

ハイパフォーマンス コンピューティング システムを管理するための重要なヒント
HPC バッチ ジョブを正常に実行するには、チームはスケジュール、セキュリティ、トラブルシューティング、および新しいクラウド要件について計画する必要があります。
Rescale のエンジニアリング チームは、管理の複雑さを解決することに専念しています。 ハイ パフォーマンス コンピューティング (HPC) ハイブリッドおよびマルチクラウド コンピューティングの時代におけるシステム。
研究開発向け HPC の基本は、デジタル シミュレーションやその他の種類の分析を実行するためのコンピューティング ジョブを作成および管理することです。 したがって、Rescale エンジニアリング チームが重点を置く重要な領域は、シミュレーション ジョブやその他の大規模なコンピューティング タスクを正常にセットアップして実行するために必要なタスクの多くを自動化することです。
XNUMX 部構成のブログ投稿シリーズの XNUMX 番目です (パート XNUMX をお読みください: 「HPC バッチ ジョブを実行するためのベスト プラクティス」) では、スケジューリング、セキュリティ、トラブルシューティング、クラウド HPC の特定の要件を理解する必要性の増大など、HPC バッチ ジョブに関する広範な管理上の考慮事項のいくつかについて説明します。
HPC バッチ ジョブのやりくり
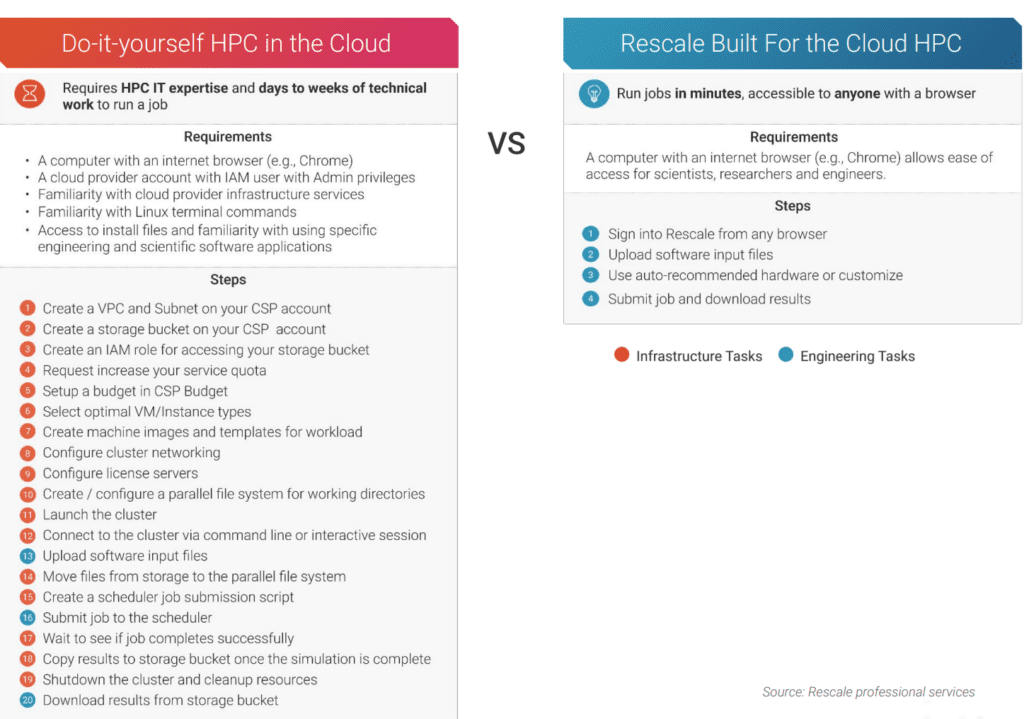
それで走るために バッチ処理の場合は、クラウドでもオンプレミスでも、ハードウェアをセットアップし、ネットワークを構成し、ソフトウェアをセットアップする必要があります。 プロセスは異なりますが、これをすべて適切に実行するにはどちらも HPC の専門知識が必要です。
特定のバッチ ジョブの要件を比較的よく知っている場合は、通常、すべてを数時間で完了できます。 しかし、これはあまり現実的ではありません。通常、常に同じ種類のバッチ ジョブをセットアップすることはないからです。 特定のアプリケーションに合わせてコンピューティング環境を構成する必要があります。 一部のタスクは優れたスループットを必要とし、他のタスクはより多くの並列化を必要とするなどです。
各 HPC バッチ ジョブは独自の行程であり、システムが特定のワークロードに対して最適化されていることを確認するために、すべてのハードウェアおよびソフトウェア コンポーネントに対処する必要があります。 これは、新しいタイプの HPC ジョブを構築するためにゼロから始めることを意味する場合があり、その過程でいくつかの教訓を学ぶ必要がある場合があります。
そして次のタスクは、 これらすべてのバッチ ジョブをスケジュールする そのため、優先順位の高い仕事を持つ人は、締め切りに間に合うように仕事を終わらせます。 また、HPC バッチ ジョブの進行中のフローを処理する場合は、まったく別のレベルの構成とプロビジョニングを実行する必要があります。
研究開発チームが使用するさまざまなアプリケーションの数に応じて、新しいバージョンのソフトウェアをセットアップしてサポートする必要もあります。 新しいアプリケーションがクラスタ化されたハードウェア上で適切に動作することを確認するために、大規模なメンテナンスとチューニングが必要です。
理想的には、クラウドでもオンプレミスでも、ハードウェアを定期的に更新する必要があります。 毎月、新しいチップが市場に投入され、より高速なレースカーが常に登場しています。 新しいものから最も恩恵を受けるかもしれません ArmベースのCPU より優れたエネルギー効率を実現するには、GPU による純粋な並列化能力が必要になる場合があります。 したがって、これも維持し、管理する必要があります。
あとはシステムの継続的なメンテナンスだけです。 スケジューラは時々悪い状態になることがあり、それを修復する必要があります。 すべてをセットアップして希望どおりに実行した後でも、クラウドベースの HPC とオンプレミスの HPC の両方に多くのメンテナンス部分があります。
