

コストとエネルギー消費を削減しながら HPC パフォーマンスを向上させる方法
ハイパフォーマンスコンピューティング は現在、現代の研究と工学の基礎となっています。 業界全体の組織が、製品開発サイクルを短縮するためにデジタル モデリングとシミュレーションに注目しています。 特に工学系では、 電子設計自動化 (EDA) そして、産業用モノのインターネット (IIoT) の急速な拡大が HPC の需要を押し上げています。
企業はますます複雑になるシミュレーションやその他のタスクを HPC に頼る一方で、コストを管理し、エネルギー消費を削減し続ける必要もあります。
ハイ パフォーマンス コンピューティング (HPC) とは何ですか?
汎用コンピューティングと比較して、HPC は、複雑な計算問題を非常に高速に処理するための優れたスループットを提供します。 HPC システム コンピューティング、ネットワーク、ストレージという XNUMX つの主要コンポーネントが含まれます。 これらは、大規模な並列処理を通じてコンピューティング能力を集約します。
HPC クラスターは、ネットワーク内に接続された多数のサーバーで構成されます。 各コンポーネント コンピューターは「ノード」とみなされます。 HPC システムには、多くの場合、ノードごとに 16 つの CPU を備えた 64 ~ XNUMX のノードが含まれます。
ハイ パフォーマンス コンピューティングの必要性は、今日のますます洗練されたソフトウェアと、シミュレーションや分析で使用される膨大なデータ セットによって促進されています。 このソフトウェアは、航空機の航空力学、自動運転、創薬、気象モデリングなど、さまざまな分野で製品のパフォーマンスを向上させるために使用されます。 たとえば、次のようなシミュレーション ソフトウェア アプリケーションがあります。 ANSYS, ジーメンス, ダッソー, 収束科学 特殊な HPC アーキテクチャに依存して実行する 計算流体力学 民間航空機、軍用機、宇宙船の開発向け。研究開発組織は通常、 幅広いアプリケーションのポートフォリオ、商用コード、オープンソースコード、および自家製コードを含むコードが含まれます。 効率的に実行できるようにする HPC infrastructure それぞれに異なるニーズがあるため、これは課題です。 同時に、独立系ソフトウェア ベンダー (ISV) の状況は拡大し続けており、組織が高度な研究開発ソフトウェアの使用をサポートする必要がある方法はさらに複雑になっています。
特化した HPC クラスター
HPC は、特殊な HPC クラスターを利用して、特定の種類のアプリケーションとワークロードのワークフローを最適化します。
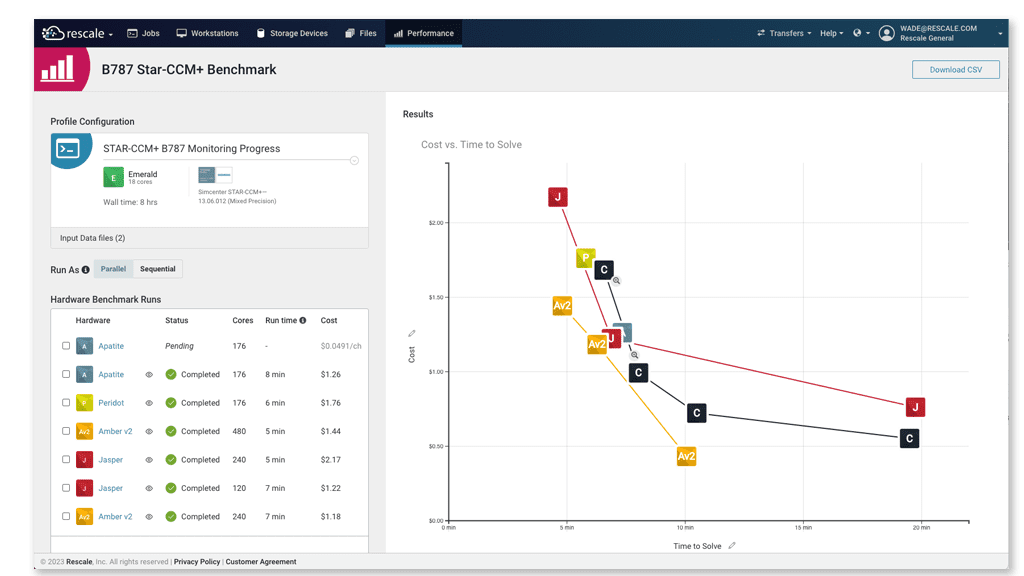
一部のタスクでは、特殊なハードウェアとソフトウェアだけでなく、ノード間でより多くの通信が必要になります。 特定のワークロードの計算要件によって、クラスター内に必要なノードの数が決まります。 一部のソフトウェアおよび計算タスクも、特定の種類の半導体チップを使用するとパフォーマンスが向上します。 のような自動ベンチマーク評価ツール パフォーマンスプロファイルを再スケールする 最適なチップ アーキテクチャを特定のコンピューティング タスクに適合させるのに非常に役立ちます。
