Cost Optimizing Your Rescale Job

Rescale offers various software with on-demand licensing. This software is popular because of the pay as you go nature. Not only does this software provide an easy way of accessing the software, but many software is priced in such a way that they encourage running on more cores and therefore providing a faster turnaround time to solution.
As far as on-demand software pricing goes, most software fall in 4 general per-hour pricing categories:
- Proportional – you pay proportionally to the number of cores you use
- Flat Rate – you pay a flat rate per hour, no matter how many cores you use
- Capped – you pay proportionally up to a certain number of cores and pay a flat rate after that
- Discounted – you pay a nominal rate for the first core and pay less for each subsequent core
It is clear that a proportional rate does not benefit the customer when scaling up to many cores, however, the other three pricing models may benefit the customer by running more cores. In reality, the benefit is based both on the pricing model as well as the scalability of the job and software. The scalability is the assumption that a given job will run faster on more cores.
What I intend to show in this blog post is that certain software pricing models provide the opportunity to run your job faster and on more cores while actually paying less.
Nomenclature
This is not a scientific paper, however, I will provide some equations to illustrate some of the concepts related to price and scaling. To make the equations easier to understand here are some definitions
| hw | Hardware |
| I | Number of iterations |
| k | Some per-unit constant |
| K | Some constant |
| N | Number of Cores or Processes |
| p | Unit price |
| P | Price |
| sw | Software |
| t | Time per iteration |
| T | Total Time |
The Problem
An engineer has a model and wants to know the most cost efficient way of running his model on Rescale. Because the cost of the job is a sum of both hardware and software cost, we need to take into account the pricing models for each. The hardware cost is charged by Rescale on a proportional basis. The software cost is priced depending on the software vendor’s (ISV’s) pricing model. The total hourly price would look something like:
Ptotal = Phw + Psw
The total cost of the job would be the product of the hourly price and the duration of the job. This is the value we want to minimize.
Total Cost = (Phw + Psw) * Total Simulation Time
As explained before, we can say that the time it takes to run the job and the per hour prices are a function of the number of cores used.
Phw = f(N) = phw * N
Psw = f(N)
T = f(N)
With this information, we can now try to optimize the cost of the entire job.
Hardware Pricing
Hardware is charged by Rescale on a proportional basis. The per hour price is based on a per core hour rate which differs between the different core types and pricing plans available on Rescale. Simply put, the hourly hardware price equation is the product of the per core hour rate and the number of cores:
Phw = phw* N
Software Pricing
On-demand software pricing is set by the ISVs. As discussed before, there are several different pricing categories. The equations for obtaining the hourly software price as a function of the number of cores are fairly straightforward:
| Proportional | Psw = k * N |
| Flat Rate | Psw = K |
| Capped | Psw = min(K, k * N) |
| Discounted | Psw = K * f(N) For Example: Psw = K * N.9 |
Simulation Time and Software Scalability
The time to run a simulation over N processes / cores can be approximated by the following equation:
Tsimulation = Tserial (1 / N + k1 * (N – 1)k2)
Where Tserial is the time it takes to run the simulation in serial. The blue part describes the raw compute time while the red part describes the communication overhead. If you are interested in the justification, read on. Otherwise skip to “Costimizing”.
The details:
There are many ways of modeling scalability. Amdahl’s law is often quoted as representing scalability relative to the different parts of the simulation which benefit from scaling over extra resources. It does not, however, address how to define or quantify the benefit of extra resources. In our case, we have a fixed sized model and we want to know how it will perform when we scale it over an increasing number of hardware cores. So, for illustrative purposes, let’s make a few assumptions:
- The simulation is iterative
- The simulation is distributed over N processes on N cores
- Each process requires information from other processes to calculate the next iteration and uses MPI
- The number of iterations, I, to finish the simulation is independent of N
- The number of compute cycles required to complete an iteration is independent of N
Given these assumptions, the time it takes to complete an iteration is:
titeration = tcompute + tcommunicate
if compute and communicate are synchronous operations. Otherwise, when considering them to be asynchronous (non-blocking) operations,
titeration = max(tcompute, tcommunicate)
Lastly the total compute time is easily calculated from the iteration time and the number of iterations.
