
Rescale の NGC CUDA Quantum

概要
このチュートリアルでは、NGC を使用して Rescale プラットフォームで NGC CUDA Quantum を使い始める方法を学びます。 コンテナ画像 これには、すべての CUDA Quantum リリースが含まれています。
Nvidia CUDA Quantum イメージ内の組み込みサンプルを使用して、量子アルゴリズムの調査を実行するための Rescale プラットフォームの俊敏性、スケーラビリティ、および使いやすさを実証します。 シミュレーションは実験であり、シナリオをテストし、作成することです... その他 例。
注: NGC からイメージをプルするための前提条件である API キーと組織 ID にアクセスできるようにするには、Nvidia アカウントが必要です。 コンテナ自立型アプリケーションとオペレーティング システムのパッケージ その他 レジストリとその中での作業。 QPU を使用する場合は、関連するバックエンド QPU ハードウェア プロバイダーのアカウント/API キーも必要になります。 アン アーキテクチャ上の前提条件 CUDA Quantum では、リストされている GPU アーキテクチャ (Volta、Turing、Ampere、Ada、Hopper) が利用可能です。 Rescale でのこれらの GPU アーキテクチャの可用性と容量については、Rescale ソリューション アーキテクトにお問い合わせください。
Nvidia CUDA Quantum は、「バッチ」ジョブ (より便利には「ヘッドレス」ジョブと呼ばれます) を使用して SSH を使用して CUDA Quantum を操作するか、Rescale ワークステーション (ヘッドノード上の GUI) を対話的に使用して実行できます。 どちらのオプションでも、Nvidia の高性能なハードウェアを含む、Rescale プラットフォーム上のさまざまなハードウェアへのアクセスが提供されます。 GPUGPU (グラフィックス プロセッシング ユニット) は、特殊な電子プロセッサです。 その他.
Rescale プラットフォーム上の NGC CUDA Quantum イメージを使用して量子アルゴリズムの研究を検討することを検討します。まず、基盤となる Nvidia GPU を使用して量子ビットをシミュレーションし、次に Nvidia パートナー Quantum ハードウェア プロバイダー (IonQ) のいずれかの量子シミュレーター バックエンドにサンプル ジョブを送信します。 。
まず、シミュレートする組み込みのサンプルを起動します。 GHZ 諸国 30 量子ビットを使用します。これは標準の CPU のみのシミュレーターには大きすぎますが、NVIDIA GPU アクセラレーション バックエンドを介して簡単にシミュレートできます。 GHZ 諸国 これは、秘密共有や量子ビザンチン協定など、量子通信や暗号化のいくつかのプロトコルで使用されており、この種の効果的な量子アルゴリズムを開発する上で重要な部分です。
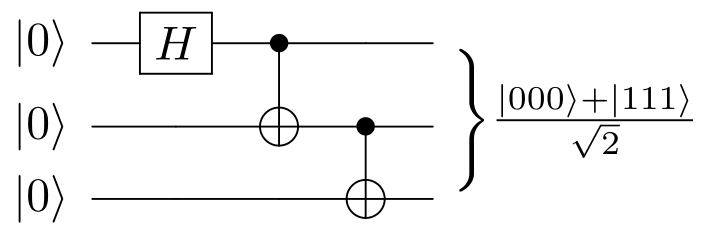
ソース
Nvidia CUDA Quantum は、cuQuantum で高速化された状態ベクトルおよびテンソル ネットワーク シミュレーションのネイティブ サポートを提供します。
以下のチュートリアルの手順を参照してください。
バッチの再スケール – NGC インタラクティブ ジョブ
