

Key Tips for Managing High Performance Computing Systems
To successfully run HPC batch jobs, teams need to plan for scheduling, security, troubleshooting, and new cloud requirements
Rescale’s engineering team is dedicated to solving the complexities of managing high performance computing (HPC) systems in this era of hybrid and multi-cloud computing.
Fundamental to HPC for R&D is creating and managing a compute job to carry out a digital simulation or other kind of analysis. So a key area of focus for the Rescale engineering team is in automating many of the tasks required to successfully set up and run a simulation job or other big compute task.
In this second of my two-part blog post series (read part one: “Best Practices for Running HPC Batch Jobs”), I will discuss some of the broader management considerations for HPC batch jobs, including scheduling, security, troubleshooting, and the growing need to understand the specific requirements for cloud HPC.
Juggling HPC Batch Jobs
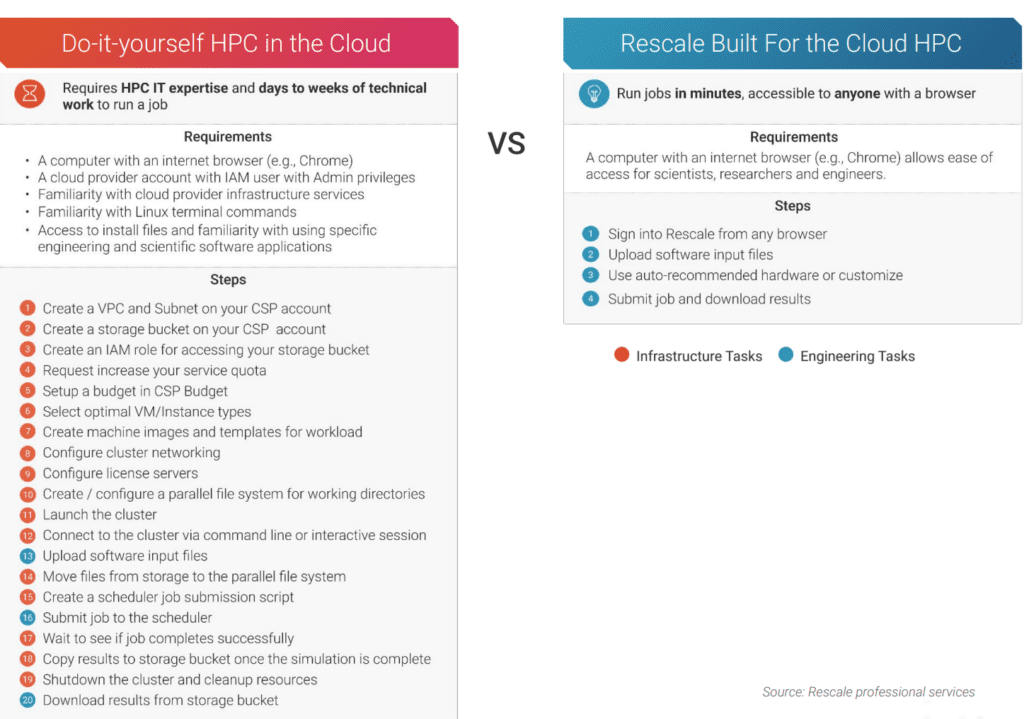
So to run batch processing, you need to set up your hardware, configure your network, and set up your software, whether in the cloud or on-premises. The processes are different, but they both require HPC expertise to do this all properly.
If you’re relatively familiar with the requirements of a particular batch job, you can typically get that all done in a few hours. But that’s not very realistic, because generally you’re not going to set up the same kind of batch job all the time. You’ll need to configure your compute environment to the specific application. Some tasks need great throughput, others need more parallelization, and so on.
Each HPC batch job is its own journey and requires addressing all hardware and software components to ensure the system is optimized for a given workload. This can mean starting from scratch to build a new type of HPC job, and it can require some lessons learned as you go along.
And then the next task is to set up a way to schedule all these batch jobs so people with higher priority jobs get their work done to meet their deadlines. And when dealing with an ongoing flow of HPC batch jobs, you will have a whole other level of configuration and provisioning that you have to do.
You also have to set up and support new versions of software, depending on how many different applications your R&D team uses. There’s significant maintenance and tuning for new applications to make sure those work like they should on your clustered hardware.
Ideally, you should also be refreshing your hardware periodically, whether in the cloud or on-premises. Every month there are new chips entering the market—there’s always a faster race car coming out. You might best benefit from a new Arm-based CPU to capture greater energy efficiency, or you might need pure parallelization power with GPUs. So that’s another thing you have to maintain and manage.
And then there’s just the ongoing maintenance of the system. Your scheduler’s going to get into a bad state sometimes and you have to go in and fix it. There’s a lot of maintenance pieces for both cloud-based and on-premises HPC even after you get everything set up and running the way you want.
The Costs of Faulty HPC Batch Jobs
If you don’t have your computing environment set up correctly, and you have faults in the system, this could result in your job not completing or the incorrect completion of your simulations or other analysis.
