

Best Practices for Running HPC Batch Jobs
Understand what HPC batch jobs are, how they differ from typical IT batch jobs, and the key considerations for setting up hardware infrastructure and the network fabric for running HPC clusters
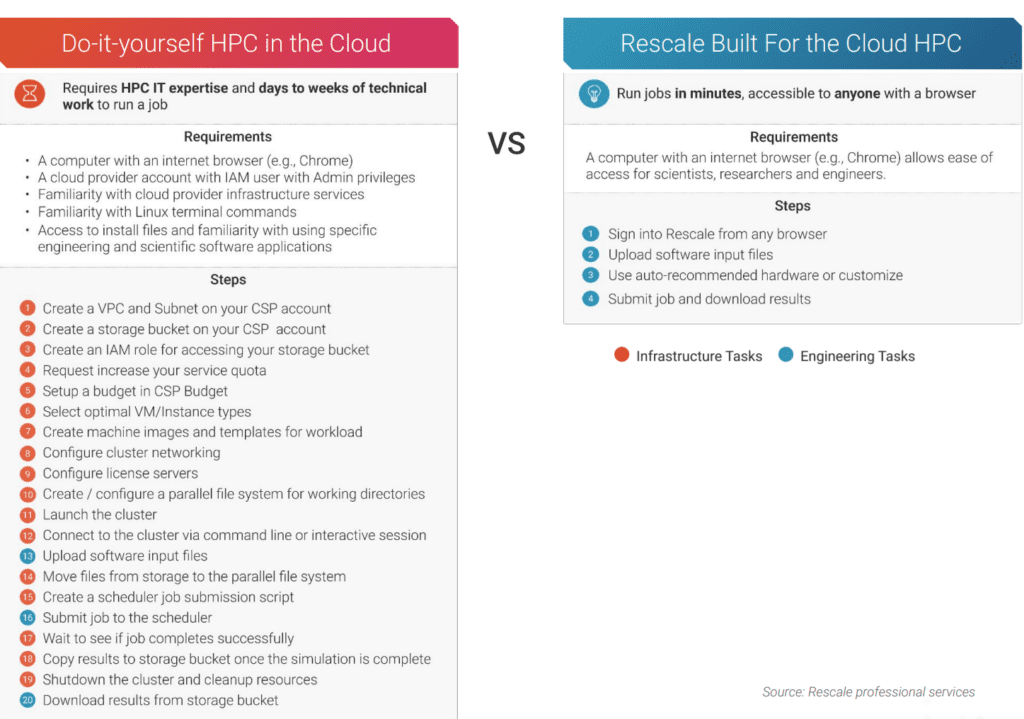
Rescale’s engineering team is dedicated to solving the complexities of managing high performance computing (HPC) systems in this era of hybrid and multi-cloud computing.
Fundamental to HPC for R&D is creating a compute job to carry out a digital simulation or other kind of analysis. So a key area of focus for the Rescale engineering team is in automating many of the tasks required to successfully set up a simulation job or other big compute task.
In this two-part blog post series, I will cover the key aspects of configuring a compute environment for running HPC batch jobs and other management consideration, regardless of the tools you use or your infrastructure (on-premises or cloud).
In this first post, I will start by defining what HPC batch jobs are, how they differ from typical IT batch jobs, and the considerations for setting up hardware infrastructure and a network fabric for running HPC clusters.
HPC Batch Computing, Defined
In the HPC world, batch jobs are about setting up the hardware to run your software application to carry out a specific kind of computational task (usually for digital simulations).
Once you set up your compute environment, you can hit “go” and let the infrastructure and software carry out the job. After the HPC job is completed, researchers and engineers can review the results and begin their analysis.
With HPC batch jobs, setting up the compute environment the right way is critical. HPC workloads can vary greatly in their compute needs, so the key is to configure the infrastructure to ensure critical performance and reliability. It is costly in many ways if a simulation fails or doesn’t produce the intended results because of software or hardware configuration errors.
These simulations often need to use significant computer resources over a long period of time. That is expensive. While using just one node (one computer in a supercomputing cluster) is not uncommon, simulations often require 20 or 50 nodes, which could be on the order of thousands of CPU cores. Those simulations might take anywhere from half an hour to a week or more. We have some customers who are running very long simulations over days or weeks, but four to eight hours is a typical runtime for a HPC batch job to complete a digital simulation.
HPC Batch Jobs: Not Your Typical IT Batch Job
There are many kinds of IT batch jobs, but if you are talking about a common task like updating a database, those batch jobs are more about making sure something runs at a particular time rather than getting the highest performance out of your hardware.
