クラウド: HPC における次の破壊
1991 年に私は Cray に入社し、Seymour Cray が設計したマシンに取り組む機会がありました。 私はオペレーティング システムの開発に携わっており、夜間に一人で作業することがよくありましたが、このようなユニークなシステムに取り組む興奮が私を動かし続けました。 Cray 1、XMP、YMP は、差別化されたアーキテクチャと設計により、通常のコンピューターでは解決できなかった問題を解決できるマシン ファミリを表していました。
私が入社したとき、Cray は MPP (超並列処理) と呼ばれる新しいタイプの並列マシンの構築を検討していました。 私は、Cray T3E のオペレーティング システムの設計と実装に取り組みました。これは、標準の CPU チップ、メモリ、および独自の高速インターコネクトを備えた 2048 個の個別ノードを備えたシステムです。 Cray は時代に先駆けて、今日 HPC クラスターと呼ばれるものを構築していました。 これは素晴らしいエンジニアリング プロジェクトであることに加えて、独自の Cray アーキテクチャから汎用部品を備えたノードのクラスターへの移行という破壊の始まりでもありました。
私は 2000 年頃に二度目の混乱を経験しました。私は SGI でソフトウェア開発を指揮していましたが、MIPS プロセッサからインテルへの移行を計画していました。 Linux がまだ愛好家向けのオペレーティング システムと考えられていた当時、SGI の IRIX は当時優れたオペレーティング システムとして宣伝されていたにもかかわらず、SGI ではリスクを冒して移行の際に Linux にも移行しました。 Linux は独自の OS よりも制御性が低いと見なされていたため、当初、顧客はこの変更にかなり抵抗がありました。 時間が経つにつれて、顧客がこのアイデアに慣れ、他のベンダーも追随し、Linux が HPC の標準オペレーティング システムになり、より多くのアプリケーションをすぐに利用できるようになりました。
年月が経ち、HPC は独自の独自設計から、多数のデュアル CPU Intel ノードのクラスターに移行しました。 ベンダーの製品は現在、アーキテクチャの独自性よりも、パッケージング、密度、冷却によって差別化されています。
並行して、より大きな IT 業界でもクラウド コンピューティングの勢いが増しています。 インテルは現在、自社施設で実行されるプロセッサよりもクラウドで実行されるプロセッサを多く販売しており、クラウドはオンプレミスよりも速い速度でイノベーションと効率性を推進し始めています。
ハイ パフォーマンス コンピューティングはオンプレミスで進化しました。 数百万ドルでコンピュータを購入すると、シミュレーションを実行して、イノベーションの時間と製品の市場投入までの時間を短縮できます。 図 1 に示されている自動車メーカーは、このような社内 HPC システムを購入する際に直面する新たなジレンマを表しています。 この会社のワークロードを考えると、どのサイズのシステムを購入すべきでしょうか? ピーク時のワークロードに対応するシステムを購入した場合、約 20 万ドルを費やす必要があるかもしれませんが、システムは 20% しか利用されません。 4 万ドルのシステムを購入した場合、システムは高度に活用されますが、大規模なジョブは実行できず、ジョブは実行されるまでキューで (場合によっては数日) 待機することになり、イノベーションと市場投入までの時間が遅れます。
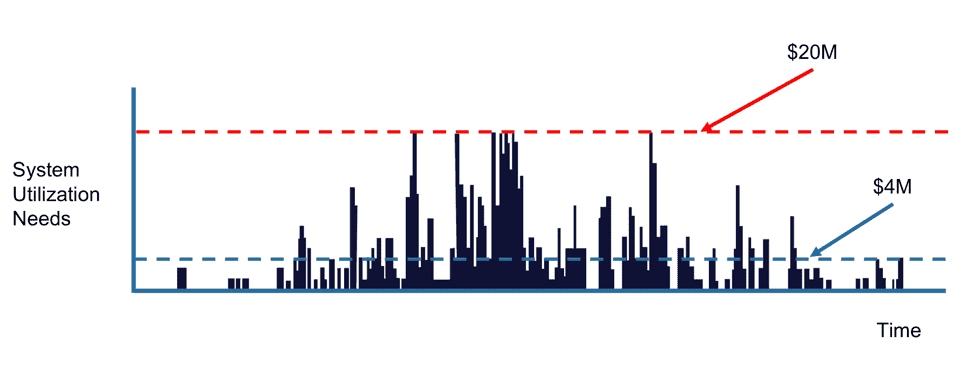
