In this guide we will show you some common sources of errors encountered by users running jobs in batch on the Rescale platform. We will try to show you how to diagnose some of these errors. We will also discuss ways on how to avoid and correct them.
Job Status page
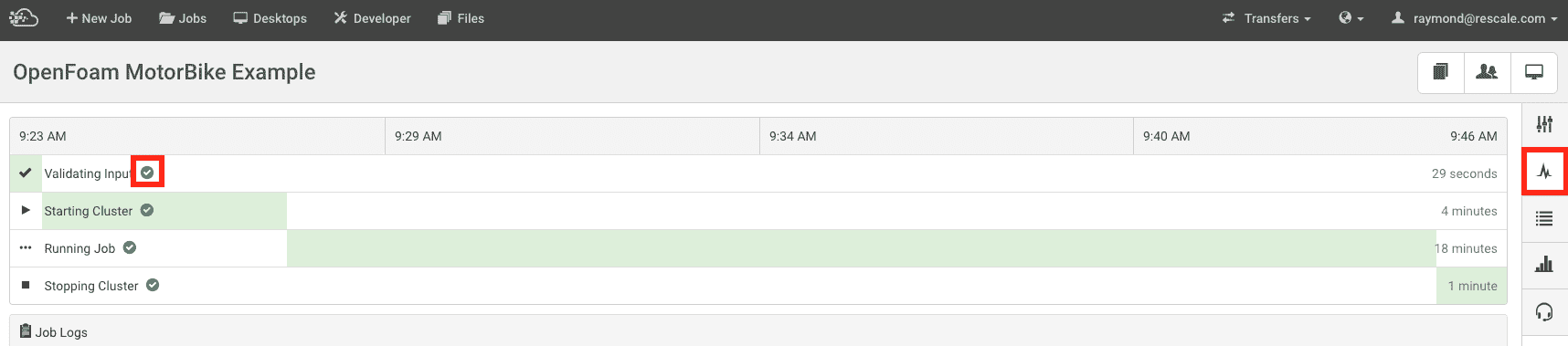
Review the output on the Job Status page
Examine the job history on the Gantt chart
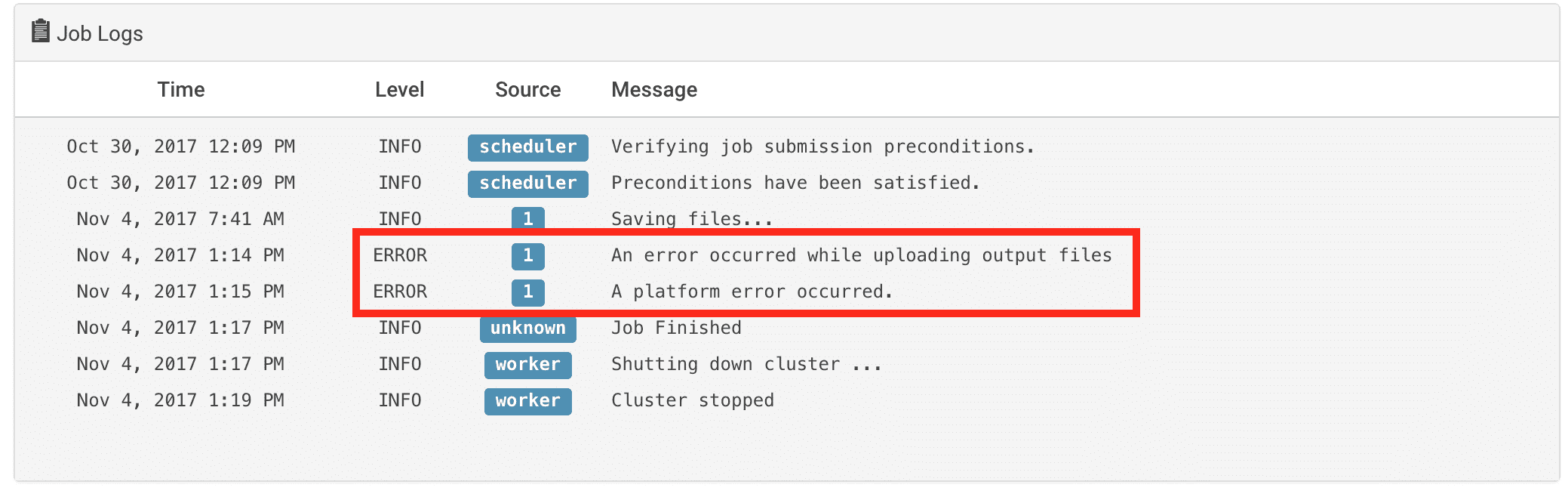
Does the command properly pass the validationValidation is the act of ensuring that a product, system, or... More step (Validating Input) with a green check? Are there error messages present in the Job Logs section?