The primary goal of the common IT batch job is: run it, don’t fail, and don’t get in anybody else’s way. It’d be great if it ran fast, but the whole point is to find a chunk of data center time overnight when the batch job can take its sweet time processing without interfering with other tasks. The task just needs to be completed at some point. Speed is simply not a factor for common IT batch jobs.
With HPC batch jobs, it’s all about speed and efficiency. Given the costs of running your own supercomputers or renting them in the cloud, you need to make sure your compute resources are optimally tuned, whether in the cloud or in your own data center.
Even with the unconstrained resources of the cloud, you still need to do a lot more work to make sure your HPC batch jobs run the right way compared to a typical overnight enterprise IT batch job.
In setting up an HPC batch job, you first need to make sure you are using the best chip architecture and extensions available to those chips. Different generations of Intel chips or AMD chips will have different capabilities, and often the software needs to be configured and compiled to take advantage of those.
So there are significant matching issues you need to consider between hardware and software. And this is becoming more challenging as the number of specialized semiconductor chips rapidly expands. The right match between hardware and software can have profound implications for cost, speed, and energy consumption.
Key Considerations for Setting Up Batch Jobs
Given the critical need to ensure your HPC batch jobs run successfully and at the necessary performance levels, you will want to have the right hardware best suited for the type of application you will run. Different simulation applications have very different requirements. Some are very memory intensive, some are very CPU compute intensive. Some require special purpose semiconductor chips like GPUs.
So, the first thing you want to do is figure out which type of hardware you want to use to run your simulation. If you optimize for the wrong hardware, the batch job could take substantially more time, even by an order of magnitude. So you’re just waiting longer and potentially spending more money on that compute time.
There’s also a trade-off to consider between compute speed and software costs. Licensing varies a lot, but the sophisticated and specialized applications used in R&D are typically expensive to run and licensing costs are based on a consumption model (time spent using the application to run simulations or other analysis).
Given this, it can be advantageous to spend more money on faster compute resources to shorten the time of a HPC batch job to save software costs. Often what you want to do is optimize for running in the least amount of time—or the least amount of CPU core hours—to optimize for your license costs, because those are often much more than the hardware costs depending on the application and the situation.
The Critical Importance of the Right Network Fabric
There’s another axis of complexity that isn’t typical with IT batch jobs: the network fabric and connectivity. Different compute clusters have different types of network fabric that connect all the nodes together. This is not typically an issue with standard IT compute jobs. Those just need a couple of servers.
One of the big challenges that the engineering team at Rescale focuses on is on how inter-node communication works and how that affects the performance of a HPC application.
Typically, a lot of these jobs are big simulations. You’re going to need to run those on more than one node. And a lot of these applications also assume a fine-grained communication model between the nodes.
So if you set up your cluster or if you set up your communication libraries suboptimally, that could really lengthen the time that your simulation runs, leading to a lot of inefficiencies.
For many HPC applications, you need to make sure your nodes have very low-latency connectivity between all of them, to make sure that all this fine-grained, multi-node communication works well.
And there are many ways to build that inter-node communication network. You could use high-bandwidth Ethernet or go with InfiniBand, which provides lower latency, higher bandwidth than most Ethernet options. There are several other network fabric types as well.
Also, a lot of HPC applications use a library layer called MPI (message passing interface). But MPI is only a standard, not a library itself. Vendors and developers create their own libraries based on the MPI standard.
So you need to make sure that the type of MPI you’re using works well with the type of hardware you’re using. In other words, you have to match not just the hardware with the simulation application, but the hardware with the middleware layer (the library) and then with the application itself.
The MPI needs to be configured for specific types of network fabric. And configuration needs vary a lot across different network fabrics. It’s not something that you can set once for a single network fabric and expect it will work reasonably well in all cases. There’s a big variance in performance if you don’t tune that.
And it depends on the application. But for a lot of HPC batch jobs, you’re more network-bound than compute-bound, because you have to pass all this fine-grained information between the different nodes for the simulation to progress. Then you also need to make sure that the libraries that guide communications between nodes are set up the right way.
For HPC batch jobs, the bottomline is always the same: If you don’t have the whole stack of hardware and software optimized for your HPC workload, you won’t gain all the benefits of that expensive hardware and software.
This concludes part one of this series. In part two, I will dive deeper into key issues for running HPC batch jobs, including scheduling jobs, the costs of faulty HPC jobs, security, and multi-cloud management. Stay tuned!
Learn more about Rescale’s Intelligent Batch capabilities
Ensure all your high performance computing jobs are
set up the right way to run fast, efficiently, and dependably.






