scipy.misc.imread) (img_name), (32, 32)), (2, 0, 1)).astype('float32') for img_name in img_name] return np.array(imgs) / 255
우리는 scipy를 사용합니다 읽다 JPG를 로드한 다음 이미지 크기를 32×32 픽셀로 조정합니다. 결과 이미지 텐서의 차원은 (32, 32, 3)이고 색상 차원이 마지막이 아닌 첫 번째가 되기를 원하므로 전치를 취합니다. 마지막으로, 이미지 텐서 목록을 단일 텐서로 결합하고 이전처럼 레벨을 0-1.0 사이로 정규화합니다. 처리 후에는 이미지가 더 작아집니다.![]()
![]()
여기서는 원본 이미지의 종횡비도 유지하지 않는 가장 간단한 크기 조정을 수행했습니다. 훈련 이미지에 대해 정규화를 수행했다면 이러한 변환을 이러한 이미지에도 적용하고 싶을 것입니다.
모델 로드 및 라벨링
저장된 모델을 조립하는 과정은 다음과 같은 2단계 프로세스입니다.
keras.models import model_from_json def load_model(model_def_fname, model_weight_fname): model = model_from_json(open(model_def_fname).read()) model.load_weights(model_weight_fname) 반환 모델
이를 종합하면 우리가 로드한 모델을 가져와 호출합니다. 예측_클래스 2개의 이미지에 대한 클래스 서수 값을 얻으려면
if __name__ == '__main__': imgs = load_and_scale_imgs() model = load_model('cifar10_architecture.json', 'cifar10_weights.h5') 예측 = model.predict_classes(imgs) print(예측)