Are there error messages present in the Job Logs section?
Results page
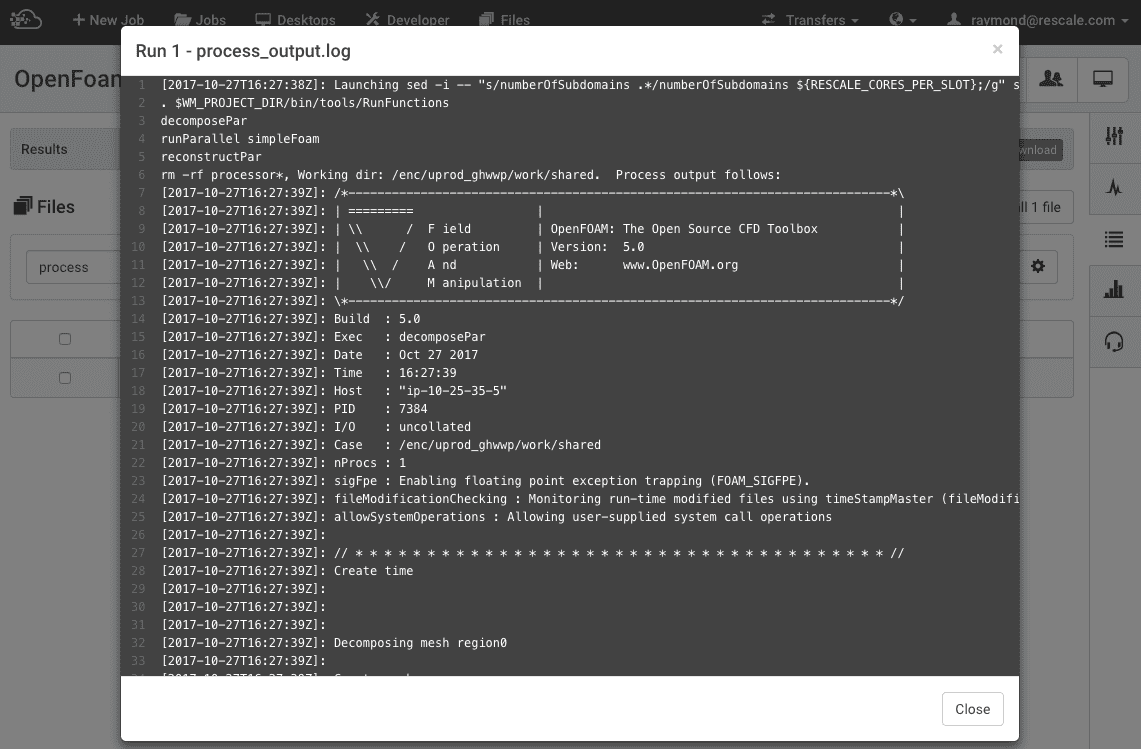
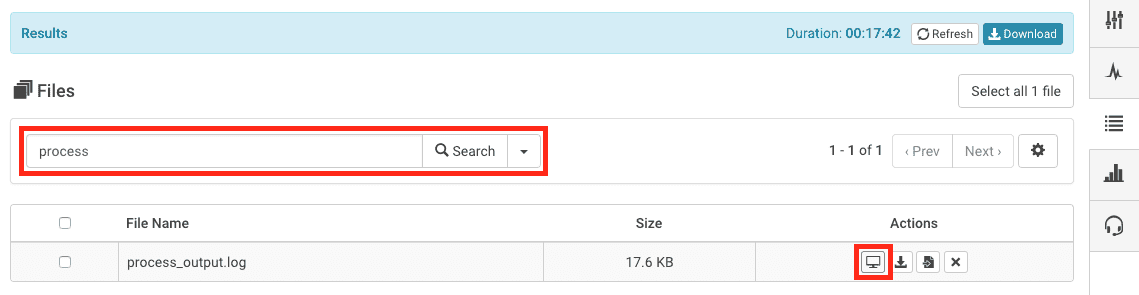
process_output.log
The first step we would always suggest for every job, successful or otherwise is to review the process_output.log file. This file logs the standard output from the software analysis method you are running. It will also log any potential error messages.
