CFD Tips for Running on Rescale

The way you compute computational fluid dynamics (CFD) problems on Rescale is very similar to running on your local environment. Some of these tips may be obvious to those familiar with CFD but here are a few suggestions, in no particular order, for running CFD on Rescale.
Garbage in, garbage out
It goes without saying that a good mesh could make or break your run. But before focusing on the mesh quality, one should always ensure that the job they wish to submit to Rescale should run end-to-end locally. Occasionally, there are users who use hundreds of cores expecting it to run for many days, only see it “finish” in a few seconds. We all make mistakes, but it is probably not productive to repeatedly make small mistakes that have a big cost. Executing a small case of what you will be running locally will save your time and your wallet.
Watch your step
The Rescale platform has a Live Tailing feature that allows you to view all the files while the computation is in progress. It is helpful to know if there are errors or the progress it has made. However, in CFD you are also interested in knowing the residuals and certain values as the simulation progresses. One way to monitor your iteration is writing out the plot as image file(s).
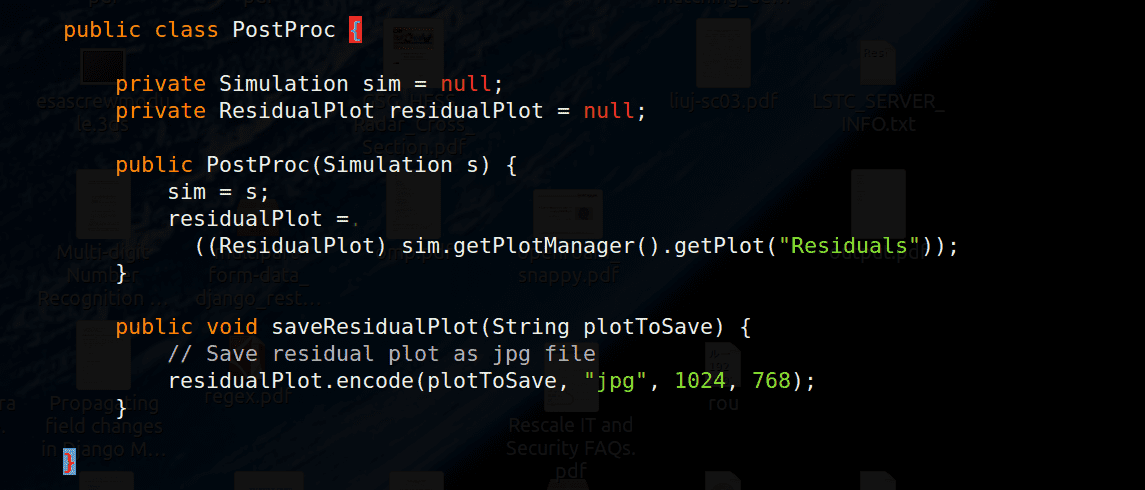
The figure below is an example of a residual output from STAR-CCM+ running a steady-state problem.
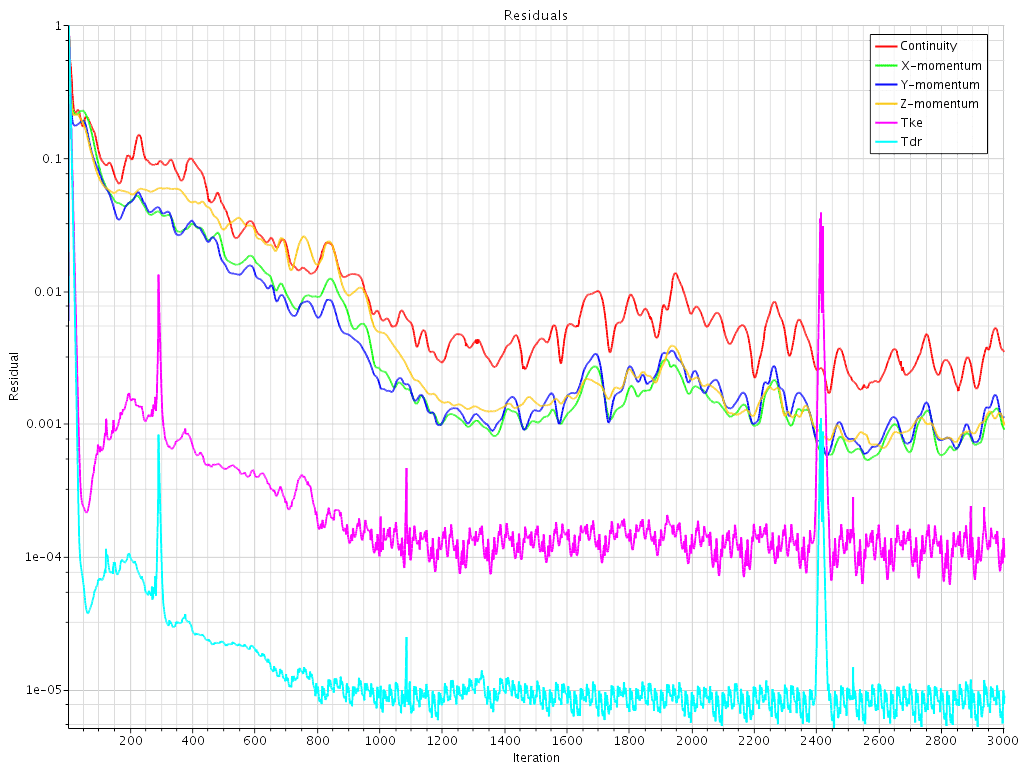
This residual plot is written out as a jpeg file with the code shown below. You will probably need to make changes to this code to integrate with your code.
