

HPC バッチ ジョブを実行するためのベスト プラクティス
HPC バッチ ジョブとは何か、一般的な IT バッチ ジョブとの違い、HPC クラスターを実行するためのハードウェア インフラストラクチャとネットワーク ファブリックを設定する際の重要な考慮事項を理解します。
Rescale のエンジニアリング チームは、管理の複雑さを解決することに専念しています。 高性能コンピューティング この時代の (HPC) システム ハイブリッドおよびマルチクラウド コンピューティング.
研究開発向け HPC の基本は、デジタル シミュレーションやその他の種類の分析を実行するためのコンピューティング ジョブを作成することです。 したがって、Rescale エンジニアリング チームが重点を置く重要な領域は、シミュレーション ジョブやその他の大規模なコンピューティング タスクを正常にセットアップするために必要なタスクの多くを自動化することです。
この XNUMX 部構成のブログ投稿シリーズでは、使用するツールやインフラストラクチャ (オンプレミスまたはクラウド) に関係なく、HPC バッチ ジョブを実行するためのコンピューティング環境の構成とその他の管理上の考慮事項について重要な側面を説明します。
この最初の投稿では、HPC バッチ ジョブとは何か、一般的な IT バッチ ジョブとの違い、およびセットアップの考慮事項を定義することから始めます。 ハードウェアインフラストラクチャ HPC クラスターを実行するためのネットワーク ファブリック。
HPC バッチ コンピューティングの定義
HPC の世界では、バッチ ジョブとは、特定の種類の計算タスク (通常はデジタル シミュレーション用) を実行するソフトウェア アプリケーションを実行するハードウェアをセットアップすることです。
コンピューティング環境をセットアップしたら、「実行」をクリックすると、インフラストラクチャとソフトウェアにジョブを実行させることができます。 HPC ジョブが完了したら、研究者とエンジニアは結果を確認して分析を開始できます。
HPC バッチ ジョブ、コンピューティング環境を正しい方法でセットアップすることが重要です。 HPC ワークロードはコンピューティング ニーズが大きく異なる可能性があるため、重要なパフォーマンスと信頼性を確保するようにインフラストラクチャを構成することが重要です。 ソフトウェアまたはハードウェアの構成エラーが原因でシミュレーションが失敗したり、意図した結果が得られなかったりすると、さまざまな意味でコストがかかります。
これらのシミュレーションでは、多くの場合、長期間にわたって大量のコンピューター リソースを使用する必要があります。 それは高価です。 XNUMX本だけ使いながら (スーパーコンピューティング クラスター内の 20 台のコンピューター) は珍しいことではありません。シミュレーションには 50 または XNUMX のノードが必要になることが多く、その数は数千ノードになることもあります。 CPUコア。 これらのシミュレーションには XNUMX 分から XNUMX 週間以上かかる場合があります。 非常に長いシミュレーションを数日または数週間にわたって実行しているお客様もいらっしゃいますが、HPC バッチ ジョブがデジタル シミュレーションを完了するのにかかる一般的な実行時間は XNUMX ~ XNUMX 時間です。
HPC バッチ ジョブ: 一般的な IT バッチ ジョブではありません
IT バッチ ジョブにはさまざまな種類がありますが、データベースの更新などの一般的なタスクについて話している場合、これらのバッチ ジョブは、ハードウェアから最高のパフォーマンスを引き出すというよりも、特定の時間に何かが確実に実行されるようにすることに重点を置いています。