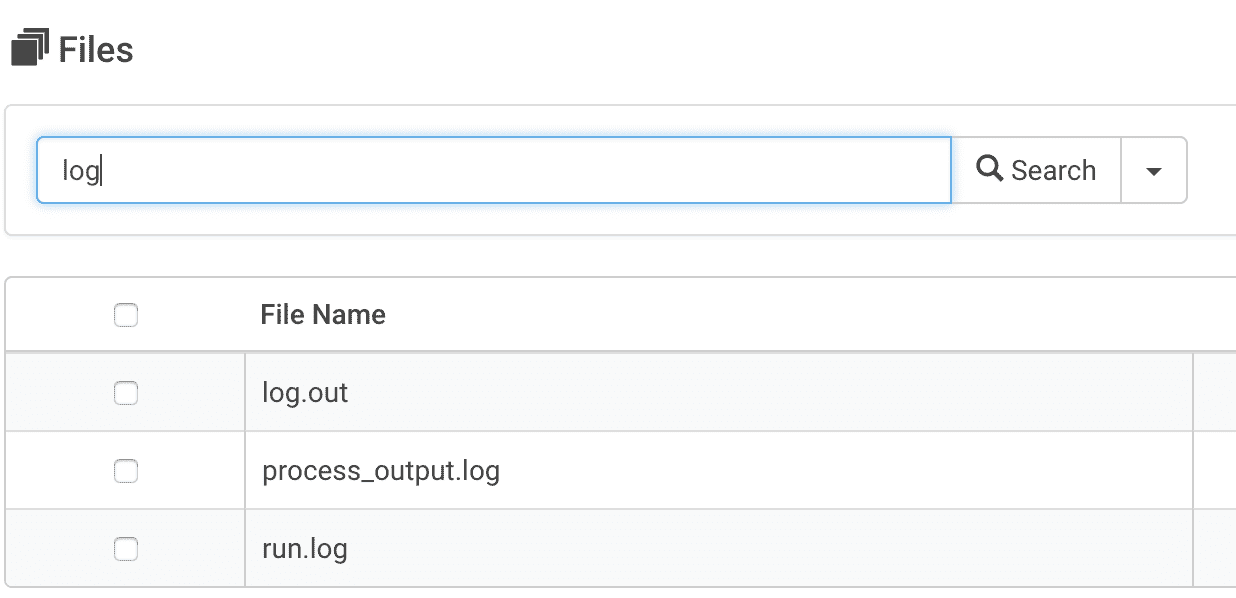
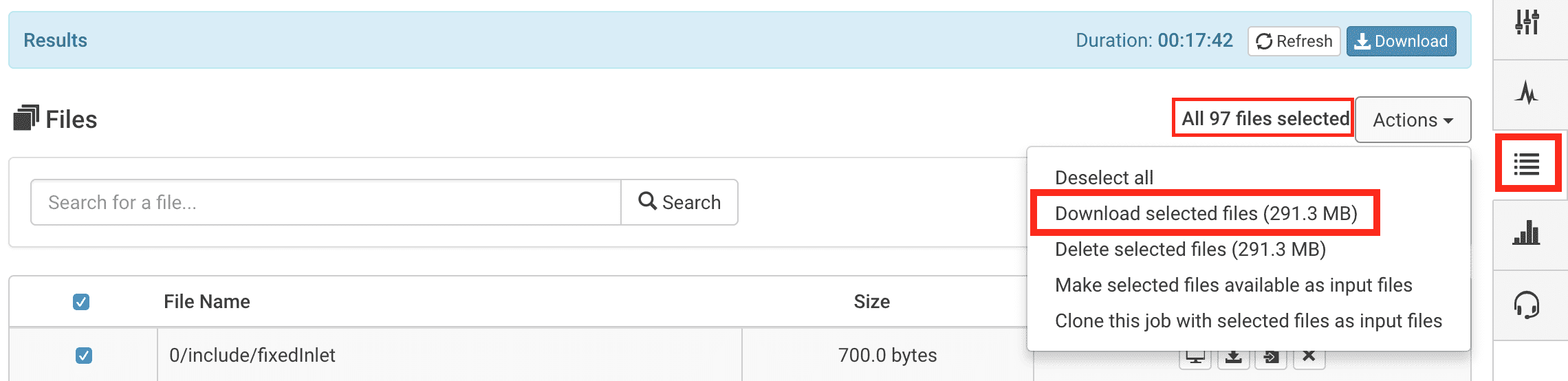
To find the process_output.log file go to the Job Results page
Query for the file in the search bar
Usually log or process is a sufficient search term
View the process_output.log file using the screen icon in the Actions column
If the file is too large, you may first need to download the file before viewing it in a text editor
Carefully review this log file and look for warning or error messages
Most of the time, the error can be identified here
Exit Codes
One key field to look for is the “exit code” at the end of the process_output.log file. If an analysis method runs smoothly and exits cleanly without posting any error messages it should produce:
Exit with code 0
While a job may complete with code 0, this simply means that the process ran without producing any errors. This of course does not guarantee that the job ran as you intended. When the program does encounter an explicit system error (i.e. out of memory, corean individual processing unit within a multicore processor o... More dump, out of disk space, etc), the process will produce a non-zero exit code. Common exit codes you may encounter:
Exit Code
Meaning
1
Catchall for general errors
2
Misuse of shell built-ins
126
Command invoked cannot execute
127
Command not found
128
Invalid argument to exit
128+n
Fatal error signal “n”
130
Script terminated by Ctrl-C
137
Undetermined exit mode, including explicit termination of the process or out of memory
255*
Exit status out of range
These error codes, of course, are not the most instructive, however, they provide a starting point for debugging.
Basic Debugging Steps
While there are a wide variety of failure mechanisms, some of the most common issues as well as steps to diagnose and avoid them are listed below.
Missing input files
Ensure that all of the required files have been included in the job either individually or in a compressed (zip, tarball, etc) input file deck.
Incorrect file paths
Ensure that the compressed input file deck will expand to the proper directory paths
Use relative file paths in scripts, input files and other job definitions
Rescale will execute the software Command(s) indicated on the Software Settings page in the same working directory where the compressed files will be unpacked
The Rescale platform will assume that the prepared input files are packaged at the top directory level
zip/tar/etc the input files at the directory level where the command will be executed
Or, if a case subdirectory is used (i.e. run01_configB), ensure that you preface the analysis software command with the proper change in directory such as: cd run01_configB && run_analysis
