Rescale で TensorFlow モデルをトレーニングする

Google が TensorFlow をリリース (www.tensorflow.org)は、昨年 XNUMX 月に公開されたオープンソースの機械学習ライブラリであり、AI の分野で大きな注目を集めました。 TensorFlow は、機械学習の経験があまりない人でも比較的簡単に実践できるため、「誰でも使える機械学習」としても知られています。 本日、TensorFlow が Rescale のプラットフォームで利用可能になったことを発表できることを嬉しく思います。 これは、Web ブラウザだけで TensorFlow を使用して機械学習モデルの作成とトレーニングを学習できることを意味します。 このブログ投稿でその方法を説明します。
簡単なケースから始めましょう
最初の公式 TensorFlow チュートリアルから始めます。 ML 初心者向けの MNIST。 MNIST とは何か、また、TensorFlow で基本的な機械学習手法であるソフトマックス回帰を使用して MNIST をモデル化およびトレーニングする方法を紹介します。 ここでは、Rescale プラットフォーム上でジョブを設定して実行する方法に焦点を当てます。
ローカルエディターでPythonスクリプトを作成できます mnist_for_beginners.py:
# tensorflow.examples.tutorials.mnist から MNIST データをロードします import input_data mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) # モデルを定義します import tensorflow を tf x = tf.placeholder(tf.float32, [None , 