この自動車部品メーカーは、どちらの選択肢も受け入れられないと判断し、代わりに Rescale を採用し、クラウドで HPC を実行することにしました。 彼らは現在、必要なときに必要な IT に対して月額 50 万ドルから 100 万ドルを支払い、待つことなく完璧なサイズのシステムに即座にアクセスできるため、設計のスループットと市場投入までの時間が大幅に向上します。 Rescale クラウド プラットフォームを使用すると、4 万ドルのシステムのサービスを受けながら、20 万ドルのシステムの減価償却費にかかる費用を月々費やし、両方のメリットを享受できます。
高性能コンピューティング要件を持つすべての顧客は、自動車メーカーが直面しているのと同じ課題に直面しています。 CPU、GPU、TPU、KNL、FPGA、および複数の相互接続テクノロジを含む新しい種類のプロセッサ アーキテクチャでは、システムを分割するか、最新のアーキテクチャを使用しない必要があるため、この問題はさらに顕著になります。 対照的に、クラウドでは選択を強制されず、問題の種類に応じて最適なアーキテクチャで各ワークロードを実行できます。 アプリケーションはクラウド上で簡単にアクセスできるため、顧客は使用量に応じて支払うことができます。 ハードウェアとアプリケーションが利用できるようになったことで、クラウド HPC が登場するまでは大企業のみが利用できた HPC を新規顧客が利用できるようになりました。
以前のクラスター対モノリシック システム、または Linux 対独自のオペレーティング システムの混乱と同様に、クラウドは現状を変え、私たちを快適ゾーンから連れ出し、制御不能の感覚を与えます。 ただし、価格の影響、システム サイズを動的に変更してジョブに最適なアーキテクチャを選択する柔軟性、アプリケーションの可用性、特定のワークロードのニーズに基づいてシステム コストを選択する機能、プロビジョニングと実行の機能が影響します。すぐに、HPC ユーザーにとって非常に魅力的であることがわかります。 あなたの組織でもクラウドでの HPC について検討し始める時期が来ているかもしれません。
クラウドの破壊の性質は独特です。 オール・オア・ナッシングではなく、つま先を水に浸すこともできます。 従来のプロセスに従って別のオンプレミス システムを購入すると、クラウドの利点を逃すことになります。 クラウドは、次の数百万ドルの購入を約束することなく、将来のメリットをテストする機会を与えてくれます。 100 万ドルを支払えば、すぐにクラウドで HPC のテストを開始し、利用可能な最新のアーキテクチャにアクセスできます。 3 ~ 5 年以内に次の HPC システムがクラウドになるか、ハイブリッド システムになる場合は、今すぐテストしてそこから学習し、反復することでリスクが軽減され、よりスムーズな移行が可能になります。 したがって、クラウドについて考えることに加えて、来週から将来をテストすることをお勧めします。
-
 Gabriel Broner は、HPC 業界に 25 年間従事しています。 彼は、Cray でオペレーティング システム アーキテクト、SGI/HPE で HPC 担当副社長兼 GM、Ericsson でイノベーション責任者、Microsoft で GM を歴任しました。 ガブリエルは、2017 年 XNUMX 月に HPC の副社長兼ゼネラルマネージャーとして Rescale に入社しました。
Gabriel Broner は、HPC 業界に 25 年間従事しています。 彼は、Cray でオペレーティング システム アーキテクト、SGI/HPE で HPC 担当副社長兼 GM、Ericsson でイノベーション責任者、Microsoft で GM を歴任しました。 ガブリエルは、2017 年 XNUMX 月に HPC の副社長兼ゼネラルマネージャーとして Rescale に入社しました。