クラスター用の高性能相互接続は、低遅延と低帯域幅のニーズに対応します。 ワークロードを追跡し、必要に応じて再ルーティングします。 大規模なデータ セットを処理する XNUMX つの方法は、HPC アプリケーションをパッケージ化し、複数のクラスター間で実行することです。 クラスター マネージャーは、容量チェックとヘルス チェックを実行して、利用可能なリソースを見つけて使用します。
コンテナ化
一部の組織は、AI の導入でますます普及している、GPU に最適化されたコンテナーを使用した HPC ワークロード管理にも取り組んでいます。 オープンソースの Apptainer (Singularity) は、HPC 用に最も広く使用されているコンテナ システムです。 Shifter と Docker も他のオプションです。 これらにより、主要な AI アプリケーションのシームレスな統合が可能になります。 コンテナ化されたアプリケーションにより移植性が向上し、社内アプリケーションや商用アプリケーションをどこからでも使用できるようになります。
仮想化はコンテナ化の代替手段です。 ホスト オペレーティング システム上に仮想環境を生成します。 仮想マシン (VM) は独自のオペレーティング システムでプログラムされており、仮想マシン間を完全に分離できます。 Hyper-V、vSphere、OpenStack などがその例です。
HPC が重要なのはなぜですか?
HPC は、従来のコンピューティングよりもはるかに短い時間で重要な情報と分析を提供します。 HPC のスピードは、エンジニアやデータ サイエンティストから製品設計者や研究者に至るまで、多くの役割にメリットをもたらします。
また、モデリングとシミュレーション (M&S) をまったく新しいレベルに引き上げます。 たとえば、高解像度のモデルでは、新製品に関するより詳細な情報が提供されるため、プロトタイプや実際のテストの必要性が軽減または排除されます。 実際の衝突試験ではなく自動車の衝突シミュレーション、または実際の航空機ではなくフライト シミュレータでパイロットを訓練することを考えてください。
クラウド HPC を使用すると、さまざまな企業がコンピューティングのニーズをオンデマンドで迅速に拡張できます。
いくつかの例があります:
- エンジニアリング会社
- 研究所
- 金融テクノロジー(フィンテック)
- 商品開発
- 政府と防衛
新興企業や中小企業でも、拡張性の高いクラウド HPC を活用できます。
HPC パフォーマンスの理解
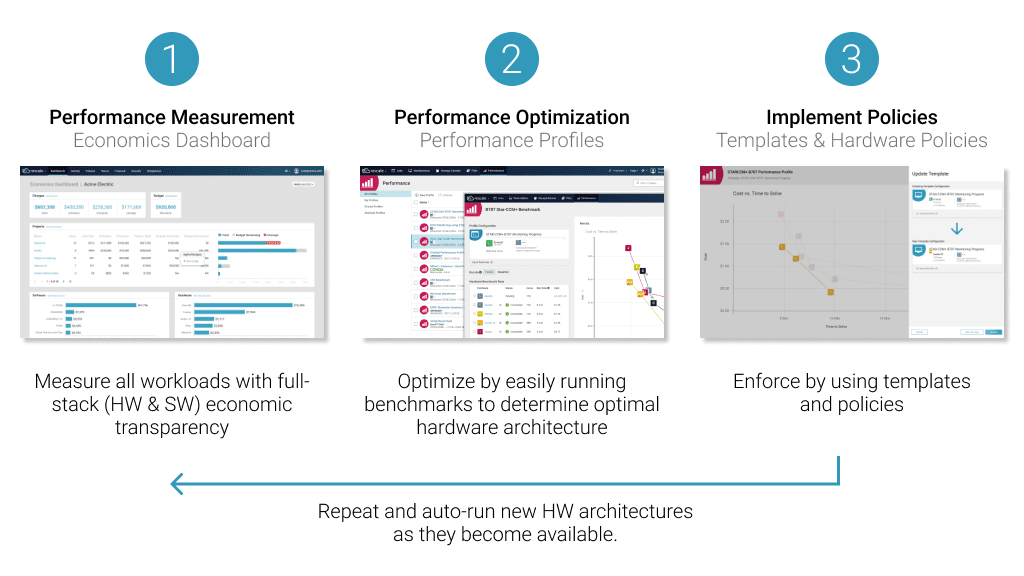
HPC 最適化は、特定のワークロードに適切なコンピューティング アーキテクチャを提供する際の複雑さに対処します。 また、システムのエネルギー効率を高めるためにも不可欠です。 HPC ワークロードは、オンプレミスまたはクラウドにあるシステム リソース全体に分散されるデータ集約型のタスクです。
今日の HPC システムは、AI、機械学習、深層学習などの驚異的なワークロードを処理できます。 大量のデータを処理しながら、数百万のシナリオを同時に実行します。
主要業績評価指標
アナリストは、HPC システムのパワーをフロップ/秒で測定します。 現在、オークリッジ国立研究所のフロンティアマシンは、 TOP500 1.102 Eflop/s を実現する最も強力なスーパーコンピューターのリスト (XNUMX エクサフロップスは XNUMX 京の計算に相当します)。
