
High Throughput Computing (HTC)
Please note that this feature is currently in beta and not enabled by default. Please contact your organization’s Solution Architect or Account Executive to enable access.
Overview
Rescale High Throughput Computing (HTC) is an API-based Rescale product for running a large number (e.g., hundreds to millions) of concurrent small and decoupled jobs (e.g., single-digit cores to single-digit instances and no multi-node MPI).
High Performance Computing (HPC) uses clusters to solve advanced computational tasks. Large tasks are split into subtasks and are solved, in parallel, on a multi-node cluster. An HPCThe use of parallel processing for running advanced applicat... More clusterA computing cluster consists of a set of loosely or tightly ... More is a set of homogeneous, interconnected machines (nodes). Each node runs a copy of a pre-installed program working on data representing part of a task. To arrive at a global solution, nodes in an HPC cluster need to communicate with each other, and therefore need to be in proximity (same data center, same rack). HPC computations are tightly coupled and fail if individual nodes fail.
The aim of HPC is to reduce time-to-result of an individual computation and maximize operations per second. The lifetime of an on-demand, cloud HPC cluster is as short as possible.
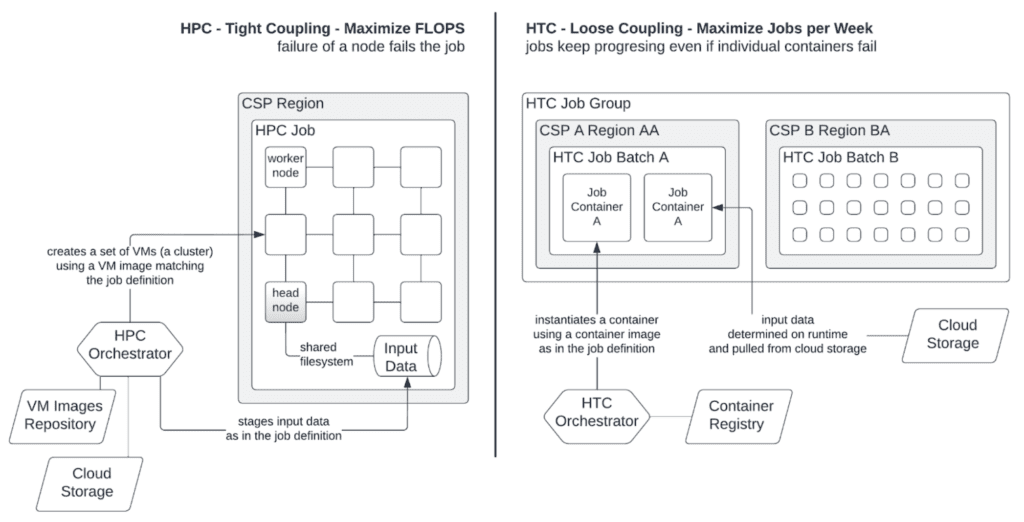
High Throughput Computing (HTC)Unlike High-Performance Computing (HPC), which focuses on ex... More uses multiple nodes over long periods of time to solve multiple computational jobs. Each job runs a program included in a container image stored in a registry. Similar to HPC, compute work is split into many jobs. Unlike HPC, HTC jobs for a single user’s workloadWorkload refers to the amount and type of computing tasks or... More can easily be on the order of 1,000s to 10,000s.
Organization of Compute in HTC
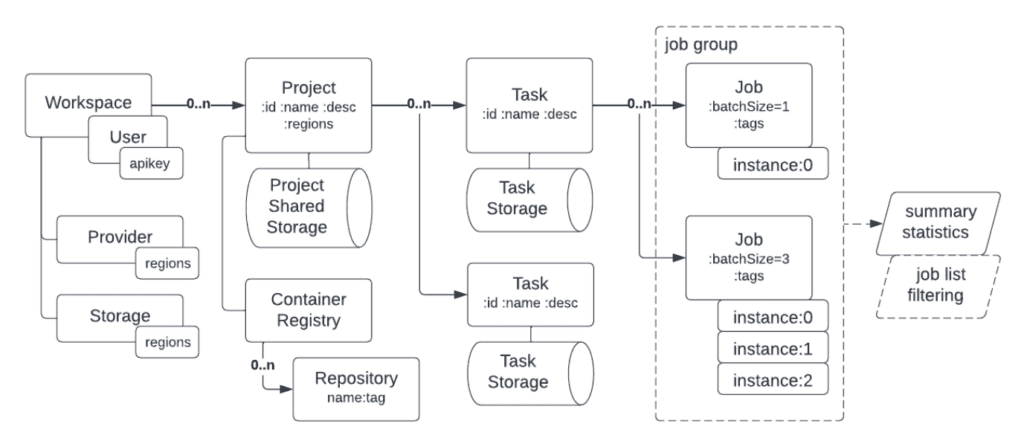
HTC jobs are organized in a hierarchical structure, within a workspaceWorkspaces allow rescale customers to create dedicated teams... More using HTC, the hierarchy is shown in the diagram below and is as follows:
Project: A workspace can contain one or more projects. While not a requirement, projects generally are semi-long-lived entities to organize a various instantiations of one or more users’ workloads.