一般的な IT バッチ ジョブの主な目標は、それを実行し、失敗せず、他の人の邪魔をしないことです。 高速に実行できれば素晴らしいのですが、重要なのは、バッチ ジョブが他のタスクを妨げることなく処理にかかる時間を確保できる夜間のデータ センター時間を見つけることです。 タスクは、ある時点で完了する必要があります。 一般的な IT バッチ ジョブでは、速度は単純に重要な要素ではありません。
HPC バッチ ジョブでは、速度と効率がすべてです。 独自のスーパーコンピューターを実行したり、クラウドでレンタルしたりするコストを考慮すると、クラウドでも独自のデータセンターでも、コンピューティング リソースが最適に調整されていることを確認する必要があります。
クラウドの制約のないリソースを使用しても、HPC バッチ ジョブが適切な方法で実行されることを確認するには、一般的な夜間のエンタープライズ IT バッチ ジョブと比較して、さらに多くの作業を行う必要があります。
HPC バッチ ジョブを設定する場合は、まず、最適なチップ アーキテクチャと、それらのチップで利用可能な拡張機能を使用していることを確認する必要があります。 Intel チップまたは AMD チップの世代が異なると機能も異なるため、多くの場合、それらを活用するためにソフトウェアを構成してコンパイルする必要があります。
したがって、ハードウェアとソフトウェアの間には、考慮すべき重要なマッチングの問題があります。 そして、これはますます困難になっています 特殊な半導体チップの数が急速に拡大。 ハードウェアとソフトウェアが適切に一致していると、コスト、速度、エネルギー消費に大きな影響を与える可能性があります。
バッチ ジョブの設定に関する重要な考慮事項
HPC バッチ ジョブが必要なパフォーマンス レベルで正常に実行されることを保証するという重要なニーズを考慮すると、実行するアプリケーションの種類に最適な適切なハードウェアが必要になります。 シミュレーション アプリケーションが異なれば、要件も大きく異なります。 メモリを大量に消費するものもあれば、CPU コンピューティングを非常に消費するものもあります。 GPU などの特殊用途の半導体チップを必要とするものもあります。
したがって、最初に行うことは、シミュレーションの実行に使用するハードウェアのタイプを決定することです。 間違ったハードウェアに合わせて最適化すると、バッチ ジョブに大幅に、場合によっては XNUMX 桁も時間がかかる可能性があります。 したがって、待機時間が長くなり、そのコンピューティング時間により多くの費用が費やされる可能性があります。
計算速度とソフトウェアのコストの間には、トレードオフを考慮する必要もあります。 ライセンスはさまざまですが、研究開発で使用される高度で特殊なアプリケーションは通常、実行コストが高く、ライセンス コストは消費モデル (シミュレーションやその他の分析を実行するためにアプリケーションを使用するのに費やされる時間) に基づいています。
これを考慮すると、HPC バッチ ジョブの時間を短縮してソフトウェア コストを節約するには、より高速なコンピューティング リソースにより多くの資金を費やすことが有利になる可能性があります。 多くの場合、ライセンス コストを最適化するために、最小限の時間 (または最小限の CPU コア時間) で実行するように最適化することが必要です。ライセンス コストは、アプリケーションや状況によってはハードウェア コストよりはるかに高額になることが多いためです。 。
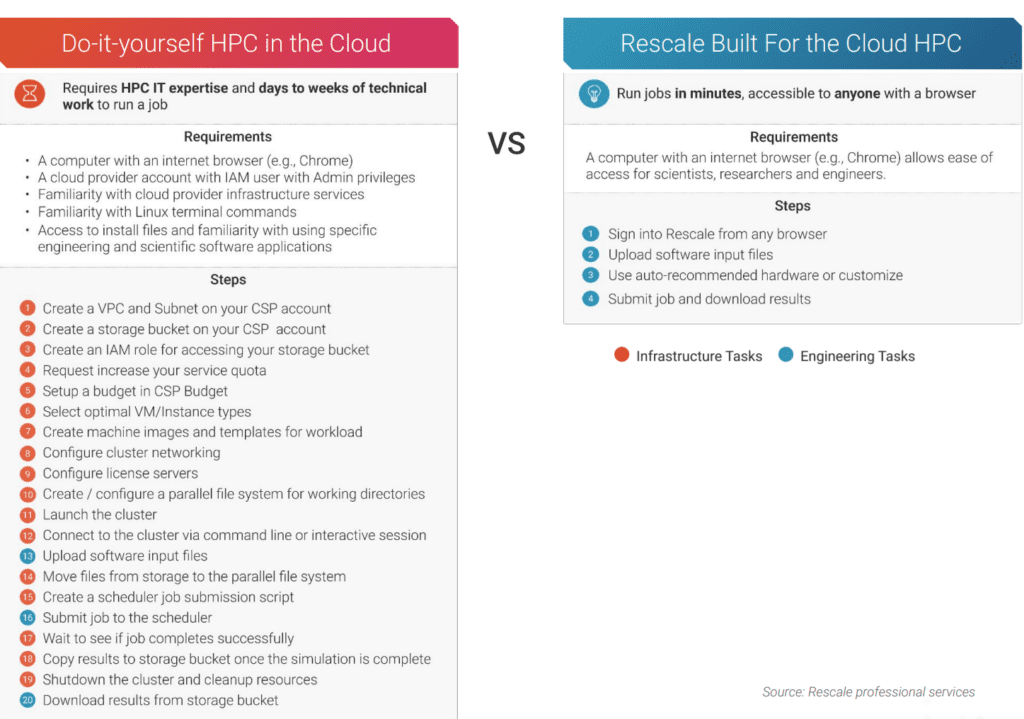
適切なネットワーク ファブリックの重要性