[ジョブ セットアップのインポート] ボタンをクリックしてサンプル ジョブにアクセスして直接起動するか、下の [ジョブ結果の取得] ボタンをクリックして結果を表示できます。
Rescale でバッチ ジョブを実行する手順
入力ファイルの選択
ジョブ ファイルをアップロードします (必要に応じて、圧縮ファイルを使用することをお勧めします)。 これらは、上で [ジョブ セットアップのインポート] を選択すると自動的にロードされます。
注: Rescale プラットフォームは圧縮ファイルを認識し、./work/shared/ フォルダーに自動的に解凍されます。
この場合、NGC コンテナー イメージにはこのチュートリアルのすべての基礎となるサンプルが組み込まれているため、入力ファイルをアップロードする必要はありません。
ソフトウェアを選択
ソフトウェア タイルで NGC を選択し、以下のようにコマンド ラインと API の詳細を指定します。
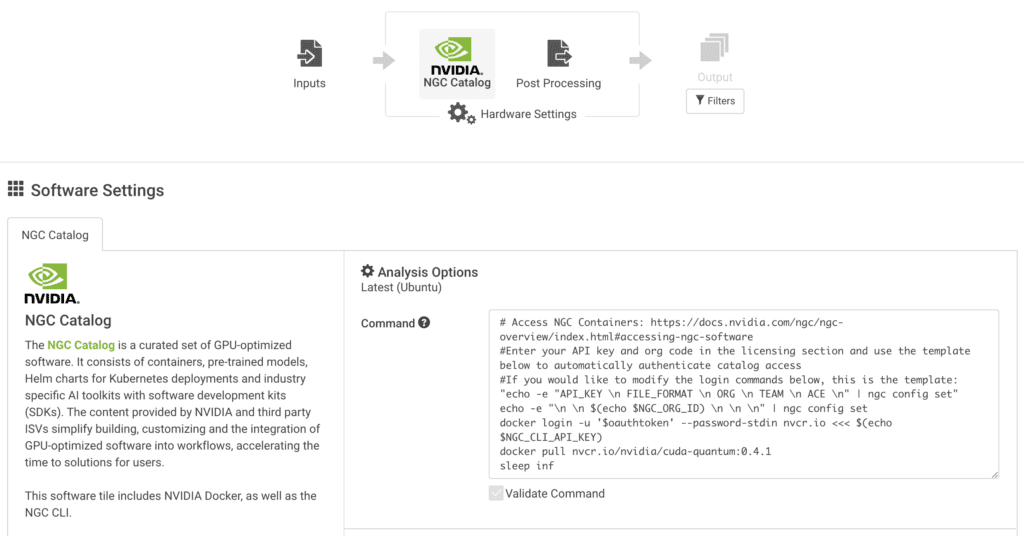
このチュートリアルでは、執筆時点での Nvidia NGC CUDA Quantum の最新バージョン (0.4.1) を使用します。
一般的な Rescale バッチ ジョブの場合、Linux ターミナルで実行するすべてのコマンドを含む事前設定された CMD 行を直接変更できます。 この NGC コンテナを起動し、関連する CUDA Quantum イメージをプルする方法については、以下の例を参照してください。
# NGC コンテナーにアクセスします: https://docs.nvidia.com/ngc/ngc-overview/index.html#accessing-ngc-software #ライセンス セクションに API キーと組織コードを入力し、以下のテンプレートを使用して自動的に認証しますカタログ アクセス #以下のログイン コマンドを変更する場合、これはテンプレートです: "echo -e "API_KEY \n FILE_FORMAT \n ORG \n TEAM \n ACE \n" | ngc config set" echo -e "\ n \n $(echo $NGC_ORG_ID) \n \n \n" | ngc config set docker login -u '$oauthtoken' --password-stdin nvcr.io <<< $(echo $NGC_CLI_API_KEY) docker pull nvcr.io/nvidia/cuda-quantum:0.4.1 sleep inf
注: 最後に「sleep inf」コマンドを実行すると、Docker イメージのプルに成功した後、Linux が コンピューティング クラスターは、緩やかまたは緊密な一連のコンピューティング クラスターで構成されます。 その他 SSH 経由で操作できるように開いたままにします。 それ以外の場合は、終了コード 0 が返され、ジョブが完了したものとみなされます。
ソフトウェアとサンプルを実行するコマンド ラインを指定したら、次にライセンス オプションで NVIDIA API キーと組織コードを指定します。
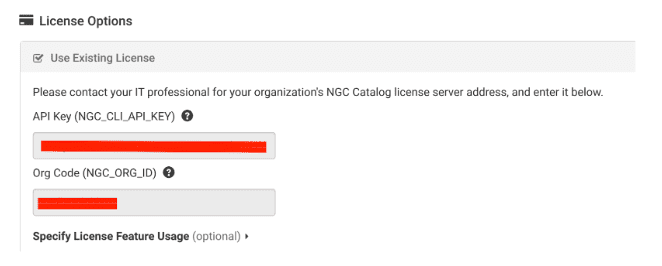
ライセンス機能の使用を指定する必要はありません。
ハードウェアを選択