That has dramatic implications for whatever product you’re designing. If you’re getting bad data out of the system—especially if it’s bad data that’s not being flagged as an error—that could be a major issue for product development or regulatory compliance. You might build a product with a flaw that you didn’t realize it had.
Also, if there’s a failure and the software does call it out, you still lose all that work. Then you have to fix it and run your simulation again. And if it was a hardware fault, that is even more frustrating, because those kinds of errors can be very tricky to determine. Same with inter-node communications. Often, this leads to a team not finding the fault and rerunning a simulation and having it break again, cycling through an expensive and time-consuming troubleshooting process.
So, overall, if your HPC batch jobs are not set up correctly, you could end up with failed or inaccurate jobs that can cost time, money, or put your company at risk.
So an example of this was with one of our cloud provider partners. They didn’t have a consistent version of firmware set up on some of their InfiniBand switches. The networking library would randomly fail 48 hours into the batch job on that particular compute cluster.
That kind of firmware on a switch is pretty down in the stack. You can’t just look at the output of your application and discern that the fault is the network firmware. If you see those faults, you just know it failed. But a lot of times you have no idea where in the stack that is happening because of all the layers in an HPC system.
So there’s the problem of debugging, which can be very time-intensive. And maybe it isn’t a big deal if it just happens once, but if you have faults happening a few times a day for different workloads, that’s potentially a lot of simulation data that gets thrown out, along with a lot of time lost.
To ensure your HPC jobs run dependably (on-premises and the cloud), you really need a team of HPC experts for networking, systems administration, storage, data center management, and complex application maintenance. That’s a lot of technical resources to make sure your HPC systems are reliable and efficient, but that’s what is required for best practices HPC management if you do it yourself.
Security for Your R&D Data
Security, of course, is paramount for HPC. HPC systems typically house an organization’s most sensitive design and product information.
To manage security, it depends on how open you want your compute environment to be within your organization. You have to consider different types of user access, making sure that simulations and data are easily available to authorized users but ensuring they don’t migrate or “leak” to other parts of the organization or even outside the organization.
And that all has to be set up and maintained properly at the file system level or wherever you store your simulation data. So you need to know how to set up and administer a shared file system in a multi-user environment securely. That’s yet another skill set you need on your HPC team.
Multi-Cloud Management
The cloud, of course, addresses the biggest issue of traditional on-premises HPC data centers by providing nearly limitless on-demand high performance compute capacity. But multi-cloud HPC computing brings new and equally challenging technical complications.
Your HPC team really needs to know how to manage infrastructure-as-code on different cloud providers. The cloud providers vary quite a bit in how you need to interact with their interfaces and configurations.
Each cloud provider has a different way you orchestrate compute to build out a cluster to support a batch job and ensure low latency in the network fabric connecting nodes. There’s a whole different set of configurations for each CSP, in most cases.
A lot of this is because once you get into these considerations of low-latency networks, it is still a little bit niche. Especially because cloud HPC is so new, there are no strong standards across providers. Each cloud provider does things differently, because they’re still figuring out the complex world of HPC computing. So you have to know how to ask the cloud provider for the right configurations through their APIs or their SDKs to get optimal performance from the hardware.
For example, AWS provides something called EFA (elastic fabric adapter). That’s AWS’s in-house solution for low-latency networking on their computing infrastructure. Azure supports InfiniBand, which is an HPC industry standard type of technology, but it’s also virtualized.
So if you want to run HPC workloads on nboth AWS and Azure, you have to figure out how to provision the nodes in order to take best advantage of those different networking technologies. And then once you have connected your cluster of nodes for each fabric, you must know how to configure your MPI libraries to take advantage of each type of network.
Beyond the network fabric, you then also need to configuration other parts of the stack sitting above the hardware itself.
Then there’s the challenge of understanding which HPC cloud service provider in a region provides best cost-to-performance trade-offs. Even the time of the day can make a big difference in the cost to run an HPC job. And for HPC supercomputing clusters, availability is not a given with cloud providers, especially for specialized infrastructures.
You also need to carefully monitor all your cloud service accounts. It is surprisingly easy to lose track of cloud resources and only find them at the end of the month when you get the bill for stuff you forgot to shut down.
Having visibility and insights across the entire marketplace of HPC cloud services as well as your own infrastructure ecosystem is essential for being a savvy shopper and controlling cloud costs to get the most out of your HPC investments.
While setting up and managing HPC batch jobs is far from simple, getting it right is critical. Supercomputing is now essential for powering a growing array of powerful digital modeling and simulation software that is virtualizing scientific research and engineering. Such digital R&D is now becoming the foundation for the future of innovation. The companies that master high performance computing will have a growing advantage in their product development efforts.
Learn more about Rescale’s Intelligent Batch capabilities
Ensure all your high performance computing jobs are
set up the right way to run fast, efficiently, and dependably.






