
NGC CUDA Quantum의 재조정

살펴보기
이 튜토리얼에서는 NGC를 사용하여 Rescale 플랫폼에서 NGC CUDA Quantum을 시작하는 방법을 배웁니다. 컨테이너 이미지 여기에는 모든 CUDA Quantum 릴리스가 포함되어 있습니다.
Nvidia CUDA Quantum 이미지에 내장된 예제를 사용하여 Rescale 플랫폼의 민첩성, 확장성 및 사용 용이성을 입증하여 Quantum 알고리즘 연구를 수행하고 살펴보겠습니다. 시뮬레이션시뮬레이션은 실험, 테스트 시나리오 및 제작입니다. 더 보기 예.
참고: NGC에서 이미지를 가져오기 위한 전제 조건인 API 키와 조직 ID에 액세스하려면 Nvidia 계정이 필요합니다. 컨테이너자립형 애플리케이션 및 운영 체제 패키지 더 보기 레지스트리 및 그 내에서 작업합니다. QPU를 사용하려는 경우 관련 백엔드 QPU 하드웨어 제공업체의 계정/API 키도 필요합니다. 안 건축적 전제조건 CUDA Quantum의 경우 나열된 GPU 아키텍처(Volta, Turing, Ampere, Ada, Hopper)를 사용할 수 있습니다. Rescale에서 이러한 GPU 아키텍처의 가용성 및 용량에 대해서는 Rescale Solutions Architect에게 문의하십시오.
Nvidia CUDA Quantum은 '배치' 작업(보다 편리하게는 '헤드리스' 작업이라고 함)을 사용하여 SSH를 사용하여 CUDA Quantum과 작업하거나 Rescale Workstations(헤드 노드의 GUI)를 대화식으로 사용하여 실행할 수 있습니다. 두 옵션 모두 Nvidia의 고성능 하드웨어를 포함하여 Rescale 플랫폼에 존재하는 다양한 하드웨어에 대한 액세스를 제공합니다. GPUGPU(그래픽 처리 장치)는 특수 전자 장치입니다. 더 보기.
먼저 기본 Nvidia GPU를 사용하여 큐비트를 시뮬레이션한 다음 Nvidia 파트너 Quantum 하드웨어 제공업체(IonQ) 중 하나에 Quantum Simulator 백엔드로 샘플 작업을 전송하여 Rescale 플랫폼에서 NGC CUDA Quantum 이미지를 사용하여 Quantum 알고리즘 연구를 살펴보겠습니다. .
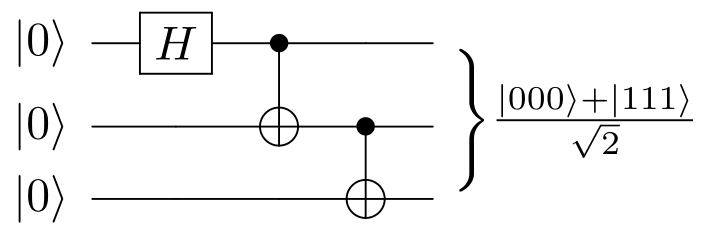
먼저 시뮬레이션하는 내장 예제를 시작합니다. GHZ 주 표준 CPU 전용 시뮬레이터에는 너무 크지만 NVIDIA GPU 가속 백엔드를 통해 간단하게 시뮬레이션할 수 있는 30큐비트를 사용합니다. GHZ 주 비밀 공유 또는 양자 비잔틴 계약과 같은 양자 통신 및 암호화의 여러 프로토콜에 사용되며 이러한 성격의 효과적인 양자 알고리즘을 개발하는 데 중요한 부분입니다.
출처
Nvidia CUDA Quantum은 cuQuantum 가속 상태 벡터 및 텐서 네트워크 시뮬레이션에 대한 기본 지원을 제공합니다.
아래 튜토리얼 단계를 참조하세요.
Rescale Batch – NGC Interactive 작업
작업 설정 가져오기 버튼을 클릭하여 샘플 작업에 액세스하고 직접 실행할 수 있으며, 아래 작업 결과 가져오기 버튼을 클릭하여 결과를 볼 수 있습니다.
Rescale에서 일괄 작업을 실행하는 단계
입력 파일 선택
작업 파일을 업로드합니다(필요한 경우 압축 파일을 사용하는 것이 좋습니다). 위에서 가져오기 작업 설정을 선택하면 자동으로 로드됩니다.