次のページでは、分析用のハードウェアを選択するオプションが表示されます。 ここで、「A100 または V100」GPU を検索すると、Rescale プラットフォームで利用可能な GPU マシンが表示されます。 以下は、この種の研究で非常に需要の高い A100 を示す検索例です。

一度手に取ったら、 Coretypeさまざまな HPC 向けに事前構成され最適化されたアーキテクチャ... その他、マシン上で利用可能な GPU の数を確認できます / 従来のコンピューティングでは、ノードはネットワーク上のオブジェクトです。 ... その他.

より複雑な例では、複数のノードを選択して、シミュレートされた量子ビットに使用できる GPU の数を増やすことができます。 組み込みの例では、機能を実証して学習するのに十分な最小限のコア/ノードを備えた Nvidia GPU の XNUMX つを選択します。
好みのハードウェアを選択したら、「」をクリックします。送信' と入力してクラスターを起動すると、NGC CUDA Quantum コンテナーがプルされます。
ジョブモニタリング
ジョブが起動すると、組み込みの Web ベースの SSH を使用するか、ローカル SSH クライアント経由で接続できます。 があることに注意してください。 process_output.log クラスターの起動場所とコマンド出力の場所に関する Rescale 固有の情報を通知できる追加のツールが作成されます。
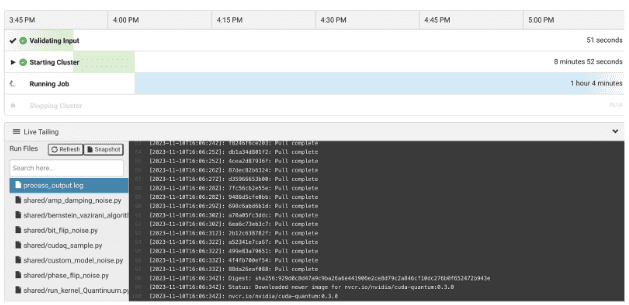
ジョブが起動したら、SSH 経由でクラスターにアクセスします。
CPU と GPU を使用した量子ビットのシミュレーション
次のコマンドを使用して、CUDA Quantum イメージを呼び出します。
docker run -it --gpus all --name cuda-quantum nvcr.io/nvidia/cuda-quantum:0.4.1
注: –gpus all フラグを指定しない場合は、デフォルトの CPU のみを使用できます。 アクセスしたい CPU に加えて、GPU アクセラレーションのバックエンドのサポートを有効にするために、コンテナーの起動時にこのフラグを実行することをお勧めします。 QPU の場合、コンテナーの起動時にフラグは必要ありません。
Examples/cpp ライブラリにある C++ サンプルを使用します。
ここでは、組み込みサンプル「cuquantum_backends.cpp」に従って 30 量子ビットで GHZ 状態を生成します。組み込みの cuQuantum 状態ベクトル サポートで実行するには、 –ターゲットnvidia コンパイル時のフラグ:
nvq++ --target nvidia Examples/cpp/basics/cuquantum_backends.cpp -o ghz.x
次に、以下のコマンドを使用して、コンパイル済みの cuquantum_backends サンプルを Nvidia GPU で実行します。
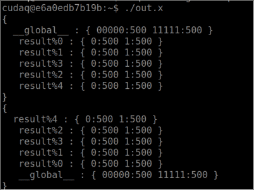
./ghz.x
これにより、以下の画面のような結果が表示されます。

