

Find the Right HPC Cloud Architecture for Your Needs
With the rapid expansion of high performance cloud services and the specialization of chip architectures, organizations have growing options but face increasing complexities
It truly is an amazing time to be in digital R&D. The old constraints of on-premises data centers are being replaced with virtually unlimited elastic capacity of cloud-based supercomputing services. No longer do researchers and engineers have to sit in queues waiting to access a limited and highly valuable resource.
But this also means that there’s a lot of choices. Which cloud provider should we use? Should we be single or multi-cloud? Which high performance computing (HPC) services are best for us? What chip architecture should we use?
And critically, HPC cloud services and the chip architectures that support them are rapidly evolving. The variety and number of chips is exploding. That is driving a ton of options for HPC users, but it’s also creating significant complexity.
The good news? Rescale has created Performance Profiles to simplify the challenge of chip choices. Let’s dive into these trends and how Rescale can help.
A New Era for HPC
HPC cloud services have seen a surge in demand in the past decade, driven by the rapid growth of digital R&D to run complex models and simulations of real-world physics. HPC encompasses an ecosystem of computing, application, storage, and networking resources that are strategically pooled to solve complex computational problems.
Cloud technology is at the forefront of the HPC revolution, helping organizations across industries harness data processing power that exceeds what traditional data center environments can offer. HPC in the cloud offers unprecedented levels of performance, efficiency, and flexibility to organizations looking to drive the digital transformation of their R&D programs.
Cloud adoption has grown exponentially in recent years, with companies spending over 30 percent of their IT budgets on cloud infrastructure. This growth is for good reason. The cloud offers unparalleled benefits, including on-demand access to shared resources and cost savings due to the elimination of expensive in-house server equipment.
The Growth of Specialized Chips
Coupled with the expansion of cloud-based HPC services, the massive growth of specialized chips is transforming high performance computing for R&D, offering supercomputing power tuned for specific workloads.Specialized chips aim to address the inefficiencies of general-purpose central processing units (CPUs).
These new chips come in different forms, including graphic processing units (GPUs), field-programmable gate arrays (FPGAs), and application-specific integrated circuits (ASICs). They are designed to accelerate computation for specific tasks, such as artificial intelligence (AI), machine learning (ML), and big data analytics.
The proliferation of specialized chips is driving performance. Moore’s Law has been flattening over the last twenty years, meaning that traditional chips haven’t been increasing in performance as fast as they did during the earlier days of the computer industry.
As a result, the market has been shifting to specialized semiconductor computing architectures to gain new efficiencies in speed, cost, and energy efficiency.The diversity of chip architectures is exploding. The number of specialized chips has increased 1,000 percent in the past 10 years. In 2020, for example, more than 400 new chip types (core types and instances) entered the market. Now more than 1,450 different chip types (core types and instances), and this is only accelerating.
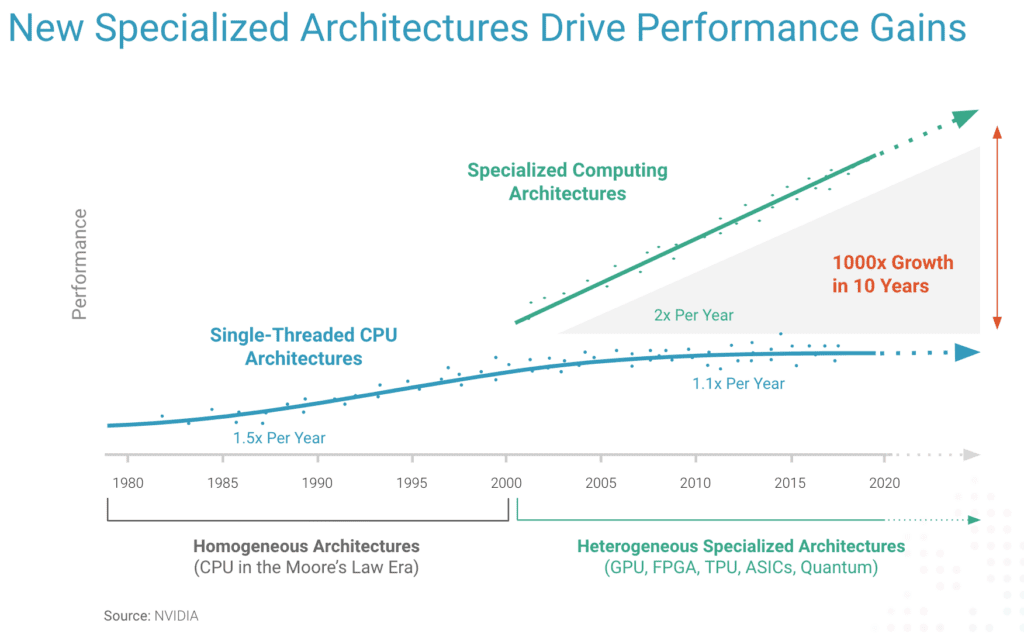
to drive performance for data-intensive R&D computing tasks.