障害のある HPC バッチ ジョブのコスト
コンピューティング環境が正しく設定されておらず、 システムの障害、これにより、ジョブが完了しなかったり、シミュレーションやその他の分析が正しく完了しなかったりする可能性があります。
これは、設計している製品に劇的な影響を及ぼします。 システムから不正なデータが取得されている場合、特にそれがエラーとしてフラグが立てられていない不正なデータである場合、それは製品開発または規制遵守にとって大きな問題となる可能性があります。 気づかなかった欠陥を持った製品を作ってしまう可能性があります。
また、障害が発生してソフトウェアがそれを呼び出した場合でも、すべての作業が失われます。 次に、それを修正してシミュレーションを再度実行する必要があります。 そして、それがハードウェア障害だった場合、この種のエラーは判断が非常に難しいため、さらにイライラします。 ノード間通信も同様です。 多くの場合、これによりチームは障害を見つけられず、シミュレーションを再実行して再び障害が発生し、高価で時間のかかるトラブルシューティング プロセスを繰り返すことになります。
したがって、全体として、HPC バッチ ジョブが正しく設定されていない場合、ジョブが失敗したり不正確になったりして、時間や費用がかかったり、会社を危険にさらしたりする可能性があります。
その一例が、当社のクラウド プロバイダー パートナーの XNUMX つでした。 一部の製品では一貫したバージョンのファームウェアがセットアップされていませんでした。 スイッチ。 ネットワーキング ライブラリは、その特定のコンピューティング クラスター上のバッチ ジョブの 48 時間後にランダムに失敗します。
スイッチ上のその種のファームウェアは、スタックのかなり下の方にあります。 アプリケーションの出力を見るだけでは、障害の原因がネットワーク ファームウェアであることを特定することはできません。 それらの欠陥が見つかったら、それが失敗したことがわかります。 しかし、多くの場合、HPC システムにはすべての層があるため、スタックのどこで問題が発生しているのかわかりません。
したがって、非常に時間がかかる可能性があるデバッグの問題があります。 また、一度だけ発生する場合は大した問題ではないかもしれませんが、さまざまなワークロードで XNUMX 日に数回障害が発生した場合、大量のシミュレーション データが廃棄されるとともに、多くの時間が失われる可能性があります。
HPC ジョブを確実に (オンプレミスとクラウドで) 確実に実行するには、ネットワーク、システム管理、ストレージ、データ センター管理、および複雑なアプリケーションのメンテナンスを担当する HPC 専門家のチームが必要です。 HPC システムの信頼性と効率性を確保するには多くの技術リソースが必要ですが、HPC 管理を自分で行う場合のベスト プラクティスにはこれが必要です。
研究開発データのセキュリティ
もちろん、HPC にとってセキュリティは最重要です。 HPC システムには通常、組織の最も機密性の高い設計情報と製品情報が保管されています。
セキュリティを管理するには、組織内でコンピューティング環境をどの程度オープンにしたいかによって異なります。 さまざまなタイプのユーザー アクセスを考慮し、承認されたユーザーがシミュレーションとデータを簡単に利用できるようにしながら、それらが組織の他の部分や組織外に移行したり「漏洩」したりしないようにする必要があります。
そして、これらはすべて、ファイル システム レベルまたはシミュレーション データを保存する場所で適切に設定および維持する必要があります。 したがって、マルチユーザー環境で共有ファイル システムを安全にセットアップして管理する方法を知る必要があります。 これは、HPC チームに必要なもう XNUMX つのスキル セットです。
マルチクラウド管理
もちろん、クラウドは、ほぼ無制限のオンデマンドの高性能コンピューティング容量を提供することで、従来のオンプレミス HPC データ センターの最大の問題に対処します。 しかし、マルチクラウド HPC コンピューティングは、新たな、そして同様に困難な技術的複雑さをもたらします。