784]) W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.nn.softmax(tf.matmul(x, W) + b) # モデルをトレーニングします y_ = tf.placeholder(tf.float32, [None, 10])cross_entropy = -tf.reduce_sum(y_*tf.log(y)) train_step = tf.train.GradientDescentOptimizer(0.01 ).minimize(cross_entropy) init = tf.initialize_all_variables() sess = tf.Session() sess.run(init) for i in range(1000):batch_xs、batch_ys = mnist.train.next_batch(100) sess.run( train_step, feed_dict={x:batch_xs, y_:batch_ys}) # モデルの評価correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))accuracy = tf.reduce_mean(tf. Cast(correct_prediction, tf.float32)) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
上記のスクリプトは、すべてのスニペットをまとめているだけです。 次に、これを Rescale の GPU ハードウェアで実行する必要があります。
まず、アカウントを作成する必要があります。まだアカウントを作成していない場合は、をクリックします。 こちら 1つを作成します。
ジョブを段階的に設定する面倒な作業を省略したい場合は、 こちら チュートリアル ジョブを表示し、それを自分のアカウントに複製します。
アカウント登録後、Rescaleにログインし、左上の「+新規ジョブ」ボタンをクリックして新規ジョブを作成します。
「このコンピュータからアップロード」をクリックして、Python スクリプトを Rescale にアップロードします。
「次へ」をクリックしてソフトウェア設定ページに移動し、ソフトウェアリストから TensorFlow を選択します。 現在、Rescale でサポートされているバージョンは 0.71 のみであるため、このバージョンを選択し、[コマンド] フィールドに「python ./mnist_for_beginners.py」と入力します。 「次へ」を選択して、ハードウェア設定ページに進みます。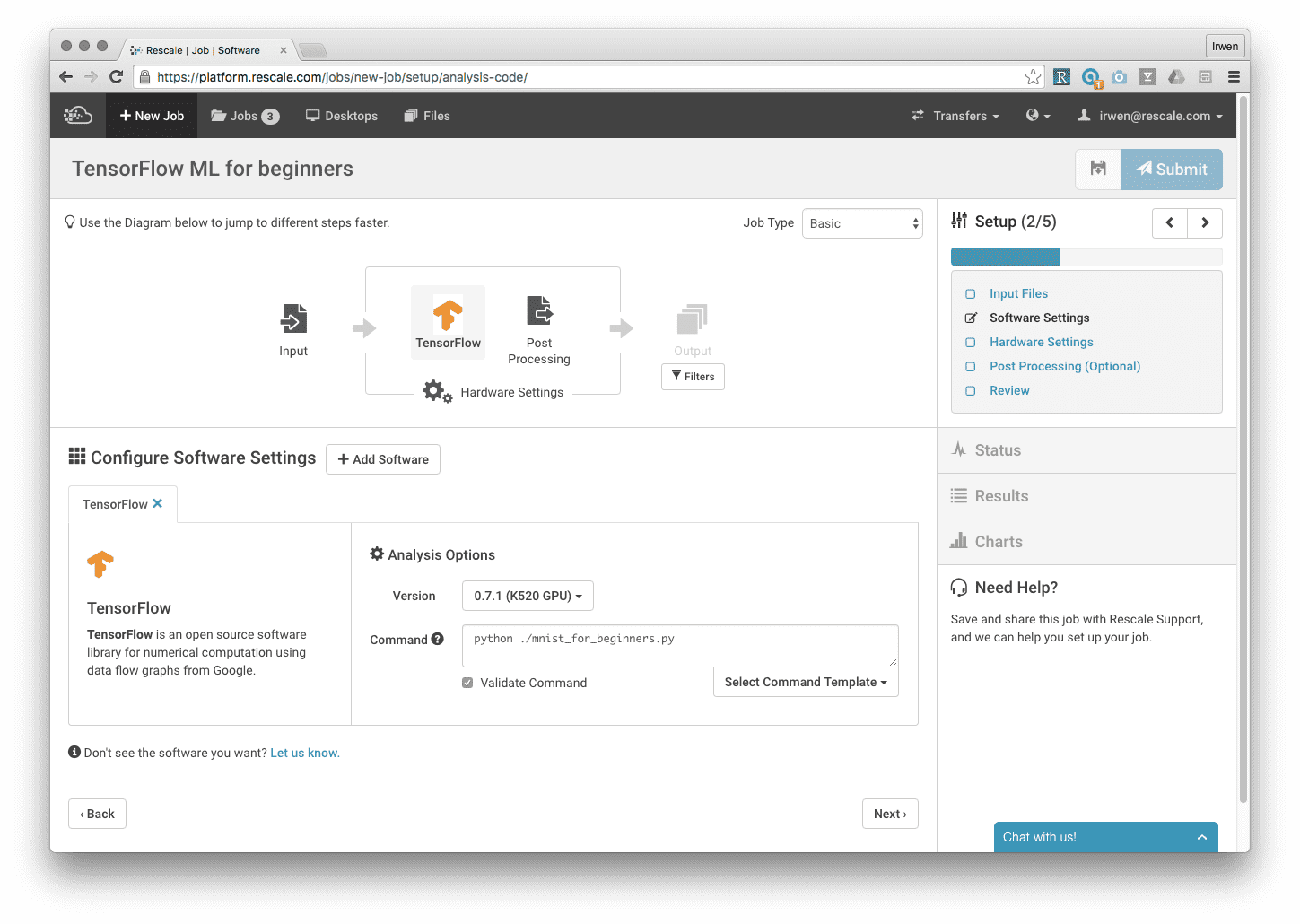
ハードウェア設定で、コア タイプ Jade を選択し、4 コアを選択します。 このジョブはそれほど計算量を多く必要としないため、有効な最小コア数を選択します。 この例では後処理をスキップし、「レビュー」ページで「送信」をクリックしてジョブを送信できます。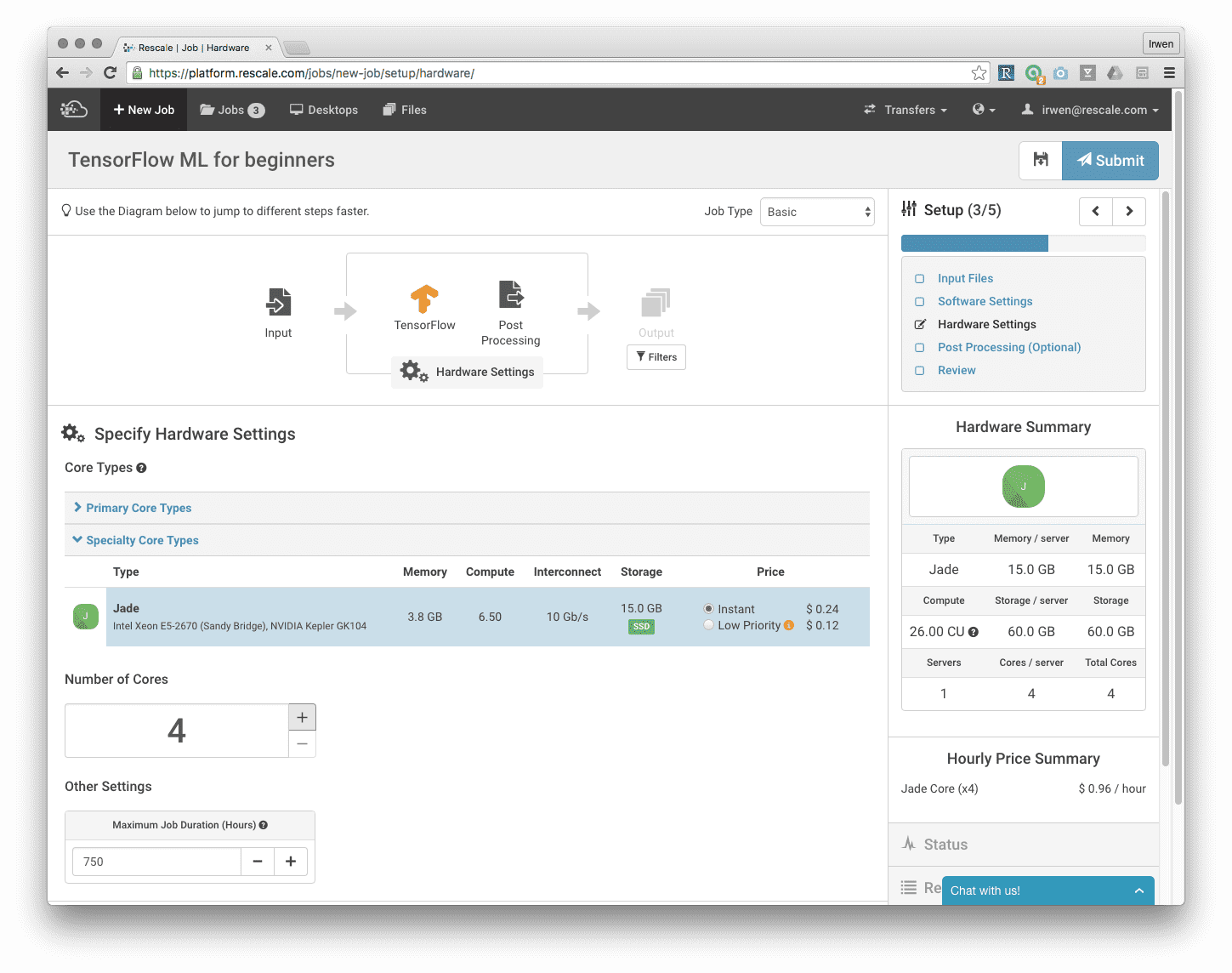
サーバーの起動には 4 ~ 5 分、ジョブの実行には 1 分かかります。 ジョブの実行中、Rescale のライブ テーリング機能を使用して、作業ディレクトリ内のファイルを監視できます。
ジョブが完了すると、結果ページからファイルを表示できます。 アップロードした Python スクリプトからの出力である process_output.log を見てみましょう。 下から 91.45 行目で、精度が XNUMX% であることが確認できます。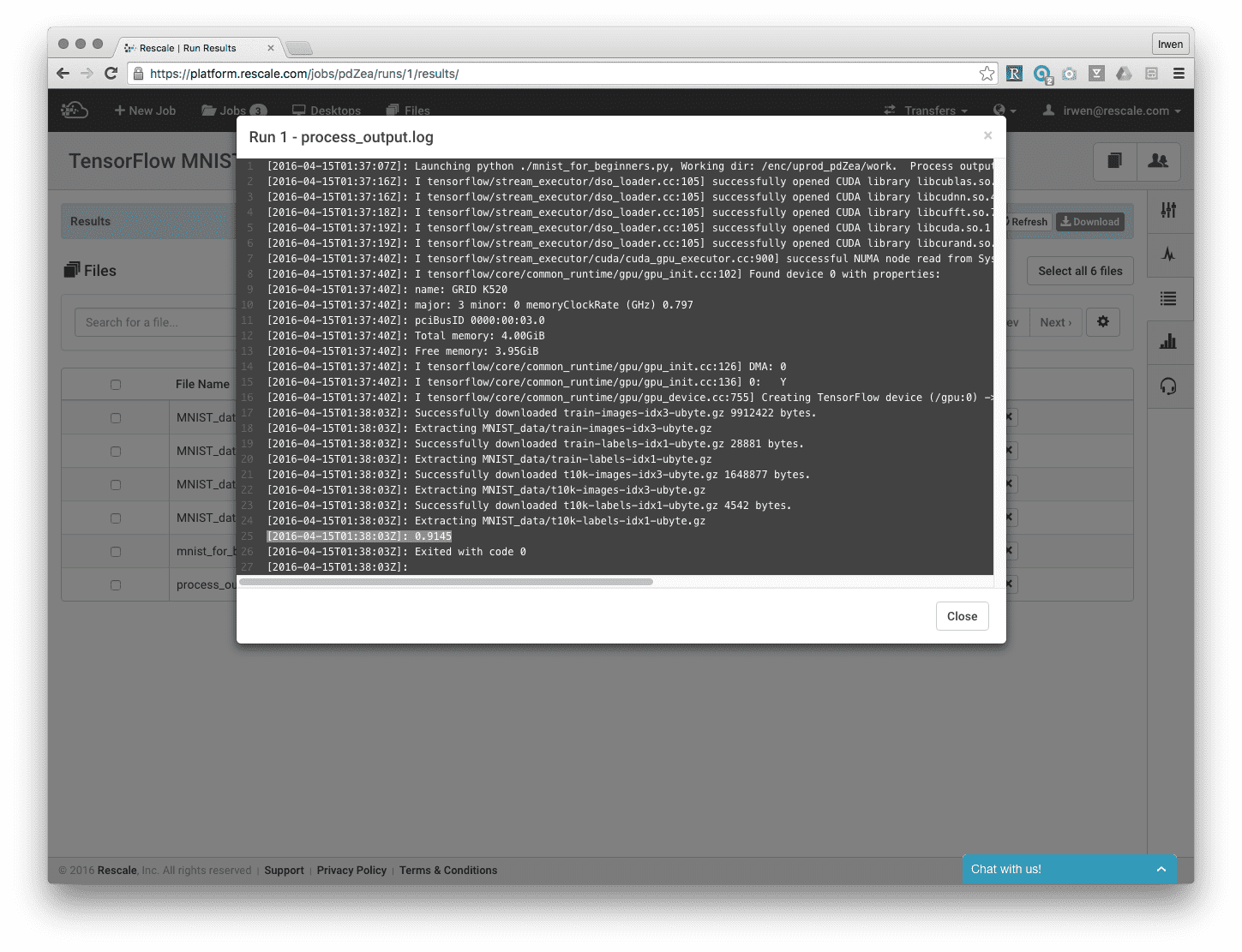
より高度なモデル