This amazing growth is fueled by the rapid adoption of Arm architectures and a new paradigm of how chips are made. Companies like AWS, Microsoft, and Google have all made their own chips to support their cloud operations.
Critically, these specialized chips are designed for specific compute tasks. One chip might be excellent at parallel tasks while one might be provide the fastest speeds for single-threaded, data-intensive computational tasks. And neither of these would be the best choices for every task and every workload.
For example, if you are running a computational fluid dynamics (CFD) or finite element analysis (FEA) simulation, which software are you going to run? They’re going to operate differently. Each variable that you introduce is going to result in a different chip that will provide optimal performance for the given task.
Let’s take a closer look at those trade-offs. Picking the right chip for the right application and computational task really makes a big difference in performance, cost, and energy efficiency.
Picking the Right Chip Architecture for R&D Compute Needs
The first use case to look at is optimizing simulation run times. By selecting the right hardware, users can allocate the necessary resources to their simulations to make them run faster when time is a factor, such as for auto parts makers designing new equipment to win new contracts.
Alternatively, you might be looking at reducing simulation costs. By selecting the right hardware, users can minimize the amount of software licensing time they need to run their simulations, therefore reducing overall costs to run a simulation.
This can be particularly useful where budgets are limited. In these economic times, organizations have to be more cost-conscious than ever. To control your cloud costs, reducing total usage time with faster hardware can be extremely beneficial.
A third use case is scaling simulations. As simulations scale, they will perform differently with different hardware, particularly in use cases where they need to be run on multiple clusters or need more memory.
These three use cases are just a tiny sampling of all the possible R&D use cases for high performance computing. And in most situations, all three of these needs will blend together.
You’re not going to want just the fastest or the cheapest or the biggest scale. And often that is about cost-performance trade-offs. Which chip on which cloud service is going to best help you accelerate your innovation efforts?
Barriers to Effective Benchmarking
Understanding the performance, costs, energy efficiency, and scalability of any HPC architecture is critical. To gain this understanding, organizations traditionally could benchmark certain hardware, testing them on their applications. But today new chips are entering the market rapidly, making it difficult for an organization to keep pace with their benchmarking.
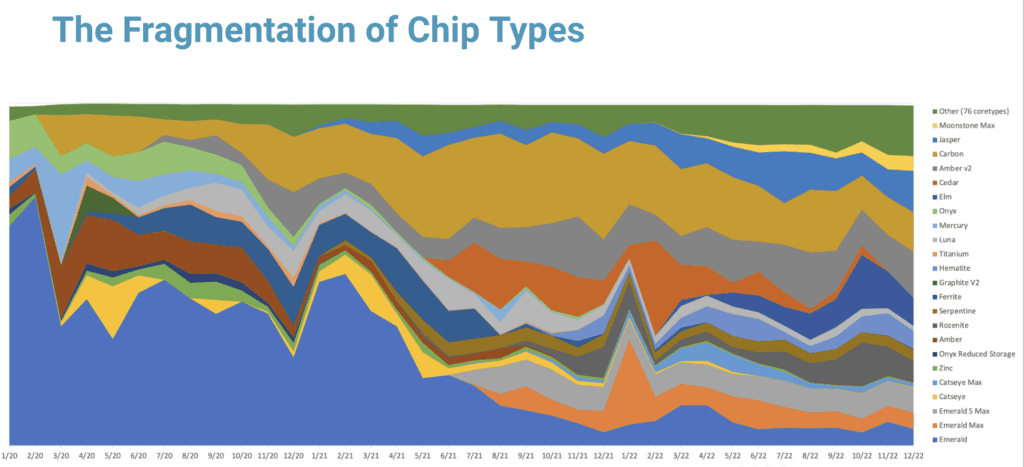
And benchmarking isn’t easy. The effort to get started with HPC benchmarking can be a time-consuming process. It requires significant effort to set up and run the benchmarks. This can be particularly challenging for organizations that lack the necessary expertise or resources to perform them.