もう XNUMX つの重要な指標は、 電力使用効率(PUE)、データセンター全体のエネルギー効率を決定します。 PUE は、データセンターに入る総電力をすべての IT 機器の動作に使用される電力で割ることによって計算できます。 数値が 1.0 に近づくほど、全体の効率が向上します。 もう XNUMX つのベンチマーク基準は、 データセンターインフラストラクチャの効率化 (DCiE)。 このエネルギー効率の指標は、IT 機器の電力を施設の総電力で割ることによって計算されます。
最後に、指標は重要ですが、それはある程度までです。 最終的に、ユーザーが最も気にするのは、計算ジョブの高速化に役立つ現実世界のパフォーマンスです。 あらゆる種類のソフトウェアとワークロードの HPC パフォーマンスを完全に評価することは困難な場合があります。 一部の種類の半導体チップは、他の種類のソフトウェアよりも特定の種類のソフトウェアでより適切に動作します。
計算上のボトルネック
一部の企業では、オンプレミスのインフラストラクチャ自体がボトルネックになっています。 このタイプのインフラストラクチャ投資は通常、100% の使用率で計算されるため、瞬間的な需要が供給を上回り、容量がなくなるためボトルネックが発生します。 それに比べ、クラウド HPC は弾力性があり、ニーズの変化に応じてスケールアップおよびスケールダウンできます。 組織は、より多くのコンピューティング能力をサブスクライブするだけで済みます。 その結果、クラウドの HPC は、容量の上限による制約に遭遇することなく、最大限の活用を実現します。
HPC システム内には、メモリ容量、I/O スループット、ストレージの速度/容量など、他にも多くの潜在的なボトルネックが存在します。 CPU コア、クロック速度、またはキャッシュもパフォーマンスを制限する可能性がありますが、その他の阻害要因にはネットワーク スイッチの帯域幅が含まれる可能性があります。
データ転送速度が高くなると、バッファリングとストレージに必要なメモリが増えることになるため、メモリ容量も問題になります。 従来の DDR3、DDR4、さらには DDR5 メモリがボトルネックになる可能性があります。 ただし、高帯域幅メモリ (HBM) は DDR5 メモリの XNUMX 倍の帯域幅を提供するため、解決策として考えられます。
ボトルネックを回避するには、ソフトウェアの仕様をパフォーマンスを最適化する HPC 構成に合わせることも重要です。
HPC のエネルギー効率
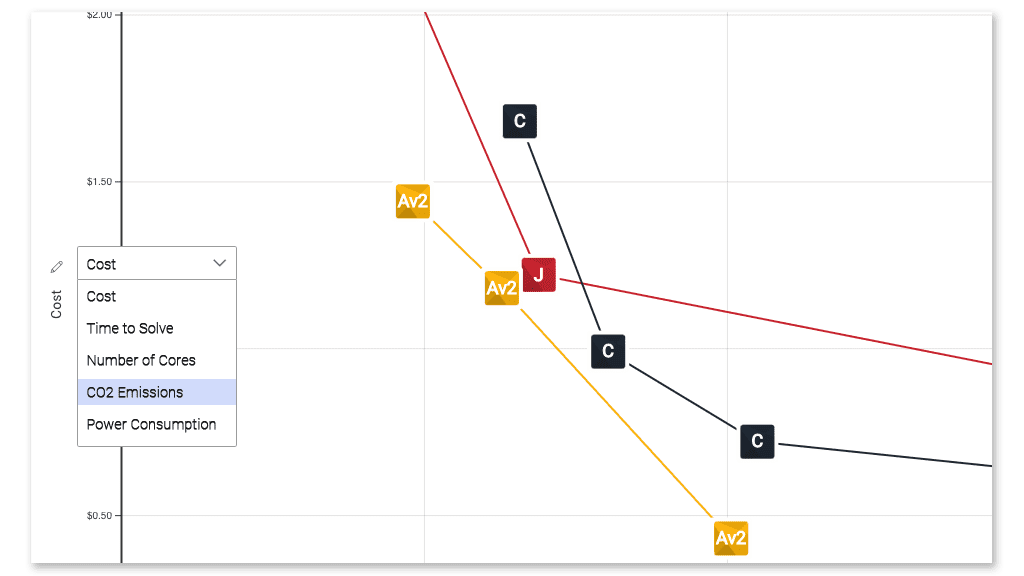
ワットあたりのフロップ数で測定される HPC システムのエネルギー効率は向上し続けています。 この一例としては、 ヘンリー ニューヨーク市のフラットアイアン研究所のシステムで、効率スコアは 65.09 GFlops/W でした。
データセンター運営者は、さまざまな方法でエネルギー効率を改善し続けています。 たとえば、次世代の低電力チップセットはエネルギー消費を削減し、熱の放散に優れています。 電力が最適化された IP コアにより、エネルギー使用量とデータ転送も削減されます。 広帯域メモリ。 一部の事業者は、次のような代替の持続可能性手法に目を向けています。 液体冷却 & 熱リサイクル.