Alternatively, you could plot your own figure with the built-in-tools. For software that writes the residual log as ASCII file, one method to plot the residual is by using gnuplot.

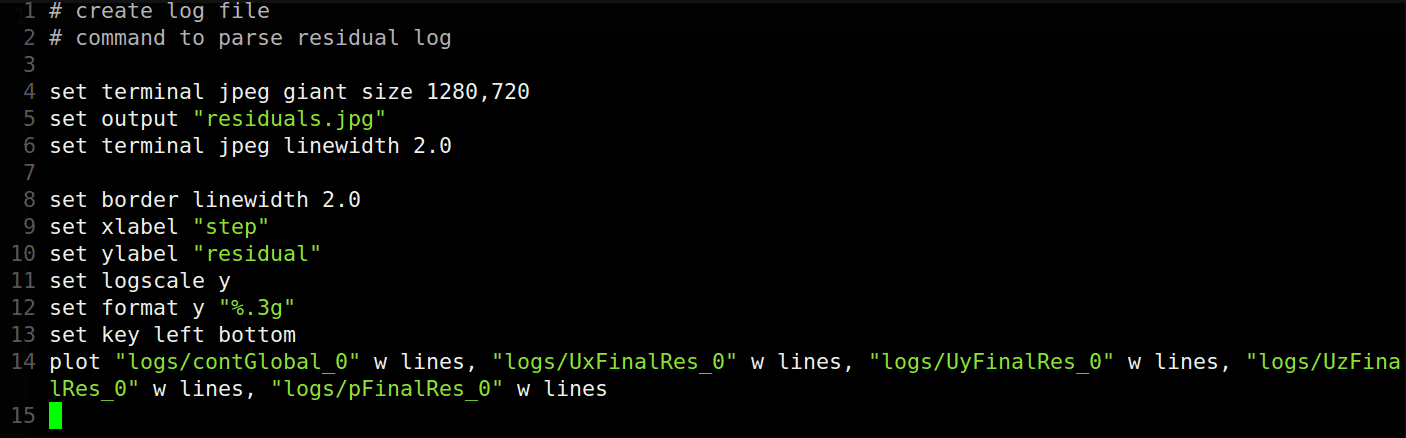
Below is a code for gnuplot to write a jpeg image file of the residual plot. One should modify the example code below to suit their own CFD software output.
Guide your run
Sometimes it is necessary to intervene during the computation and change some settings, such as relaxation factor, save interval, or solver parameter. One can ssh into the compute cluster having set an ssh key in their account settings. For details, see here. Intervention may help save a run if one identifies bad parameter choice(s), thus avoiding submitting a new job. Of course to know if you need to intervene, you will need to be watching your step.
One could also run a non-graphical interactive session if the CFD software supports it. Below is a screenshot of the terminal session of ANSYS Fluent.

For hoarders – package files
Result files are precious, especially with all the work that went into just getting it to run. Some software writes out many files of relatively small size (less than few MB). With thousands of these files, the data transfer time after the computation completes can become a large portion of the job duration. This data transfer applies both to when the results are transferred to the storage space as well as when you download the results to your local workstation at a later time. The large number of files and large file size might not be avoidable in CFD, however, packing up many files and writing in binary can mitigate the time spent on going for a coffee break.