HPC チームは、さまざまなクラウド プロバイダーでコードとしてのインフラストラクチャを管理する方法を本当に知る必要があります。 クラウド プロバイダーによって、インターフェイスと構成をどのように操作する必要があるかがかなり異なります。
各クラウド プロバイダーは、コンピューティングを調整してクラスターを構築し、バッチ ジョブをサポートし、ノードを接続するネットワーク ファブリックでの低遅延を確保するさまざまな方法を採用しています。 ほとんどの場合、CSP ごとにまったく異なる設定セットが存在します。
その理由の多くは、低遅延ネットワークについてこれらの考慮事項に入ると、それがまだ少しニッチであるためです。 特にクラウド HPC は非常に新しいため、プロバイダー全体にわたる強力な標準がありません。 各クラウド プロバイダーは、HPC コンピューティングの複雑な世界をまだ理解している段階であるため、やり方が異なります。 したがって、クラウド プロバイダーに適切な構成を依頼する方法を知る必要があります。 API またはその SDK ハードウェアから最適なパフォーマンスを引き出します。
たとえば、AWS では EFA (Elastic Fabric Adaptor) と呼ばれるものが提供されています。 これは、コンピューティング インフラストラクチャ上で低レイテンシ ネットワーキングを実現する AWS の社内ソリューションです。 Azure は、HPC 業界標準タイプのテクノロジである InfiniBand をサポートしていますが、これも仮想化されています。
したがって、AWS と Azure の両方で HPC ワークロードを実行したい場合は、これらの異なるネットワーク テクノロジを最大限に活用するためにノードをプロビジョニングする方法を理解する必要があります。 そして、各ファブリックのノードのクラスターを接続したら、次は、ファブリックの構成方法を知る必要があります。 MPI ライブラリ それぞれのタイプのネットワークを活用します。
ネットワーク ファブリックを超えて、ハードウェア自体の上にあるスタックの他の部分も構成する必要があります。
さらに、地域内のどの HPC クラウド サービス プロバイダーがコストとパフォーマンスの最適なトレードオフを提供するかを理解するという課題もあります。 時間帯によっても、HPC ジョブの実行コストに大きな違いが生じる可能性があります。 また、HPC スーパーコンピューティング クラスターの場合、特に特殊なインフラストラクチャの場合、クラウド プロバイダーでは可用性が保証されるわけではありません。
また、すべてのクラウド サービス アカウントを注意深く監視する必要があります。 クラウド リソースを見失うことは驚くほど簡単で、シャットダウンし忘れていたものの請求書が届く月末になって初めて見つけることができます。
HPC クラウド サービスの市場全体と自社のインフラストラクチャ エコシステム全体にわたる可視性と洞察を得ることが、賢明な買い物客となり、クラウド コストを管理して HPC への投資を最大限に活用するために不可欠です。
セットアップ中や、 HPC の管理 バッチ ジョブは決して単純ではなく、正しく行うことが重要です。 スーパーコンピューティングは今や、増大する強力なデジタル技術を強化するために不可欠です モデリングとシミュレーション 科学研究とエンジニアリングを仮想化するソフトウェア。 このようなデジタル研究開発は現在、将来のイノベーションの基盤となりつつあります。 ハイ パフォーマンス コンピューティングを使いこなす企業は、製品開発の取り組みにおいてますます有利になるでしょう。
詳細については、こちらから Rescaleのインテリジェントバッチ 機能
すべてのハイ パフォーマンス コンピューティング ジョブが確実に実行されるようにします。
高速、効率的、確実に実行するための正しい方法を設定します。