Note that this is not the preferred workflow on the Rescale platform
Multi-node jobs that require access to a common file system
For most analysis methods where the head process handles the file I/O and communication with the worker process, Rescale by default places user specified input files into ~/work. Some methods, however, launch worker processes on nodes that also require access to a shared file system.
On the Rescale platform, the ~/work/shared directory is NFS mounted to all of the compute nodes in your job
Rescale has identified most of these analysis methods and by default start jobs in the ~/work/shared directory
However, occasionally, due to a runtime customization or option, the worker processes running on the nodes will require access to input files, load runtime libraries, or writing output files
The Command on the Software Settings page should be prepended with move and change directory commands:
mv * shared
cd shared
<run_analysis>
Error reading input files
Ensure that the input files are properly constructed as expected by your analysis software
Ensure that the proper software Version is selected on the “Software Settings” dropdown page
Ensure that text input files are in the proper format
Batch compute nodes are generally Linux machines. Depending on the type of text editor you use, sometimes end of line/end of file characters are encoded differently
Often times Windows text editors will result in files with the ^M newline character that Linux does not use
To replace this using a text editor such as VI/VIM you can replace these characters with the following command: :%s/^M$//
Note: ^M is entered as ctrl-V and ctrl-M
Examine other log files from your analysis method
While the Rescale Platform will output standard output messages to process_output.log, some analysis methods will print critical information to other log files
These output files will usually have file extensions of ‘log’, ‘out’, ‘live’, or ‘dat’, but may vary depending on the analysis method. Please refer to the software vendor’s documentation
These log files will also generally be ASCII text files, so you can view them using the small screen icon in the right hand column next to the filename
As with the process_output.log file, if it is too large, download them to your local workstationA workstation is a powerful computer system designed for pro... More and view them using a text editor
Missing library files
Ensure that the process has proper access and path definitions to any custom library files used in the job.