As an example, OpenFOAM writes all its field solutions in separate files (e.g U, p, T, … etc.). This is convenient for post-processing or using the output for another input, but creates many files. One could write in binary and limit the write interval in the system/controlDict setting. Additionally, packaging up the results with tar or zip is strongly advised, but then again… coffee might be calling.
Looking into the Rescale cloud
Result files too large for your bandwidth aren’t a problem anymore. You can view them without downloading the results. Simply start a remote desktop and load your job that is in progress or a completed job. Shown below is a Windows remote desktop session (Linux is also available).
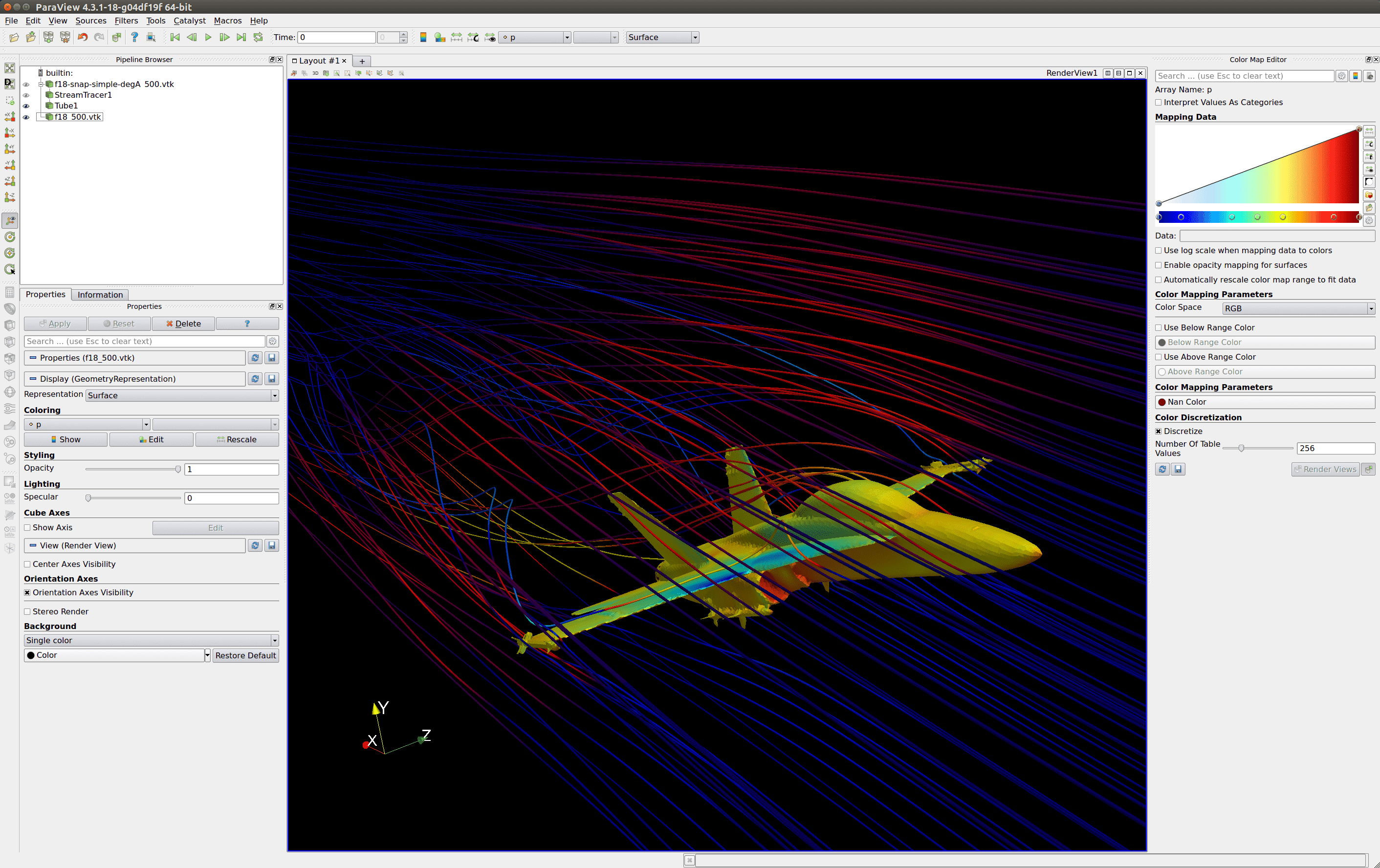
Another option is to start ParaView on the job cluster and use ParaView server to view the results. Compared to the remote desktop, this is limited to the operations of ParaView. If all you wish to do is view and extract certain data, this may be all you need. For more details see here.