Today, it is challenging to identify the best hardware to test. And you might want to use various chips with different system attributes, maybe different CPU memory storage or networks. If you don’t keep up with the latest and greatest chip types as they’re introduced, you might fall behind.
Also, analyzing and interpreting benchmarking results is difficult because identifying the root causes of performance issues can be complex.
Performance Profiles: The Right Chip, Every Time
So, if benchmarking is critical to picking the right HPC hardware for your R&D tasks, what can an organization do? The answer is Rescale Performance Profiles.
Performance Profiles automates how organizations can immediately know which chip types are best for their needs.
With Performance Profiles, organizations can establish their own performance intelligence for their specific applications and computing tasks.
With performance profiles, you don’t have to rely on guesswork anymore when it comes to choosing the right core type or number of cores required.
Instead, with Performance Profiles, you can use its performance map to determine the optimal combination of hardware resources for your simulation.
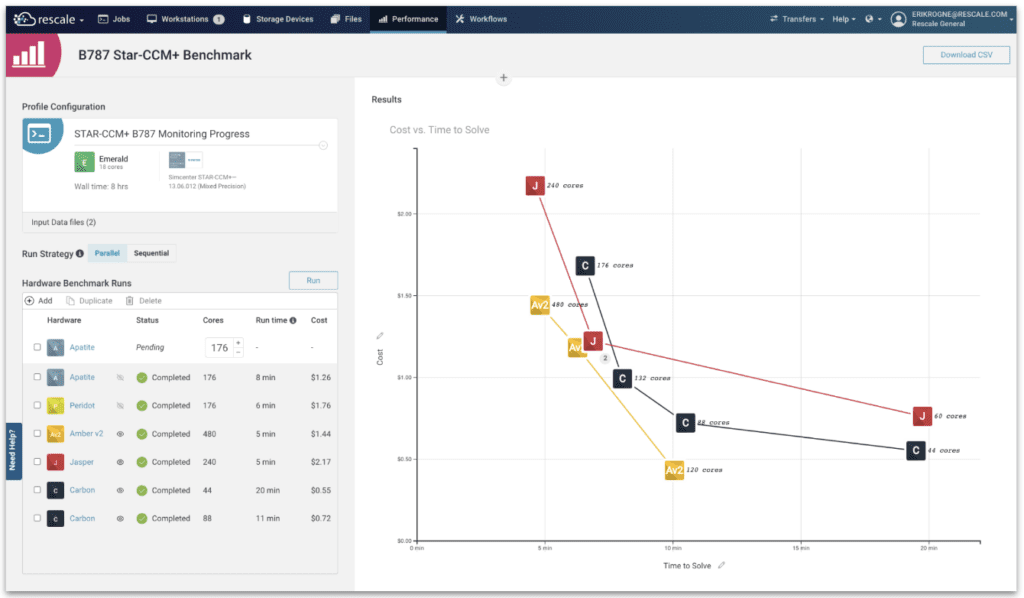
Performance Profiles provides you all the comparative data you need to understand the strengths and weaknesses of any hardware architecture. You can then make decisions that align to your strategic needs. It varies from customer to customer, as we saw in the use cases, and it really depends on the project at hand.
With Performance Profiles, you can make informed decisions based on actual benchmarks of your software and models, and it allows you to isolate variables among chip types, cluster size, application type, and the compute task. When you use Performance Profiles, you will know which HPC infrastructure actually performs for your R&D needs.
Many of our customers are already benefiting from the Rescale Performance Profiles, including Kairos Power, a clean energy start-up.
“Performance Profiles has been a very valuable capability for us,” says Brian Jackson, lead fluid dynamics engineer at Kairos. “Using Performance Profiles, our team discovered two hardware architectures that provided a 30% cost-to-speed improvement compared to the chip architectures we’ve been using. Moving forward, we will be utilizing these new core types, and we will continue to use this new Rescale capability to optimize performance and value.”
In this new era for digital R&D and high performance computing, the need to choose the right hardware architectures from cloud service providers is paramount. Making the right choice has major cost, performance, scale, and sustainability implications. Getting wrong could be costly while slowing innovation efforts. Pick wisely with Rescale Performance Profiles.
Would you like to learn more about how Rescale Performance Profiles can help your organization pick the right HPC architecture for its R&D needs?Watch the webinar “Optimizing Workload Cost and Performance in the Cloud” or learn more about Performance Profiles.