T = titeration * I ∝ titeration
Here we assume that each iteration is more or less equal.
Compute Time
For compute time, assumption (5) gives us
tcompute = tserial / N
This is telling us that given no communication overhead, our model will have linear strong scaling. It also tells us that the larger the model (tserial), the larger tcompute and the less detrimental effect communication overhead has on the relative solution time because of the dominance of tcompute. The result is that larger models scale better.
Communication Time
The time to communicate is more complicated and depends, among other things, on how fast the interconnect is, how much data needs to be communicated, and the number of processes N.
Let’s simplify and break it down.
The communication time between two processes can be defined as 2 parts: the communication overhead (latency) and the data transfer time (transfer). So, to send one message from process to another we can for now simply define:
tmessage = tlatency + ttransfer = tlatency + (transfer rate * message size)
The transfer rate is lower for small messages and increases as the messages become bigger, peaking at the bandwidth of the interconnect. We can assume for now that the latency is constant for a given interconnect.
To see the effect in practice, this paper (https://mvapich.cse.ohio-state.edu/static/media/publications/abstract/liuj-sc03.pdf) investigates the performance of MPI on various interconnects. What the paper shows is that for small message sizes, the communication time is more or less constant.
tmessage ≅ k
With this knowledge, we can infer that the total time to communicate depends on the number of messages being sent by each process. The number of messages sent in turn depends on the number of processes because, presumably, each process communicates with every other process. An equation that can then be used to model the number of messages sent is:
Messages = k1 * (N – 1)k2 ∝ tmessage
Furthermore, we can normalize k1 by the number of iterations and therefore tserial
tcommunicate = tserial * k1 * (N – 1)k2 ∝ tmessage
Putting it Together
The total time for the simulation is
Tsimulation ∝ titeration = tcompute + tcommunicate
when compute and communication are synchronous (blocking) operations. By substitution,
Tsimulation = Tserial (1 / N + k1 * (N – 1)k2)
Obtaining the Constants
The constants can be obtained through fitting the equation to empirical benchmark data. The communication overhead model, which is presented here, is by no means an end-all. It has been shown from our internal benchmarks that this equation fits well with almost all scaling numbers.
Furthermore, we have found that usually k2 ≅ 0.5. We have also found that k1 is a function of model size, interconnect type, and processor performance.
Costimizing
Let’s go back to our total cost equation:
Total Cost = (Phw + Psw) * Tsimulation
The total cost now depends on the software pricing model used.
Total Cost = f(N) = (phw * N +Psw) * Tserial (1 / N + k1 * (N – 1)k2)
An Excel calculator can be found here [link]. Here is an example output: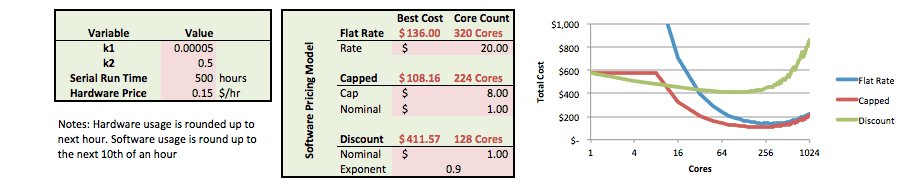
How We Can Help
Rescale’s support team can help you estimate the right number of cores to run your simulation on. It is not always feasible to run benchmarks for every single use case, and from the example above, being a few cores off doesn’t have a huge impact on the cost you save.
What we want you to be aware of, is that with a good scaling software and a flat rate or capped pricing model it is often more cost efficient to run on more cores.