참고: Rescale 플랫폼은 압축된 파일을 이해하고 ./work/shared/ 폴더에 자동으로 압축이 해제됩니다.
이 경우 NGC 컨테이너 이미지에 이 튜토리얼의 모든 기본 예제가 통합되어 있으므로 입력 파일을 업로드할 필요가 없습니다.
소프트웨어 선택
소프트웨어 타일에서 NGC를 선택하고 아래와 같이 명령줄 및 API 세부 정보를 지정합니다.
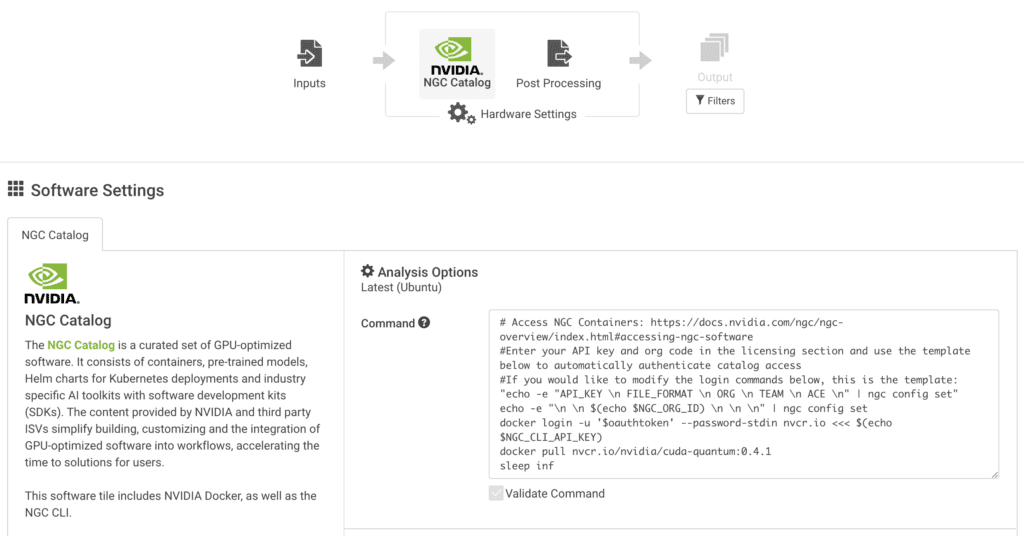
이 튜토리얼에서는 작성 당시 최신 버전의 Nvidia NGC CUDA Quantum(0.4.1)을 사용합니다.
일반적인 Rescale 배치 작업의 경우 Linux 터미널에서 실행할 모든 명령으로 미리 채워진 CMD 줄을 직접 수정할 수 있습니다. 이 NGC 컨테이너를 시작하고 관련 CUDA Quantum 이미지를 가져오는 방법은 아래 예를 참조하세요.
# NGC 컨테이너에 액세스: https://docs.nvidia.com/ngc/ngc-overview/index.html#accessing-ngc-software # 라이센스 섹션에 API 키와 조직 코드를 입력하고 아래 템플릿을 사용하여 자동으로 인증합니다. 카탈로그 액세스 #아래 로그인 명령을 수정하려면 다음 템플릿을 사용하십시오: "echo -e "API_KEY \n FILE_FORMAT \n ORG \n TEAM \n ACE \n" | ngc config set" echo -e "\ n \n $(echo $NGC_ORG_ID) \n \n \n" | ngc config set docker login -u '$oauthtoken' --password-stdin nvcr.io <<< $(echo $NGC_CLI_API_KEY) docker pull nvcr.io/nvidia/cuda-퀀텀:0.4.1 sleep inf
참고: 끝에 있는 'sleep inf' 명령은 도커 이미지를 성공적으로 가져온 후 Linux가 클러스터컴퓨팅 클러스터는 느슨하게 또는 긴밀하게 연결된 집합으로 구성됩니다. 더 보기 SSH를 통해 작업할 수 있도록 열려 있습니다. 그렇지 않으면 종료 코드가 0이고 작업이 완료되었다고 가정합니다.
예제를 실행하기 위해 소프트웨어와 명령줄을 지정했으면 다음으로 라이선스 옵션에서 NVIDIA API 키와 조직 코드를 지정하세요.