99.32 番目の TensorFlow チュートリアルでは、精度を XNUMX% に高めるために、多層畳み込みネットワークを使用してより高度なモデルが構築されます。
Rescale でこの高度なモデルを実行するには、最初のプロセスを繰り返し、Python スクリプトをチュートリアルの新しいモデルに置き換えるだけです。 また、既存のジョブを表示して複製することもできます。 こちら.
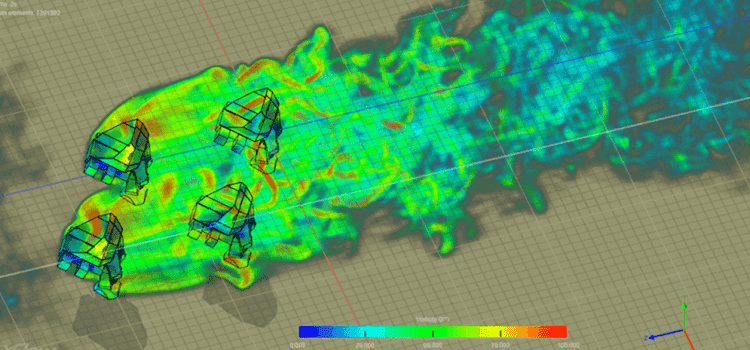
シングル GPU とマルチ GPU のパフォーマンス高速化テスト
マシン上に複数の GPU がある場合、TensorFlow はそれらすべてを利用してパフォーマンスを向上させることができます。 このセクションでは、単一の K520 GPU マシンと 4 つの K520 GPU マシンでパフォーマンス ベンチマークを実行し、パフォーマンスの高速化をテストします。
CIFAR10 畳み込みニューラルネットワーク この例はベンチマーク ジョブとして使用されます。 以下の結果から、GPU の数が 4 倍でも、2.37 秒あたりに処理されるサンプルは単一 GPU のパフォーマンスのわずか XNUMX 倍であることがわかります。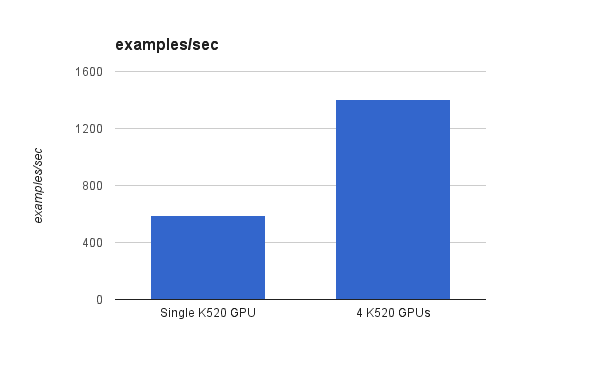
今後の作業
TensorFlow は、 新しい配布バージョン (v0.8) 4 年 13 月 2016 日、複数のマシン上の GPU 全体にワークロードを分散できます。 マルチノード、マルチ GPU クラスターの下でそのパフォーマンスを確認するのは非常に興味深いでしょう。 その前に、Rescale で TensorFlow をサポートするマルチノード マルチ GPU クラスターを起動するプロセスをできるだけ簡単にします。
このジョブをアカウントにインポートします