IT バッチ ジョブでは一般的ではないもう XNUMX つの複雑さの軸があります。それは、ネットワーク ファブリックと接続です。 異なるコンピューティング クラスターには、すべてのノードを接続する異なるタイプのネットワーク ファブリックがあります。 これは、標準的な IT コンピューティング ジョブでは通常問題になりません。 必要なのはいくつかのサーバーだけです。
Rescale のエンジニアリング チームが焦点を当てている大きな課題の XNUMX つは、ノード間通信がどのように機能するか、そしてそれが HPC アプリケーションのパフォーマンスにどのように影響するかということです。
通常、これらのジョブの多くは大規模なシミュレーションです。 これらを複数のノードで実行する必要があります。 また、これらのアプリケーションの多くは、ノード間のきめ細かい通信モデルを前提としています。
そのため、クラスターをセットアップしたり、通信ライブラリを最適に設定していない場合、シミュレーションの実行時間が大幅に長くなり、多くの非効率が生じる可能性があります。
多くの HPC アプリケーションでは、このきめ細かいマルチノード通信がすべて正常に機能するように、すべてのノード間の接続が非常に低遅延であることを確認する必要があります。
そして、そのノード間通信ネットワークを構築する方法はたくさんあります。 高帯域幅イーサネットを使用することも、ほとんどのイーサネット オプションよりも遅延が低く、帯域幅が広い InfiniBand を使用することもできます。 他にもいくつかのネットワーク ファブリック タイプがあります。
また、多くの HPC アプリケーションは、と呼ばれるライブラリ層を使用します。 のMPI (メッセージパッシングインターフェイス)。 ただし、MPI は単なる標準であり、ライブラリ自体ではありません。 ベンダーと開発者は、MPI 標準に基づいて独自のライブラリを作成します。
したがって、使用している MPI の種類が、使用しているハードウェアの種類と適切に動作することを確認する必要があります。 つまり、ハードウェアとシミュレーション アプリケーションを一致させるだけでなく、ハードウェアとミドルウェア層 (ライブラリ)、さらにアプリケーション自体を一致させる必要があります。
MPI は、特定のタイプのネットワーク ファブリックに合わせて構成する必要があります。 また、構成のニーズはネットワーク ファブリックごとに大きく異なります。 これは、単一のネットワーク ファブリックに対して一度設定すれば、あらゆるケースで適切に機能することが期待できるものではありません。 調整しないとパフォーマンスに大きな差が生じます。
そしてそれはアプリケーションによって異なります。 しかし、多くの HPC バッチ ジョブでは、シミュレーションを進めるためにさまざまなノード間でこの詳細な情報をすべて渡す必要があるため、コンピューティングよりもネットワークに依存することになります。 次に、ノード間の通信をガイドするライブラリが正しい方法で設定されていることを確認する必要もあります。
HPC バッチ ジョブの場合、最終的な結果は常に同じです。HPC ワークロードに最適化されたハードウェアとソフトウェアのスタック全体がなければ、その高価なハードウェアとソフトウェアの利点をすべて享受することはできません。
これでこのシリーズの第 XNUMX 部は終了です。 パート XNUMX では、ジョブのスケジュール設定、障害のある HPC ジョブのコスト、セキュリティ、マルチクラウド管理など、HPC バッチ ジョブを実行するための主要な問題について詳しく説明します。 乞うご期待!
詳細については、こちらから Rescaleのインテリジェントバッチ 機能
すべてのハイ パフォーマンス コンピューティング ジョブが確実に実行されるようにします。
高速、効率的、確実に実行するための正しい方法を設定します。