Rescale Support may have to install additional libraries for your application.
Please notify Rescale Support if you encounter a message like this
Out of system resources
Check that your simulationSimulation is experimentation, testing scenarios, and making... More process has sufficient physical memory and storage during runtime
Some codes will change their memory footprint size during runtime depending on the analysis, so sufficient memory at start-up may not persist
Some codes will also generate a large amount of scratch data files that could bloat the storage footprint beyond that of the final output files
Refer to the “Cluster Status” on the bottom of the Job Status page for monitors of free memory and disk space
Reduce the size of your mesh/simulation to see if the job can run successfully
Run on more cores and/or nodes
Select specialty core-types with more physical memory or storage
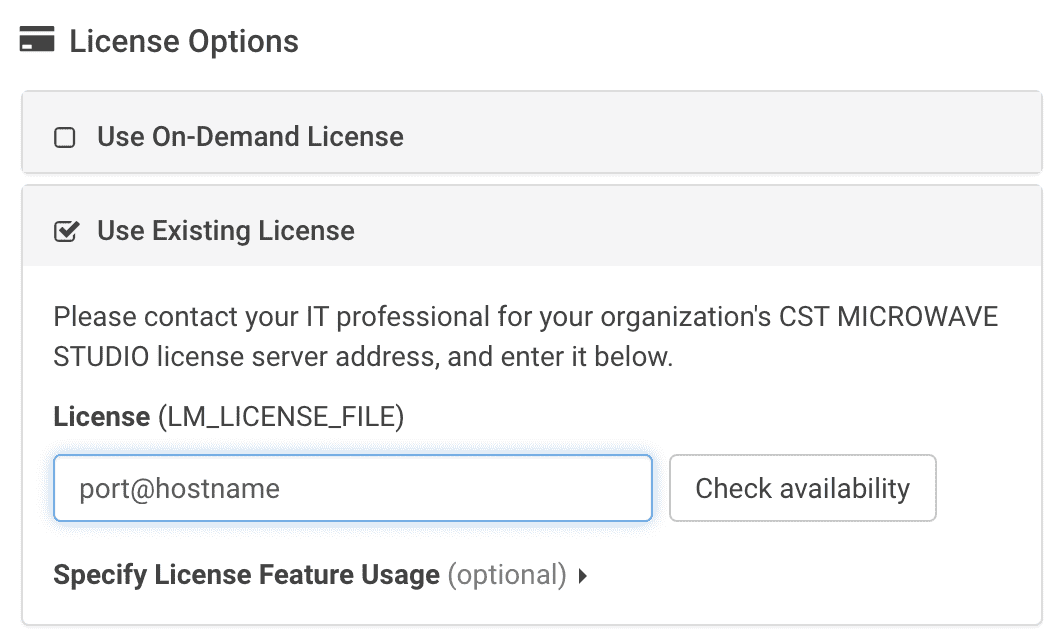
Proper license access
Ensure that your license settings on the Software Settings page are properly defined. Generally, these are in the format of port@hostname.
Ensure that you are checking out features on your license file, as seen from the process_output.log
Check if the right options to check out the features are used with command you are trying to execute.
If you are the person responsible for your license servera server is a computer program that provides services to oth... More:
Check that your license has not expired
Check that your license server is up and has network access
Before diving in with a production sized run, set up a small test case that exercises your workflow
Check that your pre- and post-processing steps are properly integrated into your Analysis Options > Command
Run a test job interactively
Replace the existing Command with sleep 3600
ssh into the compute nodeIn traditional computing, a node is an object on a network. ... More once it starts
Change into the appropriate directory for your analysis method (~/work or ~/work/shared)
Attempt to launch the job interactively
Record all of the commands that produce a successful outcome
Modify your Command(s) accordingly
The Command input window will accept line breaks, ; or && marks to separate commands
Note: commands separated by && will only execute if the previous completes with an code 0, while those following ; will always execute after the previous
If these common debugging steps still do not resolve your problems, please contact and share your job with Rescale Support.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies. Do not sell my personal information.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
AWSALBCORS
7 days
This cookie is managed by Amazon Web Services and is used for load balancing.
cookielawinfo-checkbox-advertisement
1 year
Set by the GDPR Cookie Consent plugin, this cookie is used to record the user consent for the cookies in the "Advertisement" category .