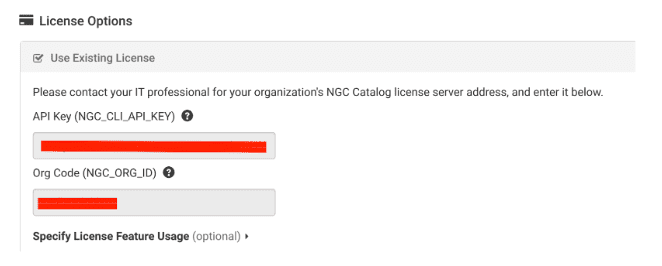
라이센스 기능 사용을 지정할 필요는 없습니다.
하드웨어 선택
다음 페이지에서는 분석을 위한 하드웨어를 선택하는 옵션을 찾을 수 있습니다. 여기에서 'A100 또는 V100' GPU를 검색하여 Rescale 플랫폼에서 사용 가능한 GPU 시스템을 표시할 수 있습니다. 다음은 이러한 유형의 연구에 대한 수요가 매우 높은 A100을 보여주는 검색 예입니다.

일단 하나를 집어들면 코어타입다양한 HPC에 맞게 사전 구성되고 최적화된 아키텍처... 더 보기, 머신에서 사용할 수 있는 GPU 수를 확인할 수 있습니다. 노드전통적인 컴퓨팅에서 노드는 네트워크의 객체입니다. ... 더 보기.

더 복잡한 예의 경우 여러 노드를 선택하여 시뮬레이션된 큐비트에 사용할 수 있는 GPU 수를 늘릴 수 있습니다. 내장된 예의 경우 기능을 시연하고 학습하는 데 충분한 최소 코어/노드가 있는 Nvidia GPU 중 하나를 선택하십시오.
선호하는 하드웨어를 선택하고 나면 '를 클릭할 준비가 된 것입니다.문의하기' 클러스터를 시작하고 NGC CUDA Quantum 컨테이너를 가져옵니다.
작업 모니터링
작업이 시작되면 내장된 웹 기반 SSH를 사용하거나 로컬 SSH 클라이언트를 통해 연결할 수 있습니다. 다음이 있습니다. process_output.log 클러스터 시작 및 명령 출력이 있는 위치에 대한 특정 정보를 Rescale에 알려줄 수 있는 추가 생성됩니다.
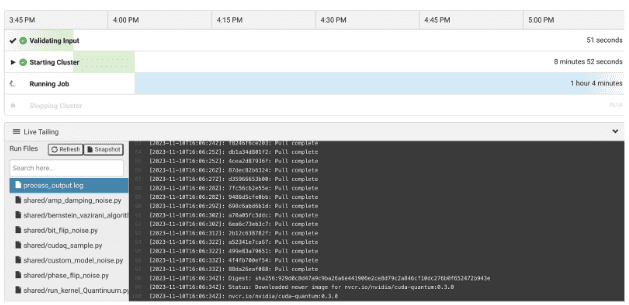
작업이 시작되면 SSH를 통해 클러스터에 액세스합니다.
CPU 및 GPU를 사용하여 Qubit 시뮬레이션
아래와 같은 명령을 사용하여 CUDA Quantum 이미지를 호출합니다.
docker run -it --gpus all --name cuda-퀀텀 nvcr.io/nvidia/cuda-퀀텀:0.4.1
참고: –gpus all 플래그를 언급하지 않으면 기본 CPU만 사용할 수 있습니다. 액세스하려는 CPU 외에 GPU 가속 백엔드에 대한 지원을 활성화하려면 컨테이너 시작 시 이 플래그를 실행하는 것이 좋습니다. QPU의 경우 컨테이너를 시작할 때 플래그가 필요하지 않습니다.
example/cpp 라이브러리에 있는 C++ 예제를 사용하겠습니다.
여기서는 내장된 예제 'cuQuantum_backends.cpp'에 따라 30큐비트에서 GHZ 상태를 생성합니다. 내장된 cuQuantum 상태 벡터 지원을 사용하여 실행하려면 다음을 전달합니다. –타겟 엔비디아 컴파일 타임에 플래그:
nvq++ --대상 nvidia example/cpp/basics/cu퀀텀_backends.cpp -o ghz.x
이제 아래 명령을 사용하여 Nvidia GPU에서 컴파일된 cu퀀텀_backends 예제를 실행합니다.