ここで、好奇心のために、このコードを何もせずにコンパイルするとどうなるかを自由に試してみてください。–ターゲットnvidia フラグを立てて、上記のように実行します。 新しい SSH セッションを開いて、CPU の過負荷を観察することをお勧めします。 30 量子ビットは、CPU ベースのみのコンパイルをクラッシュさせるか、非常に長い時間がかかります。 これは、実際の QPU にアクセスする前に量子回路と QPU の動作をシミュレートするためのアルゴリズム研究のためにこの例を GPU で実行する価値を示しています。これにより、最適なテストを行った後にコスト/リソースが確実に活用されるようになります。 (HPC)高度なアプリケーションを実行するための並列処理の使用 その他 インフラストラクチャが利用可能です。
量子ハードウェアプロバイダーへのジョブの送信
従来の HPC インフラストラクチャを使用して量子アルゴリズムを「シミュレート」する方法を確認したので、同じインターフェイスを使用して特殊な量子プロバイダー (Nvidia がサポートする量子ハードウェア パートナー) にジョブを送信する方法を見てみましょう。
さまざまな Quantum プロバイダーの C++ サンプル ジョブは、デフォルトで (執筆時点では) 次のディレクトリに配置されます: example/cpp/providers
この例では IONQ Quantum バックエンドを見ていきますが、Nvidia CUDA Quantum でサポートされている他の Quantum ハードウェア プロバイダーについても同じ方法に従うことができます。 この例では、IonQ で実行する単純な量子カーネルをコンパイルして実行します。
まず、IonQ のアカウントと API キーが必要です。IonQ アカウントから API キーを生成し、それを環境変数としてエクスポートします。
エクスポート IONQ_API_KEY="ionq_generated_api_key"
次に、今回はターゲットを ionq として指定して、次のコマンドを実行します。
nvq++ --target ionq 例/cpp/providers/ionq.cpp -o out.x
このコマンドは、ハードウェア プロバイダーとして IonQ のターゲットを使用して C++ サンプルをコンパイルします。 デフォルトでは、ターゲットの量子コンピュータを指定しない場合、デフォルト構成である「Simulator」という名前の IonQ のマシンに移動します。「nvq++ –target ionq –」のコマンドを使用して、IonQ で利用可能なターゲットの量子コンピュータを指定できます。 ionq-machine qpu.aria-1 example.cpp」。 ジョブに利用可能な量子マシンの完全なリストは、IonQ の Web サイトから入手できます。
準備ができたら、次のコマンドを実行して IonQ で例を実行します。
./out.x
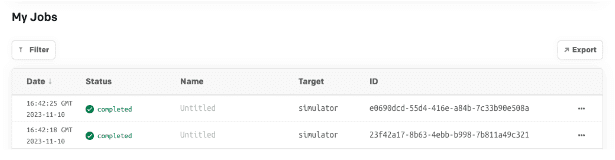
以下のような出力が (IonQ から) プロンプトに返されます。
IonQ API ジョブ ログで実行したジョブを相互検証できます。これにより、実行したジョブと、Quantum プロバイダーで使用されたハードウェアが確認されます。
まとめ
このチュートリアルの最後では、スケーラブルで機敏な HPC インフラストラクチャにアクセスして NGC CUDA 量子イメージを起動し、CPU、NVidia GPU、および NVidia がサポートする QPU ハードウェア プロバイダーをサポートするさまざまなハードウェアで量子アルゴリズムの調査とシミュレーションを実行する簡単な方法を提供します。
参考文献
Nvidia
Wikipedia