Task: A project can contain one or more tasks. A task is generally expected to be ephemeral and encapsulates one “run” of a user’s workload.
Job: A task contains many jobs. The job is the basic unit of work. Jobs are independent of each other.
The aim of HTC is to maximize the number of completed jobs in a week or a month, rather than optimize the amount of time a single job takes. This is the “throughput” part of HTC.
Organization of data in HTC
Each project has “shared” storage that all tasks can access. Each task also has a storage allocated that is dedicated to just the task. Jobs within a given task can only access data in that task’s storage and not storage associated with other tasks. Likewise, jobs in a given project can only access shared data in the project its task resides in.
In general, users tend to use project storage for input files shared across a task. Task storage is generally used for task-specific input files and output files from the jobs in that task.
Both project and task storage are currently backed by object storageObject Storage is a computer data storage architecture that ... More. Object storage in multiple cloud providers and regions is made available through the HTC API so that data can be co-located near the compute that consumes and produces it.
The Rescale HTC API
The following diagram represents all resources exposed by the Rescale HTC API. The subsequent sections describe these in more detail. The full beta HTC API documentation can be found here.
Accessing the HTC API
Access to the HTC API must be first enabled on a given Rescale Workspace by a Rescale Solution Architect. Once access has been granted, a Rescale API key must be used to authenticate, see here to generate or access an API key in your HTC-enabled workspace.
Authenticating with the HTC API
This Rescale API key is an API key used to access HTC APIs on the Rescale Platform via the Rescale Public API. With this key, you can then generate an HTC API User Bearer Token, this bearer token is used to access the rest of the HTC APIs. You specify the Rescale API key in the Authorization Header of an HTTPS request in the following manner to obtain a bearer token via the /auth/token/ endpoint:
curl -H “Authorization: Token <Rescale API KEY>” https://htc.rescale.com/api/v1/auth/token
In the payload, a temporary bearer tokenValue is provided. This token is used for all subsequent HTC API access. Each bearer token expires 6 hours after issue so new bearer tokens must be retrieved with the Rescale API key upon expiry.
To use the bearer token to authenticate HTC API calls, you designate it in the header:
curl -H “Authorization: Bearer <Bearer token>” https://htc.rescale.com/api/v1/htc/…
Managing Projects
HTC projects are used to manage compute and data across multiple workloads. Projects can be created, updated with new available regions and limits, and can receive files to the project store. The various project-related API endpoints are documented here.
Projects are created by workspace administrators and generally cannot be managed by HTC users with administrative access.
Project Container Registries
Each project has its own containerA package of self-sustaining application and operating syste... More registry. The images in the project container registry are accessed by all HTC jobs running in tasks in that project. The container registry is effectively the application catalog available to that project.
A project can have multiple repositories where each repository can contain multiple container images, as long as they have unique tags. Jobs specify the repository name and any desired image tags in the definition to designate what container should run for a job.
It is currently not possible to share container images in registries across projects.
Managing Tasks
An HTC task generally holds a single user’s workload(s). Any user within a workspace can create tasks in a particular project as documented here.
Job Submission and Management
HTC jobs are submitted in “batches” to a task using this API endpoint. Each job batch consists of the following high level components:
jobName: The name shared by this batch of jobs
batchSize: The number of jobs in this batch. All jobs in a batch share the same job definition
htcJobDefinition: All parameters that are shared across jobs within this batch, these consist of the following:
imageName: The container image to use, this can also include a tag for a given container image repository
maxVcpus: The maximum number of vCPUs expected to be used by each job
maxMemory: The maximum MiBs of DRAM memory that each job will be able to use
maxDiskGiB: The maximum GiBs of ephemeral disk space each job will be able to use
commands: The command to run when the container is executed
execTimeoutSeconds: The maximum number of seconds a container will be allowed to run before it is forcibly terminated
architecture: The CPU architecture used to run the job, current options are X86x86 is a widely used computer architecture and instruction s... More or AARCH64
priority: Whether the jobs should run as on-demand priority or on-demand economy