データセンターの期待はますます高まっています 再生可能エネルギー源 水力、風力、太陽光、バイオマス、グリーン水素など。 191 年から 2015 年にかけてデータセンターの電力消費量が 2021 テラワット時で横ばいになったことからも明らかなように、大きな進歩が見られます。ただし、オンプレミスのデータセンターからの XNUMX 回限りの移行により、HPC 需要の全体的な伸びがいくらか隠蔽されてしまいました。
HPC コンピューティング需要への対応
需要に応えるために、業界はこれまで以上に強力なマシンで対応しています。 システムはペタフロップスからエクサフロップス以上の容量に移行しています。 エクサフロップス機能を備えたスーパーコンピューターは、XNUMX 京の計算を実行するのに XNUMX 秒を必要とします。 それ以上かかります 31億年 XNUMX 秒あたりわずか XNUMX 回の計算で、その数の計算を完了します。
HPC 効率を拡大するためのイノベーションには、新しいアーキテクチャとハードウェアが含まれます。 たとえば、3DIC とダイツーダイ接続は最新のパフォーマンス要件に対応します。 また、FPGA、GPU、CPU、その他の処理アーキテクチャが単一ノードに統合されている場合、より柔軟なスイッチングが可能になります。
新しいハードウェアはクラウドベースの HPC を好むことがよくあります。 したがって、従来のオンプレミス データセンターは、よりエネルギー効率の高いチップセットを常に活用できるとは限りません。 クラウドへの移行は、スピード、スケーラビリティ、持続可能性に対する需要の高まりに効果的に対処する XNUMX つの方法です。
ただし、オンプレミスからクラウドへの単純な「リフト アンド シフト」移行では、企業の新たな HPC ニーズに必ずしも対応できるとは限りません。 通常、更新サイクルは XNUMX ~ XNUMX 年であるため、レガシー インフラストラクチャでは変化するビジネス ニーズに対応できない場合があります。 このような長いサイクルでは、HPC エコシステムの急速な変化に追いつくことができません。 クラウドの導入により、財務上の柔軟性も比較的高くなります。 企業の HPC コスト モデルは長期的なものから移行する CapEx 短期的な運用コストへ。 それほど多くの資本を拘束せず、さまざまなクラウド HPC コスト モデルを現在のニーズにうまく適合させることができます。
主要な取り組み
オンプレミスのデータセンターを使用している企業にとって、クラウドへの移行は、コストを削減しながらエネルギー効率を向上させる重要な方法です。 Cloud HPC は、あらゆる規模の企業に最新の技術進歩の恩恵を受ける方法を提供します。
HPC パフォーマンスを最適化するには、ソフトウェア仕様と利用可能なハードウェアを調整する必要があります。 さらに、特殊な HPC クラスターとコンテナー化によって、HPC のパフォーマンスとエネルギー効率も向上します。
AI の使用が普及するにつれて、HPC システムはさらに高度なものになるでしょう。 効率的なエネルギー.
Rescale の詳細をご覧ください
Rescale が、より大きなイノベーションを推進しながら、組織のコスト管理にどのように役立つかをご覧ください。 と パフォーマンスプロファイル、ニーズに最適なクラウド HPC アーキテクチャを簡単に特定できます。
オンデマンドウェビナーで詳細をご覧ください 「クラウドでのワークロードのコストとパフォーマンスを最適化します。」