라벨링 작업 재조정
이제 레이블 지정 스크립트를 작업에 넣고 예제 이미지에 레이블을 지정해 보겠습니다. 이 직업은 Rescale에서 공개적으로 사용 가능. 우리가 만든 훈련된 모델을 선택하기 시작합니다. "클라우드 스토리지의 파일 사용"을 선택한 다음 훈련 작업에서 생성된 JSON 및 HDF5 모델 파일을 선택합니다.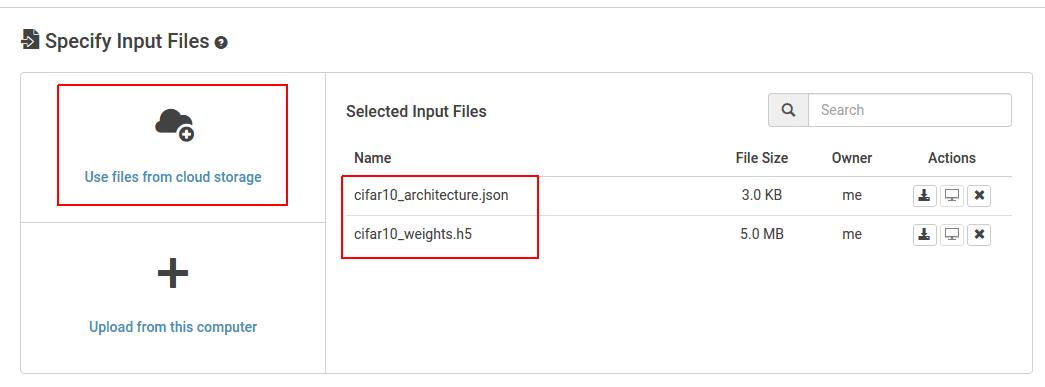
그런 다음 새 라벨 지정 스크립트를 업로드하세요. dog_cat.py 그리고 개와 고양이 이미지.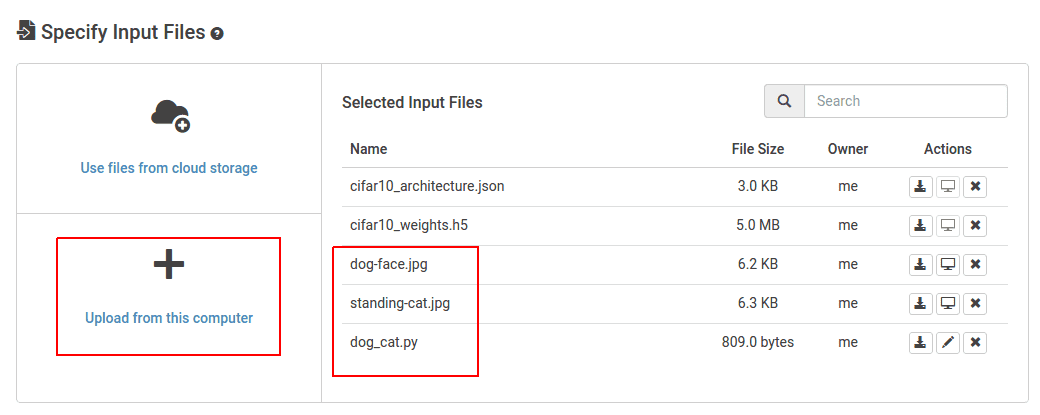
Keras GPU 소프트웨어를 선택하고 라벨링 스크립트를 실행하세요. 이 경우 개와 고양이 이미지는 작업이 실행되는 현재 디렉터리에서 로드되므로 파일을 이동할 필요가 없습니다.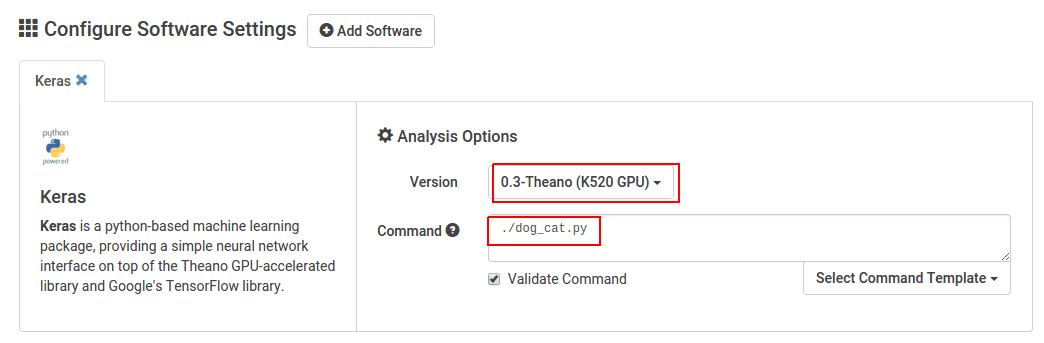
그러면 라벨이 다음 위치에 표시됩니다. process_output.log 작업이 완료되면.
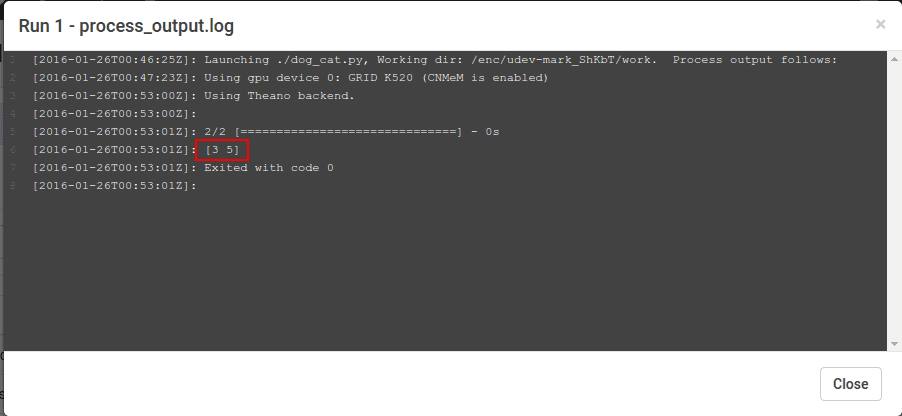
출력은 [3, 5] 에 해당하는 방법 및 개 위의 이미지 클래스 테이블에서.
이것으로 이 튜토리얼을 마치겠습니다. 우리는 Rescale에서 이미지 인식 컨볼루션 신경망을 성공적으로 훈련한 다음 해당 네트워크를 사용하여 추가 이미지에 레이블을 지정했습니다. 곧 다른 게시물에서 더 복잡한 Rescale 워크플로를 사용하여 네트워크 훈련을 최적화하는 방법에 대해 이야기하겠습니다.