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Cookie
Duration
Description
__cf_bm
30 minutes
This cookie, set by Cloudflare, is used to support Cloudflare Bot Management.
bcookie
2 years
LinkedIn sets this cookie from LinkedIn share buttons and ad tags to recognize browser ID.
lang
session
LinkedIn sets this cookie to remember a user's language setting.
lidc
1 day
LinkedIn sets the lidc cookie to facilitate data center selection.
player
1 year
Vimeo uses this cookie to save the user's preferences when playing embedded videos from Vimeo.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
AWSALB
7 days
AWSALB is an application load balancer cookie set by Amazon Web Services to map the session to the target.
sync_active
never
This cookie is set by Vimeo and contains data on the visitor's video-content preferences, so that the website remembers parameters such as preferred volume or video quality.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
_ga
2 years
The _ga cookie, installed by Google Analytics, calculates visitor, session and campaign data and also keeps track of site usage for the site's analytics report. The cookie stores information anonymously and assigns a randomly generated number to recognize unique visitors.
_gat_UA-32985745-1
1 minute
A variation of the _gat cookie set by Google Analytics and Google Tag Manager to allow website owners to track visitor behaviour and measure site performance. The pattern element in the name contains the unique identity number of the account or website it relates to.
_gcl_au
3 months
Provided by Google Tag Manager to experiment advertisement efficiency of websites using their services.
_gid
1 day
Installed by Google Analytics, _gid cookie stores information on how visitors use a website, while also creating an analytics report of the website's performance. Some of the data that are collected include the number of visitors, their source, and the pages they visit anonymously.
CONSENT
2 years
YouTube sets this cookie via embedded youtube-videos and registers anonymous statistical data.
utm_campaign
past
Google Ad Services sets this cookie to store session campaign value if present.
utm_content
past
This cookie is used for storing the session content value if present.
utm_source
past
This cookie is used to record from where the visitor came to the website orginally. This information is used by the website operator to know the efficiency of their marketing.
utm_term
past
This cookie is used to record from where the visitor came to the website orginally. This information is used by the website operator to know the efficiency of their marketing.
vuid
2 years
Vimeo installs this cookie to collect tracking information by setting a unique ID to embed videos to the website.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
_fbp
3 months
This cookie is set by Facebook to display advertisements when either on Facebook or on a digital platform powered by Facebook advertising, after visiting the website.
_mkto_trk
2 years
This cookie, provided by Marketo, has information (such as a unique user ID) that is used to track the user's site usage. The cookies set by Marketo are readable only by Marketo.
fr
3 months
Facebook sets this cookie to show relevant advertisements to users by tracking user behaviour across the web, on sites that have Facebook pixel or Facebook social plugin.
IDE
1 year 24 days
Google DoubleClick IDE cookies are used to store information about how the user uses the website to present them with relevant ads and according to the user profile.
personalization_id
2 years
Twitter sets this cookie to integrate and share features for social media and also store information about how the user uses the website, for tracking and targeting.
test_cookie
15 minutes
The test_cookie is set by doubleclick.net and is used to determine if the user's browser supports cookies.
utm_medium
past
This cookie is used to record from where the visitor came to the website orginally. This information is used by the website operator to know the efficiency of their marketing.
VISITOR_INFO1_LIVE
5 months 27 days
A cookie set by YouTube to measure bandwidth that determines whether the user gets the new or old player interface.
YSC
session
YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
yt-remote-connected-devices
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt-remote-device-id
never
YouTube sets this cookie to store the video preferences of the user using embedded YouTube video.
yt.innertube::nextId
never
This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen.
yt.innertube::requests
never
This cookie, set by YouTube, registers a unique ID to store data on what videos from YouTube the user has seen.

 If the file is too large, you may first need to download the file before viewing it in a text editor
If the file is too large, you may first need to download the file before viewing it in a text editor