./ghz.x
그러면 아래 화면과 유사한 결과가 제공됩니다.

이제 궁금해서 이 코드를 컴파일하지 않고 컴파일하면 어떤 일이 발생하는지 자유롭게 시도해 보세요.–타겟 엔비디아 플래그를 지정하고 위와 같이 실행합니다. CPU가 과부하되는 것을 관찰하려면 새 SSH 세션을 여는 것이 좋습니다. 30큐비트는 CPU 기반 전용 컴파일과 충돌하거나 매우 오랜 시간이 걸립니다. 이는 실제 QPU에 액세스하기 전에 양자 회로 및 QPU의 동작을 시뮬레이션하기 위한 알고리즘 연구를 위해 GPU에서 이 예제를 실행하는 것의 가치를 보여줍니다. 따라서 최상의 테스트 후에 비용/리소스가 활용되고 있는지 확인할 수 있습니다. HPC고급 애플리케이션 실행을 위한 병렬 처리 사용 더 보기 인프라를 사용할 수 있습니다.
Quantum 하드웨어 제공업체에 작업 보내기
이제 기존 HPC 인프라를 사용하여 Quantum 알고리즘을 '시뮬레이션'하는 방법을 살펴보았으므로 동일한 인터페이스를 사용하여 전문 Quantum 공급자(Nvidia에서 지원하는 Quantum 하드웨어 파트너)에게 작업을 보내는 방법을 살펴보겠습니다.
다양한 Quantum 공급자에 대한 C++ 예제 작업은 기본적으로(작성 당시) 다음 디렉터리에 배치됩니다.
이 예에서는 IONQ Quantum 백엔드를 살펴보고 Nvidia CUDA Quantum에서 지원되는 다른 Quantum 하드웨어 공급자에 대해서도 동일한 방법을 따를 수 있습니다. 이 예제에서는 IonQ에서 실행할 간단한 양자 커널을 컴파일하고 실행합니다.
우선 IonQ 계정과 API 키가 필요합니다. IonQ 계정에서 API 키를 생성하고 환경 변수로 내보냅니다.
IONQ_API_KEY="ionq_generated_api_key" 내보내기
그런 다음 이번에는 대상을 ionq로 지정하여 다음 명령을 실행합니다.
nvq++ --target ionq example/cpp/providers/ionq.cpp -o out.x
이 명령은 IonQ의 대상을 하드웨어 공급자로 사용하여 C++ 예제를 컴파일합니다. 기본적으로 대상 양자 컴퓨터를 지정하지 않으면 기본 구성인 'Simulator'라는 IonQ 머신으로 이동합니다. "nvq++ –target ionq –" 명령을 사용하여 IonQ에서 사용 가능한 대상 양자 컴퓨터를 지정할 수 있습니다. ionq-machine qpu.aria-1 example.cpp”. 작업에 사용할 수 있는 Quantum 머신의 전체 목록은 IonQ 웹사이트에서 얻을 수 있습니다.
준비가 되면 다음 명령을 실행하여 IonQ에서 예제를 실행합니다.
./out.x
IonQ에서 프롬프트로 아래와 같은 출력을 다시 받게 됩니다.
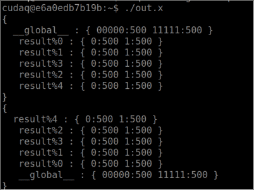
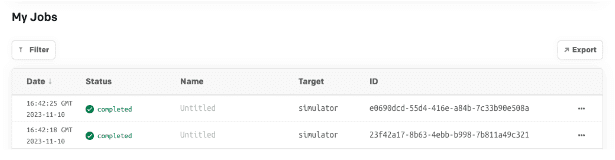
IonQ API 작업 로그에서 작업 실행을 교차 검증하여 실행한 작업과 Quantum 공급자에서 사용된 하드웨어를 확인할 수 있습니다.
요약
이 튜토리얼은 확장 가능하고 민첩한 HPC 인프라에 액세스하여 NGC CUDA Quantum 이미지를 실행하고 CPU, NVidia GPU 및 NVidia 지원 QPU 하드웨어 공급자를 지원하는 다양한 하드웨어에서 양자 알고리즘 연구 및 시뮬레이션을 수행하는 쉬운 방법을 제공하는 것으로 마무리됩니다.
참고자료
엔비디아
위키 백과